分库分表解释以及问题出现
前言
Github:https://github.com/HealerJean
1、解释
我们知道互联网是由非常庞大的用户组成,所以肯定有非常绝大的请求,这些请求又会产生非常巨大的信息存储在数据库中,由于数据量非常巨大,单个数据库的表示很难容纳所有数据,所以就有了分库分表的需求。 对于数据的拆分主要有两个方面 :垂直拆分和水平拆分
1.1、垂直拆分
垂直拆分: 根据业务的维度,将原本的一个库(表)拆分为多个库(表〉,每个库(表) 与原有的结构不同。
1.1.1、垂直分表
也就是“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。 一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
1.1.2、垂直分库
垂直分库针对的是一个系统中的不同业务进行拆分,按照业务把不同的数据放到不同的库中。其实在一个大型而且臃肿的数据库中表和表之间的数据很多是没有关系的,比如用户User一个库,商品Producet一个库,订单Order一个库。 切分后,要放在多个服务器上,而不是一个服务器上
1.2、水平拆分
水平拆分: 根据分片(sharding )算法,将一个库(表)拆分为多个库(表),每个库(表)依旧保留原有的结构。
1.2.1、水平分表
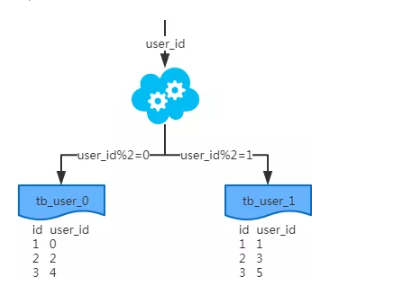
针对数据量巨大的单张表(比如订单表),按照某种规则(
Hash取模、地理区域、时间等),切分到多张表里面去。 但是这些表还是在同一个库中
**结果:分表能解决数据量过大造成的查询效率低下的问题 **
问题:但是无法有效解决数据的并发访问能力。,所以库级别的数据库操作还是有IO瓶颈。不建议采用。
1.2.2、水平分库+分表
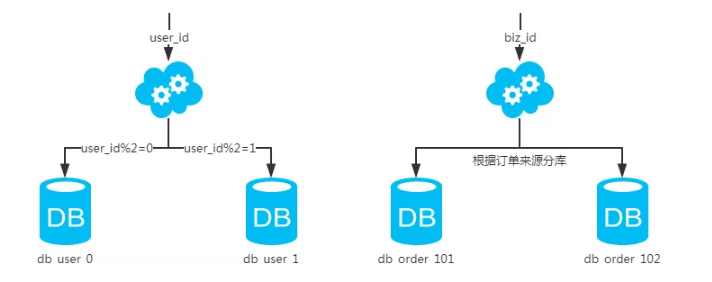
将数据库拆分,提高数据库的写入能力就是所谓的分库。将单张表的数据切分到多个数据库中,表的结构是一样的 。
结果: 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
1.3、水平分库分表的规则
路由:通过分库分表规则查找到对应的表和库的过程叫作路由。例如,分库分表的规则是user_id % 4,当用户新注册了一个账号时,假设用户的ID是123,我们就可以通过123 % 4 = 3确定此账号应该被保存在User3表中。当ID为123的用户登录时,我们可通过123 % 4 = 3计算后,确定其被记录在User3中。
1.3.1 、Hash 取模
对
hash结果取余数 (hash() mod N):对机器编号从0到N-1,按照自定义的hash()算法,对每个请求的hash()值按N取模,得到余数i,然后将请求分发到编号为i的机器
使用场景:哈希分片常常应用于数据没有时效性的情况
有一家公司在一年内能做10亿条交易,假设每个数据库分片能够容纳5000万条数据,则至少需要20个表才能容纳10亿条交易。在路由时,我们根据交易ID进行哈希取模来找到数据属于哪个分片,因此,在设计系统时要充分考虑如何设计数据库的分库分表的路由规则。
1.3.2 、地理区域
比如按照华东,华南,华北这样来区分业务
使用场景:比如我们购买ECS服务器数据,以及阿里云图片服务器等。
1.3.3 、时间
按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据 被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”。
使用场景 :切片方式适用于有明显时间特点的数据,
比如一个用户的订单交易数据,我们可以根据月或者季度进行切片,具体由交易数据量来决定以什么样的时间周期进行切割
2、分库分表后的问题
2.1、分页问题
分库后,有些分页查询需要遍历所有库。 举个分页的例子,比如要求按时间顺序展示某个商家的订单,每页100条记录,假设库数量是8,我们来看下分页处理逻辑:
2.1.1、全局视野法:
如果取第1页数据,则需要从每个库里按时间顺序取前100条记录,8个库汇总后有800条,然后对这800条记录在应用里进行二次排序,最后取前100条。
如果取第10页数据,则需要从每个库里取前1000(100*10)条记录,汇总后有8000条记录,然后对这8000条记录二次排序后取(900,1000)条记录。
分库情况下,对于第k页记录,每个库要多取100*(k-1)条记录,所有库加起来,多取的记录更多,所以越是靠后的分页,系统要耗费更多内存和执行时间。
优点:对比没分库的情况,无论取那一页,都只要从单个DB里取100条记录,而且无需在应用内部做二次排序,非常简单。
缺点:每个分库都需要返回更多的数据,增大网络传输量;除了数据库要按照time排序,服务层也需要二次排序,损耗性能;随着页码的增大,性能极具下降,数据量和排序量都将大增
2.1.2、业务折中
禁止跳页查询,不提供“直接跳到指定页面”的功能,只提供下一页的功能。正常来讲,不管哪一个分库的第3页都不一定有全局第3页的所有数据,例如一下三种情况:
1、先找到上一页的time的最大值(可从前台传入),作为第二页数据拉去的查询条件,只取每页的记录数
2、这样服务层还是获得两页数据,再做一次排序,获取一页数据。
3、改进了不会因为页码增大而导致数据的传输量和排序量增大
2.1.3、允许数据精度丢失:
需要考虑业务员上是否接受在页码较大是返回的数据不是精准的数据。
在数据量较大,且ID映射分布足够随机的话,应该是满足等概率分布的情况的,所以取一页的数据,我们在每个数据库中取(每页数据/数据库数量)个数据。 当然这样的到的结果并不是精准的,但是当实际业务可以接受的话, 此时的技术方案的复杂度变大大降低。也不需要服务层内存排序了。
2.1.4、二次查询法
2 个数据库,假设一页只有5条数据,查询第200页的SQL语句为
select * from T order by time limit 1000 5;
- 讲sql改写为
select * from T order by time limit 500 5;
注意这里的500=1000/分表数量,并将这个sql下发至每个分库分表中执行,每个分库返回这个sql执行的结果。
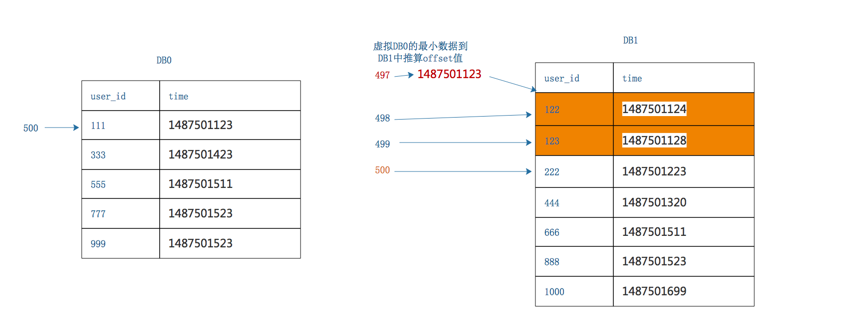
- 找到所有分库返回结果的time的最小值
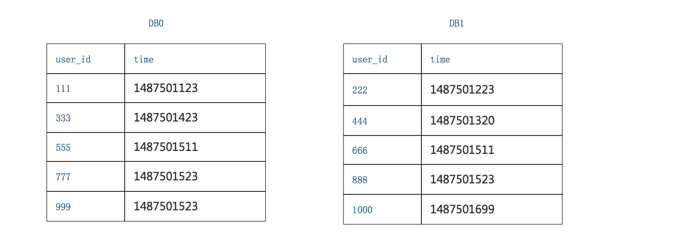
第一个库,5条数据的time最小值是1487501123
第二个库,5条数据的time最小值是1487501223
故,三页数据中,time最小值来自第一个库,time_min=1487501123,这个过程只需要比较各个分库第一条数据,时间复杂度很低
- 查询二次改写,第二次要改写成一个between语句,between的起点是time_min,between的终点是原来每个分库各自返回数据的最大值:
第一个分库,第一次返回数据的最大值是1487501523
所以查询改写为select * from T order by time where time between time_min and 1487501523
第二个分库,第一次返回数据的最大值是1487501699
所以查询改写为select * from T order by time where time between time_min and 1487501699
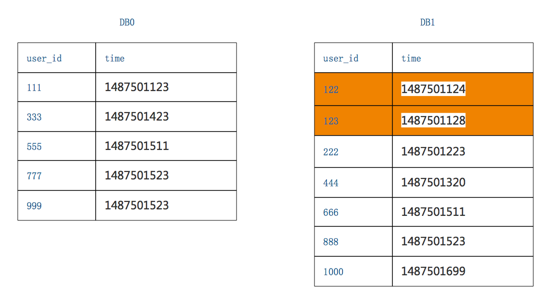
从上面图片可以看出,DB1比第一次查出来的数据多了两行,应为查询的范围扩大了
- 计算time_min这条记录在全局的偏移量
- 获取最终结果,讲第二次查询出的进行排序,最终获得结果
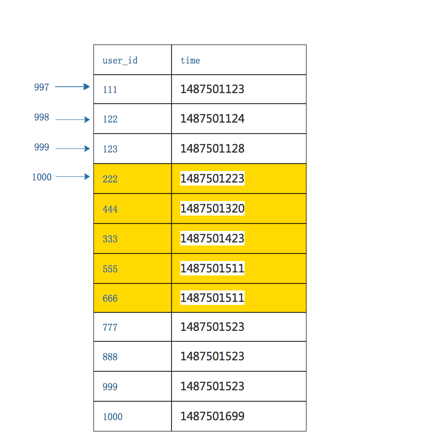
优点:可以精确的返回业务所需数据,每次返回的数据量都非常小,不会随着翻页增加数据的返回量。
缺点:需要进行两次数据库查询
2.2、Join问题
互联网公司的业务,往往是并发场景多,DB查询频繁,有一定用户规模后,往往要做分库分表。 分库分表Join肯定是不行的
2.2.1、不使用join的原因:
1、join的话,是走嵌套查询的。小表驱动大表,且通过索引字段进行关联。如果表记录比较少的话,还是OK的当表处于百万级别后,join导致性能下降;
2、分布式的分库分表。这种时候是不建议跨库join的。目前mysql的分布式中间件,跨库join表现不良。
3、join写的sql语句要修改,不容易发现,成本比较大,当系统比较大时,不好维护。
4、 数据库是最底层的,一个系统性能好坏的瓶颈往往是数据库。建议数据库只是作为数据存储的工具,而不要添加业务上去。
2.2.2、不使用join的解决方法:
应用层面解决 :可以更容易对数据进行分库,更容易做到高性能和可扩展。(记得在小米金融供应链关联查询卖方,卖方 核心企业,授信企业的使用,就是这样,本来其实是两个企业,但是却有4个子段表示join查询肯定是不好的)
缓存的效率更高。许多应用程序可以方便地缓存单表查询对应的结果对象。,如果某个表很少改变,那么基于该表的查询就可以重复利用查询缓存结果了。单表查询出数据后,作为条件给下一个单表查询
查询本身效率也可能会有所提升。查询id集的时候,使用IN()代替关联查询,可以让MySQL按照ID顺序进行查询,这可能比随机的关联要更高效。mysql对in的数量没有限制,mysql限制整条sql语句的大小。通过调整参数max_allowed_packet ,可以修改一条sql的最大值。建议在业务上做好处理,限制一次查询出来的结果集是能接受的,但是最好不要超过500条(小米规范)
可以减少多次重复查询。在应用层做关联查询,意味着对于某条记录应用只需要查询一次,而在数据库中做关联查询,则可能需要重复地访问一部分数据。从这点看,这样的重构还可能会减少网络和内存的消艳。
Map<Long, CompanyDTO> map = companyDTOS.stream().collect(
Collectors.toMap(item -> item.getCompanyId(), item -> item));
Map<Long, Integer> poolCountMap = scfLoanCreditPoolMatchManager.countGroupByPoolId(scfLoanCreditPoolMatchQuery);
collect = data.stream().map(temp -> {
LoanCreditPoolDTO item = BeanUtils.loanCreditPoolToDTO(temp);
item.setCoreCompanyName(map.get(item.getCoreCompanyId()).getCompanyName()) ;
item.setCreditCompanyName(map.get(item.getCreditCompanyId()).getCompanyName()) ;
) );
return item ;
}).collect(Collectors.toList());
}
2.3、分组 :查出来再计算
分组实现较简单,只需对128张表各自进行group by ,将128张表的结果,全都取到内存中,进行合并,如果有having条件再根据合并的结果进行筛选。
2.4、其他如sum,avg,max等方法
查出来再计算
avg :在分片的环境中,以
avg1+avg2+avg3/3计算平均值并不正确,需要改写为(sum1+sum2+sum3)/(count1+count2+ count3)。这就需要将包含avg的SQL改写为sum和count,然后再结果归并时重新计算平均值。
3、事务
分库分表后,就成了分布式事务了。
如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;
如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
3.1、传统事务
3.1.1、特性
(1) 原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,这和前面两篇博客介绍事务的功能是一样的概念,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
(2)一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行 之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
(3)隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
(4)持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
3.1.2、事务方法回顾
我们知道,当
dbTransactional执行的时候,不管是userService.insert还是companyService.insert出现了异常,dbTransactional都可以整体回滚,达到原子操作的效果,其主要原因是
userService.insert和companyService.insert共享了同一个Connection,这是spring底层通过ThreadLocal缓存了Connection实现的。
@Transactional(rollbackFor = Exception.class)
@Override
public void dbTransactional(UserDTO userDTO, CompanyDTO companyDTO) {
userService.insert(userDTO);
companyService.insert(companyDTO);
}
public interface UserService {
UserDTO insert(UserDTO userDTO);
}
public interface CompanyService {
CompanyDTO insert(CompanyDTO companyDTO);
}
3.2、sharding-jdbc事务
public enum TransactionType {
LOCAL,//本地事务
XA, //二阶段事务
BASE;//
private TransactionType() {
}
}
| 本地事务 | 两阶段提交 | 柔性事务 | |
|---|---|---|---|
| 业务改造 | 无 | 无 | 实现相关接口 |
| 一致性 | 不支持 | 支持 | 最终一致 |
| 隔离性(不知道这里的隔离性代表啥) | 不支持 | 支持 | 业务方保证(规划中) |
| 并发性能 | 无影响 | 严重衰退 | 略微衰退 |
| 适合场景 | 业务方处理不一致 | 短事务 & 低并发 | 长事务 & 高并发 |
3.2.1、LOCAL之本地事务(默认)
如果不使用柔性事务,默认提供的是本地事务(弱
XA事务支持) ,基于弱XA的事务无需额外的实现成本,因此Sharding-Sphere默认支持。
3.2.1.1、特性
1、完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中。
2、完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能回滚。
3、不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库死机(可以理解为网络导致的,但是程序认为提交无误),则只有第二个库数据提交。
3.2.1.2、理解
3.2.1.2.1、正常流程
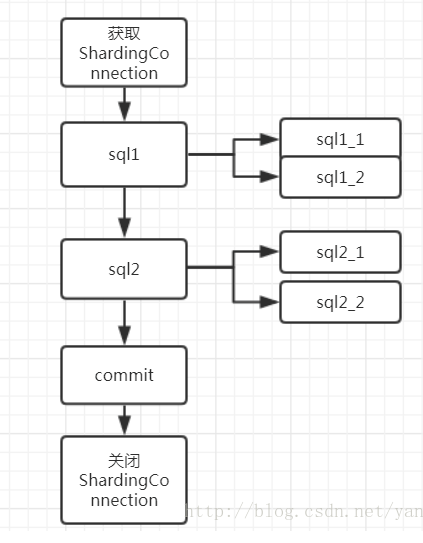
这是一个非常常见流程,一个总连接处理了多条sql语句,最后一次性提交整个事务,每一条sql语句可能会分为多条子sql分库分表去执行,这意味着底层可能会关联多个真正的数据库连接,我们先来看看如果一切正常,commit会如何去处理。
@Transactional(rollbackFor = Exception.class)
@Override
public void dbTransactional(UserDTO userDTO, CompanyDTO companyDTO) {
userService.insert(userDTO);
companyService.insert(companyDTO);
}
public interface UserService {
UserDTO insert(UserDTO userDTO);
}
public interface CompanyService {
CompanyDTO insert(CompanyDTO companyDTO);
}
在进入
dbTransactional初始化才初始化事务管理器DataSourceTransactionManager等(因为是多个数据源的情况) ,在方法结束的时候多个数据源连接统一commit
public final class ShardingConnection extends AbstractConnectionAdapter {
@Override
public void commit() throws SQLException {
if (TransactionType.LOCAL == transactionType) {//local 本地事务
super.commit();
} else {
shardingTransactionManager.commit();
}
}
}
public abstract class AbstractConnectionAdapter
extends AbstractUnsupportedOperationConnection {
public void commit() throws SQLException {
this.forceExecuteTemplate.execute(this.cachedConnections.values(), //所有数据库连接
new ForceExecuteCallback<Connection>() {
public void execute(Connection connection) throws SQLException {
connection.commit();//一个一个commit提交
}
});
}
}
cachedConnections

public final class ForceExecuteTemplate<T> {
public void execute(Collection<T> targets, ForceExecuteCallback<T> callback)
throws SQLException {
Collection<SQLException> exceptions = new LinkedList();
Iterator var4 = targets.iterator();
while(var4.hasNext()) {
Object each = var4.next();
try {
callback.execute(each);
} catch (SQLException var7) {
exceptions.add(var7);
}
}
this.throwSQLExceptionIfNecessary(exceptions);
}
}
到了这里会发现一个个进行commit操作,如果任何一个出现了异常,直接捕获异常,但是也只是捕获而已,然后接着下一个连接的commit,这也就很好的说明了下面两点。异常情况看后面
3.2.1.2.2、异常流程
如果已经到了commit这一步的话,如果因为网络原因导致的commit失败了,是不会影响到其他连接的。
如果在整个方法结束的时候之前出现了逻辑异常(i = 1/0),则不会执行commit,而是直接执行回滚rollback方法,如下 (有个问题:callback出现网络异常怎么办呢。反正肯定不会入库的)
public final class ShardingConnection extends AbstractConnectionAdapter {
@Override
public void rollback() throws SQLException {
if (TransactionType.LOCAL == transactionType) {//local 本地事务
super.rollback();
} else {
shardingTransactionManager.rollback();
}
}
}
public abstract class AbstractConnectionAdapter
extends
AbstractUnsupportedOperationConnection {
public void rollback() throws SQLException {
this.forceExecuteTemplate.execute(this.cachedConnections.values(), //所有的数据库连接
new ForceExecuteCallback<Connection>() {
public void execute(Connection connection) throws SQLException {
connection.rollback();//数据库回滚(一个一个回滚)
}
});
}
}
public final class ForceExecuteTemplate<T> {
public void execute(Collection<T> targets, ForceExecuteCallback<T> callback)
throws SQLException {
Collection<SQLException> exceptions = new LinkedList();
Iterator var4 = targets.iterator();
while(var4.hasNext()) {
Object each = var4.next();
try {
callback.execute(each);
} catch (SQLException var7) {
exceptions.add(var7);
}
}
this.throwSQLExceptionIfNecessary(exceptions);
}
}
3.2.2、XA:2阶段事务
看分布式事务详解

