项目经验_之_问题排查
前言
Github:https://github.com/HealerJean
一、基本介绍
1、Java 所处生态

2、Java 服务常见问题

3、基于 Linux 命令排查

二、CPU 问题排查
1、CPU 问题原因
⬤ 单机
cpu异常可能受宿主机影响。⬤ 整个服务集群
cpu异常应该是自身程序逻辑有问题原因包括业务逻辑问题(死循环)、频繁
gc以及上下文切换过多,而最常见的往往是业务逻辑(或者框架逻辑)导致的。
2.1.1、宿主机影响
单机情况可能出现,大量节点同时受宿主影响可能性较小。
2.1.2、程序问题
1、
top命令查看耗时最大的进程;2、
ps命令查看耗时最大的进程;3、线程
id,转换成16进制数;4、
jstack打印命令栈,查看对应的进场在做什么事情;因为
cpu使用率是时间段内的统计值,jstack是一个瞬时堆栈只记录瞬时状态,两个根本不是一个维度的事,如果完全按照上面那一套步骤做的话碰到这种情况就傻眼了,冥思苦想半天却不得其解,根本不明白为什么这种代码会导致高cpu。针对可能出现的这种情况,实际排查问题的时候
jstack建议打印5次至少3次,根据多次的堆栈内容,再结合相关代码进行分析,定位高cpu出现的原因,高cpu可能是代码段中某个bug导致的而不是堆栈打印出来的那几行导致的。
a、top:命令确定内存情况,找到 CPU 过高的 Java 程序
1、top :命令
top
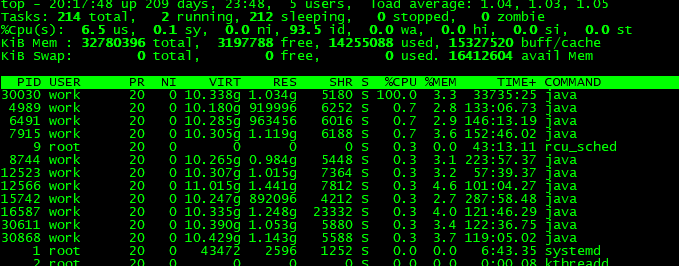
2、P:根据 CPU 使用百分比大小进行排序
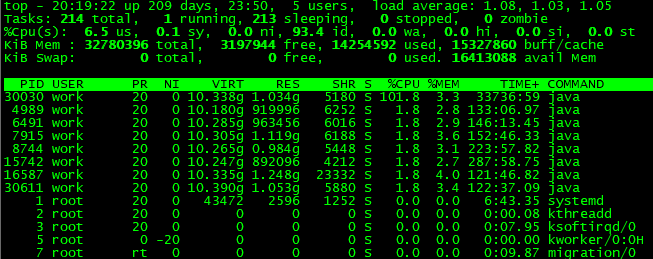
3、命令top -p 30030 :只观察进程为 30030,CPU 百分比最大的那个 Java 程序
top -p 30030
观察几分钟,发现一只占用超高,那么基本上定位到它了

b、判断是哪个 Java 程序
1、ps -ef |grep PID或者ps aux | grep PID
ps -ef 30030
ps -aux 30030
定位到应用 asset-service占用比较高

c、定位哪个线程 CPU 比较高
top -H -p pid、打印该进程下线程占用cpu情况 ,定位到线程 TID30332占用较高,讲它转化成16进制 767c
top -H -p 30030 :查看线程占用比例 得到线程30332 比较高
[work@vm10-123-3-2 ~]$ ps -mp 30030 -o THREAD,tid,time
USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME
work 95.9 - - - - - - 23-10:29:53
work 0.0 19 - futex_ - - 30030 00:00:00
work 0.0 19 - futex_ - - 30045 00:00:47
work 0.0 19 - futex_ - - 30046 00:00:20
work 0.0 19 - futex_ - - 30047 00:00:20
work 0.0 19 - futex_ - - 30048 00:00:20
work 95.6 19 - - - - 30332 23-08:37:00
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 30332 work 20 0 10.338g 1.034g 5228 R 99.9 3.3 34523:57 java 30206 work 20 0 10.338g 1.034g 5228 S 0.3 3.3 54:22.94 java 31131 work 20 0 10.338g 1.034g 5228 S 0.3 3.3 12:37.95 java 30030 work 20 0 10.338g 1.034g 5228 S 0.0 3.3 0:00.00 java 30045 work 20 0 10.338g 1.034g 5228 S 0.0 3.3 0:48.52 java 30046 work 20 0 10.338g 1.034g 5228 S 0.0 3.3 0:20.82 java 30047 work 20 0 10.338g 1.034g 5228 S 0.0 3.3 0:20.83 java
d、转储线程信息
e、下载到本地慢慢看
建议使用命令
jstack 30030 > 30030cpu.log下载到本地查看,
f、线程直接看
g、查看线程 id为30332 的 16 进制为 767c的线程日志
./jstack 30030 | grep 767c -A 10
[work@vm10-123-3-2 bin]$ ./jstack 30030 | grep 767c -A 10
"ObjectCleanerThread" #85 daemon prio=1 os_prio=0 tid=0x00007f20e290c800 nid=0x767c runnable [0x00007f20ec5a6000]
java.lang.Thread.State: RUNNABLE
at io.netty.util.Recycler$WeakOrderQueue$Head.run(Recycler.java:264)
at io.netty.util.internal.ObjectCleaner$AutomaticCleanerReference.cleanup(ObjectCleaner.java:143)
at io.netty.util.internal.ObjectCleaner$1.run(ObjectCleaner.java:62)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.lang.Thread.run(Thread.java:748)
"Log4j2-TF-7-AsyncLoggerConfig--4" #81 daemon prio=5 os_prio=0 tid=0x00007f20e087e800 nid=0x75fe runnable [0x00007f20ec4a5000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
[work@vm10-123-3-2 bin]$
我们可以使用命令
cat jstack.log | grep "java.lang.Thread.State" | sort -nr | uniq -c来对jstack的状态有一个整体的把握,如果WAITING之类的特别多,那么多半是有问题啦。
2、分析虚拟机线程
1)系统线程状态为 deadlock
线程处于死锁状态,将占用系统大量资源。
class TestTask implements Runnable {
private Object obj1;
private Object obj2;
private int order;
public TestTask(int order, Object obj1, Object obj2) {
this.order = order;
this.obj1 = obj1;
this.obj2 = obj2;
}
public void test1() throws InterruptedException {
synchronized (obj1) {
//建议线程调取器切换到其它线程运行
Thread.yield();
synchronized (obj2) {
System.out.println("test。。。");
}
}
}
public void test2() throws InterruptedException {
synchronized (obj2) {
Thread.yield();
synchronized (obj1) {
System.out.println("test。。。");
}
}
}
@Override
public void run() {
while (true) {
try {
if(this.order == 1){
this.test1();
}else{
this.test2();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test {
public static void main(String[] args) throws InterruptedException {
Object obj1 = new Object();
Object obj2 = new Object();
ExecutorService ex = Executors.newFixedThreadPool(10);
// 起10个线程
for (int i = 0; i < 10; i++) {
int order = i%2==0 ? 1 : 0;
ex.execute(new TestTask(order, obj1, obj2));
}
}
}
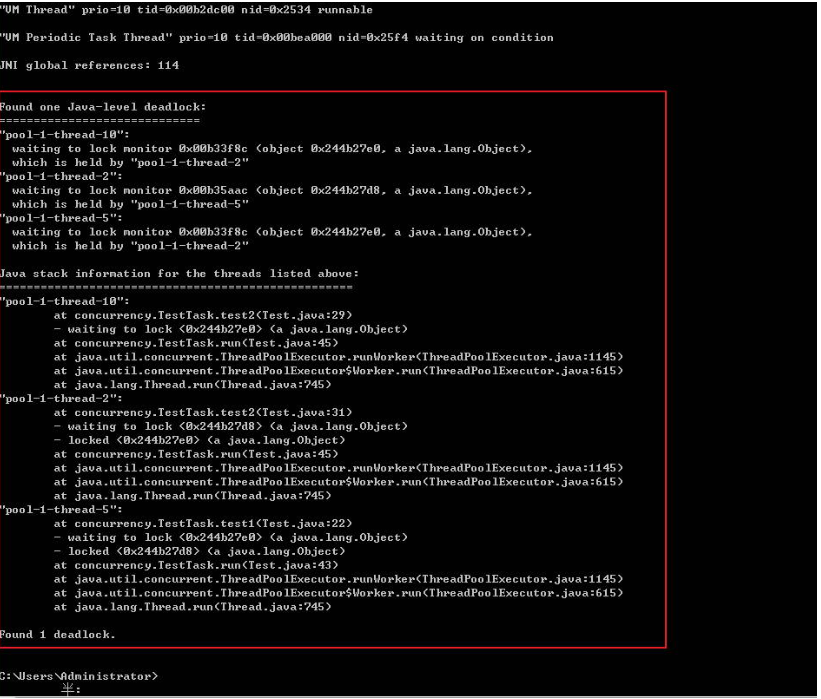
2)系统线程状态为 waiting for monitor entry 或 in Object.wait()
系统线程处于这种状态说明它在等待进入一个临界区,此时
JVM线程的状态通常都是java.lang.Thread.State: BLOCKED。如果大量线程处于这种状态的话,可能是一个全局锁阻塞了大量线程。如果短期内多次打印
Thread Dump信息,发现waiting for monitor entry状态的线程越来越多,没有减少的趋势,可能意味着某些线程在临界区里呆得时间太长了,以至于越来越多新线程迟迟无法进入。
3)系统线程状态为 waiting on condition
系统线程处于此种状态说明它在等待另一个条件的发生来唤醒自己,或者自己调用了
sleep()方法。此时JVM线程的状态通常是
java.lang.Thread.State: WAITING (parking)(等待唤醒条件)或java.lang.Thread.State: TIMED_WAITING (parking或sleeping)(等待定时唤醒条件)。如果大量线程处于此种状态,说明这些线程又去获取第三方资源了,比如第三方的网络资源或读取数据库的操作,长时间无法获得响应,导致大量线程进入等待状态。因此,这说明系统处于一个网络瓶颈或读取数据库操作时间太长。
class TestTask implements Runnable {
@Override
public void run() {
synchronized (this) {
try {
//等待被唤醒
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test {
public static void main(String[] args) throws InterruptedException {
ExecutorService ex = Executors.newFixedThreadPool(1);
ex.execute(new TestTask());
}
}
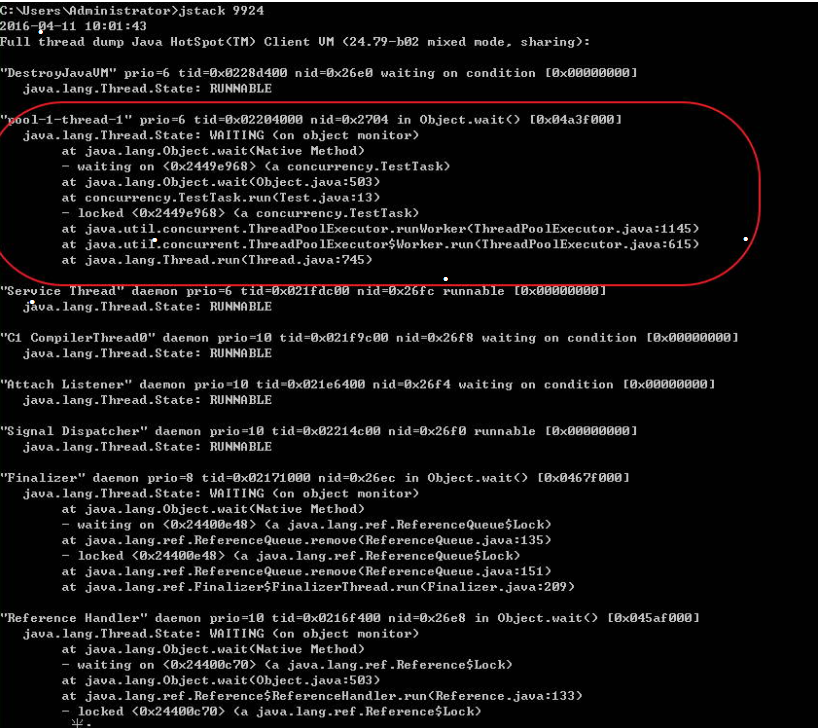
4)系统线程状态为 blocked
线程处于阻塞状态,需要根据实际情况进行判断。
3、问题
1)常见导致 CPU 升高的原因
1、大批量的计算,大批量读写数据库
2、批量操作问题,因为 IO 导致 cpu 报警
3、QPS 远大于当前负载
4、数据库慢 SQL、缓存大 key 也会导致此现象
5、宿主机问题(如果多节点“流量”均衡,单独机器不定期 CPU 报警,堆栈内存无异常,则可怀疑此现象,直接置换即可)
同
3.1.5内存泄露排查方案
2)IO 操作对 CPU 的间接影响
在
IO(输入/输出)操作期间,虽然CPU不是直接在进行IO操作,但IO操作确实可以间接导致CPU使用率升高。以下是对这一现象的详细解释:
1、IO 密集型程序:当程序需要频繁地从磁盘或网络读写数据时,这些 IO操作会消耗一定的 CPU 时间和资源。虽然主要的时间消耗在 IO 设备上,但 CPU 仍需处理与 IO 相关的中断和上下文切换。
2、中断处理:IO 操作会触发中断,这些中断会打断 CPU 的正常运行,使 CPU 需要处理中断请求并恢复执行状态。频繁的中断处理会增加CPU 的负担。
3、上下文切换:当 IO 操作进行时,CPU 可能会切换到其他进程或线程以继续执行。这种上下文切换需要消耗一定的 CPU时间和资源。如果IO 操作频繁,上下文切换也会变得频繁,从而进一步增加 CPU的使用率。
4、内存压力:如果内存不足,IO 操作可能会导致虚拟内存的使用增加,进而增加磁盘 IO 的压力。这种恶性循环会进一步加剧CPU 的负担。
三、内存问题排查
Java的内存管理就是对象的分配和释放问题。在
Java中,内存的分配是由程序完成的,而内存的释放是由GC完成的,这种收支两条线的方法简化了程序员的工作,但同时也加重了JVM的工作。
Java程序内存问题排查起来相对比CPU麻烦一些,场景也比较多。主要包括内存泄露、内存溢出、GC等问题。
1、内存泄露
1)定义
Java内存泄漏就是没有及时清理内存垃圾,导致系统无法再给你提供内存资源(内存资源耗尽)。Java内存泄露是说程序逻辑问题,造成申请的内存无法释放.这样的话无论多少内存,早晚都会被占用光的.最简单的例子就是死循环了.由于程序判断错误导经常发生此事。程序运行过程中动态分配内存给一些临时对象,这些对象有下面两个特点:
(1)这些对象是可达的
(2)这些对象是无用的,这些对象不会被
GC回收,然而它却占用内存,造成内存浪费。简单的描述为“被分配的对象可达但已无用”。
2)根本原因
长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄漏,尽管短生命周期对象已经不再需要,但是因为长生命周期持有它的引用而导致不能被回收,这就是
Java中内存泄漏的发生场景。比如,
A对象引用B对象,A对象的生命周期(t1-t4)比B对象的生命周期(t2-t3)长的多。当B对象没有被应用程序使用之后,A对象仍然在引用着B对象。这样,垃圾回收器就没办法将B对象从内存中移除,从而导致内存问题,

3)引发原因
内存泄漏大多是代码层面设计不严谨,或设计错误(编程错误),导致程序未能释放已不再使用的内存。
内存泄漏具有隐蔽性,积累性的特征,属于遗漏型缺陷,而不是过错型缺陷,不会直接产生可观察的错误症状,而是逐渐堆积,降低应用的整体性能。
可能有以下原因:
1、ThreadLocal
2、一个类含有静态变量,这个类的对象就无法被回收:内存加载数据制作为常亮
3、内存中数据量太大,比如一次性从数据库中取出来太多数据:愚公服务、vender-sign之前出现过,一次处理太多数据
4、代码中存在死循环,或者循环过多,产生过多的重复的对象
5、各种连接没有关闭:例如数据库连接、网络连接
6、单例模式:如果单例对象持有外部对象的引用,那么外部对象将不会被回收,引起内存泄漏
7、静态集合类中对对象的引用,在使用完后未清空(只把对象设为null,而不是从集合中移除),使JVM不能回收,即内存泄漏
8、静态方法中只能使用全局静态变量,而如果静态变量又持有静态方法传入的参数对象的引用,会引起内存泄漏
4)症状
1、应用程序长时间连续运行时性能严重下降
2、CPU 使用率飙升,甚至到 100%
3、频繁 Full GC
4、应用程序抛出 OutOfMemoryError 错误
5)排查方法
内存泄露,很难觉察,需要不断的去观察
gc的情况,然后dump内存进行分析,才能定位到哪一段代码有问题
a、去监控平台看GC的情况
b、查看服务器本地日志是否有 OutOfMemoryError 异常日志
c、将jvm 内存存活的对象dump下来进行分析(有专门的平台)
2、内存溢出
1)定义
程序运行过程中无法申请到足够的内存(某一块内存空间块耗尽)而导致的一种错误。
2) 症状
1、Caused by:java.lang.OutOfMemoryError: Java heap space:堆内存溢出
2、Caused by: java.lang.OutOfMemoryError: MetaSpace:元空间内存溢出(存在于JDK 8中)
3、Caused by: OutOfMemoryError:unable to create new native thread:创建本地线程内存溢出
4、Caused by:java.lang.OutOfMemoryError: Direct buffer memory:直接内存溢出
5、Caused by: java.lang.StackOverflowError:栈内存溢出(递归、死循环)
3、GC 问题
1)Young GC 频率高
原因:
JVM参数设置不合理 ,新生代空间大小设置不合理(过大:Young GC时间长,过小:Young GC频繁)解决方案:
1、查看
-Xmn、-XX:SurvivorRatio等参数设置是否合理,能否通过调整jvm参数到达目的;2、如果参数正常,但是
young gc频率还是太高,需要分析HeapDump文件,看业务代码是否生成的对象是否合理。
2)Full GC 单次时间长 / Full GC 频率高
原因:
1、JVM 参数设置不合理,尤其是新生代、老年代大小设置不合理,晋升阈值等
2、大对象创建,一次加载了过多数据到内存中(比如 SQL 查询未做分页),导致大对象进入了老年代
3、内存泄漏,大量对象引用没有释放
4、程序 BUG、显示调用 system.gc() 等,触发 Full GC
解决方案
1、检查新生代大小、晋升阈值是否过小,导致大量生命周期较短的对象进入老年代
2、检查老年代是否过小,导致内存不足承载存活的生命周期较长的对象
3、分析 HeapDump 文件,看业务代码生成的对象是否合理

