JVM之_8_调优实战
前言
Github:https://github.com/HealerJean
1、虚拟机参数怎么配置
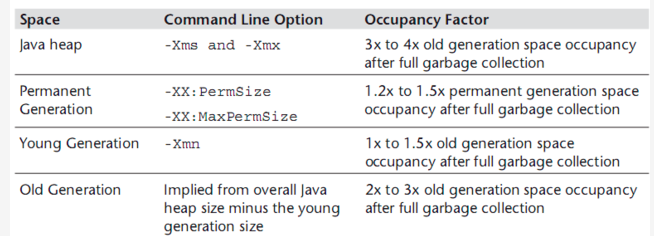
1、Java 整个堆大小设置,Xmx 和 Xms 设置为老年代存活对象的 3-4 倍,即 FullGC 之后的老年代内存占用的 3 - 4 倍
2、年轻代 Xmn 的设置为老年代存活对象的1-1.5倍。
3、老年代的内存大小设置为老年代存活对象的2-3倍。
4、永久代 PermSize 和 MaxPermSize设置为老年代存活对象的1.2-1.5倍。
举例:老年代存活 1M
堆区年轻代 = 1M * 1.5 (1- 1.5 倍)= Xmx : 1.5M
堆区老年代 · 1M * 3 (2-3 倍) = 3M
堆区 = 1M * 4( 3 - 4 倍) = Xmx 和 Xms : 4M 调整为 1.5M+ 3M = 4.5M
1.1、 确定老年代运行大小
注意:
CMSGC是会造成 2 次的FullGC 次数增加,因为它会两次STW`,
1.1.1、GC 日志 (稳妥方式 )
JVM参数中添加GC日志,GC日志中会记录每次FullGC之后各代的内存大小,观察老年代GC之后的空间大小。可观察一段时间内(比如2天)的FullGC之后的内存情况,根据多次的FullGC之后的老年代的空间大小数据来预估FullGC之后老年代的存活对象大小(可根据多次FullGC之后的内存大小取平均值)
1.1.2、强制触发FULL GC
运行一段时间后,考虑强制触发full gc ,这样就知道稳定运行中老年代的大小,这样获取的数据也必将准确(如果不使用用这个命令,直接用后面
jstat gc查看到的老年代内存是不准的)注意:强制触发
FullGC,会造成线上服务停顿(STW),要谨慎,建议的操作方式为,在强制FullGC前先把服务节点摘除,FullGC之后再将服务挂回可用节点,对外提供服务 ,然后在不同时间段触发FullGC,根据多次FullGC之后的老年代内存情况来预估FullGC之后的老年代存活对象大小
触发Full GC 的方法
` jmap -dump:live,format=b,file=heap.tdump
jmap -histo:live <pid> 打印每个class的实例数目,内存占用,类全名信息. live 子参数加上后,只统计活的对象数量. 此时会触发FullGC
1.2、查看运行情况
1.2.1、jstat:看内存分配
刚上线的新服务,不知道该设置多大的内存的时候,可以先多设置一点内存,然后根据GC之后的情况来进行分析。
./jstat -gc 12566 1000 100
[work@vm10-123-3-2 bin]$ ./jstat -gc 12566 1000 100
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
26176.0 26176.0 296.0 0.0 209792.0 169909.3 786432.0 149381.5 116424.0 109474.4 13108.0 11988.5 340 8.121 6 0.570 8.691
26176.0 26176.0 296.0 0.0 209792.0 169909.3 786432.0 149381.5 116424.0 109474.4 13108.0 11988.5 340 8.121 6 0.570 8.691
26176.0 26176.0 296.0 0.0 209792.0 169909.3 786432.0 149381.5 116424.0 109474.4 13108.0 11988.5 340 8.121 6 0.570 8.691
26176.0 26176.0 296.0 0.0 209792.0 169909.3 786432.0 149381.5 116424.0 109474.4 13108.0 11988.5 340 8.121 6 0.570 8.691
26176.0 26176.0 296.0 0.0 209792.0 169922.4 786432.0 149381.5 116424.0 109474.4 13108.0 11988.5 340 8.121 6 0.570 8.691

年轻代GC 平均耗时:8.121s / 340 = 0.023秒 = 23毫秒
老年代GC 平均耗时 0.57/6 =0.095秒 = 95毫秒
查看年轻代GC频率,可以再线上直接使用该命令进行推导 ,很简单。看看多长时间GC一次
1.2.2、jmap:查看堆内存情况
./jmap -heap 12566
[work@vm10-123-3-2 bin]$ ./jmap -heap 12566
Attaching to process ID 12566, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.202-b08
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1073741824 (1024.0MB)
NewSize = 268435456 (256.0MB)
MaxNewSize = 268435456 (256.0MB)
OldSize = 805306368 (768.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space): //新生代区域分配情况
capacity = 241631232 (230.4375MB)
used = 26757744 (25.518173217773438MB)
free = 214873488 (204.91932678222656MB)
11.073793639391782% used
Eden Space:
capacity = 214827008 (204.875MB)
used = 26537600 (25.3082275390625MB)
free = 188289408 (179.5667724609375MB)
12.353009170988408% used
From Space: //其中一个Survivor区域分配情况
capacity = 26804224 (25.5625MB)
used = 220144 (0.2099456787109375MB)
free = 26584080 (25.352554321289062MB)
0.8213033886002445% used
To Space: //另一个Survivor区域分配情况
capacity = 26804224 (25.5625MB)
used = 0 (0.0MB)
free = 26804224 (25.5625MB)
0.0% used
concurrent mark-sweep generation: //老生代区域分配情况
capacity = 805306368 (768.0MB)
used = 152967632 (145.8813018798828MB)
free = 652338736 (622.1186981201172MB)
18.99496118227641% used
42801 interned Strings occupying 4704176 bytes.
老年代占用内存 145M 左右,按照整个堆大小是老年代的3-4倍计算的话, 设置各代内存的情况如下
-Xms=640m -Xmx=640m Xmn=256m
老年代大小为 640 - 256 = 384 384/145 = 2.6倍 符号推荐情况
测试成果 :运行7.1.1命令,查看gc频率是否正常,满足需要
结果分析 :整体的 GC 耗时减少。但 GC 频率比之前的2G时的要多了一些。
1.3、总结:
在内存比较小的机器上,可以按照上述的方式来进行内存的调优, 找到一个在GC频率和GC耗时上都可接受的一个内存设置,可以用较小的内存满足当前的服务需要。但内存比较大的机器上,可以相对给服务多增加一点内存,可以减少GC的频率,GC的耗时相应会增加一些。

