今日算法之__12_二叉树
前言
Github:https://github.com/HealerJean
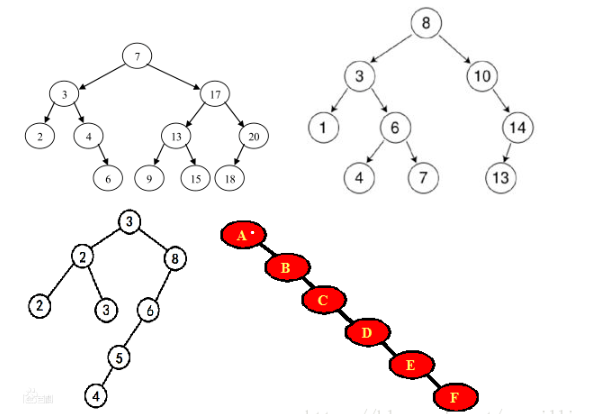
1、二叉排序树
二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),也称二叉搜索树。
1、若左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值;
2、若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值 ;
3、左、右子树也分别为二叉排序树;
注意:对二叉排序树进行中序遍历,得到有序集合
1.1、计算
1.1.1、查找/插入
1、以从第一个父节点开始跟目标元素值比较,如果相等则返回当前节点,
2、如果目标元素小于当前节点,则移动到左侧子节点进行比较,
3、如果目标元素大于当前节点,则移动到右侧子节点进行比较
优点: 二叉树是一种比顺序结构更加高效地查找目标元素的结构,在理想情况下,每次比较过后,树会被砍掉一半,近乎折半查找。
缺点:在大部分情况下,我们设计索引时都会在表中提供一个自增整形字段作为建立索引的列(比如主键),在这种场景下使用二叉树的结构会导致我们的索引总是添加到右侧,在查找记录时跟没加索引的情况是一样的,
1.1.2、删除
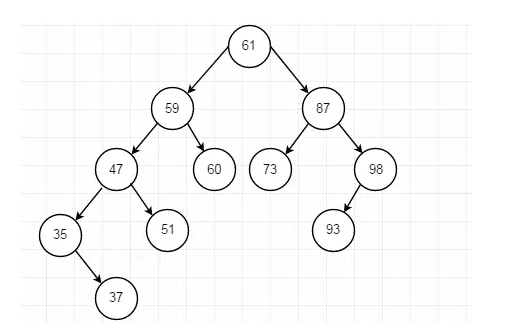
1.1.2.1、删除叶子节点93
直接删除即可
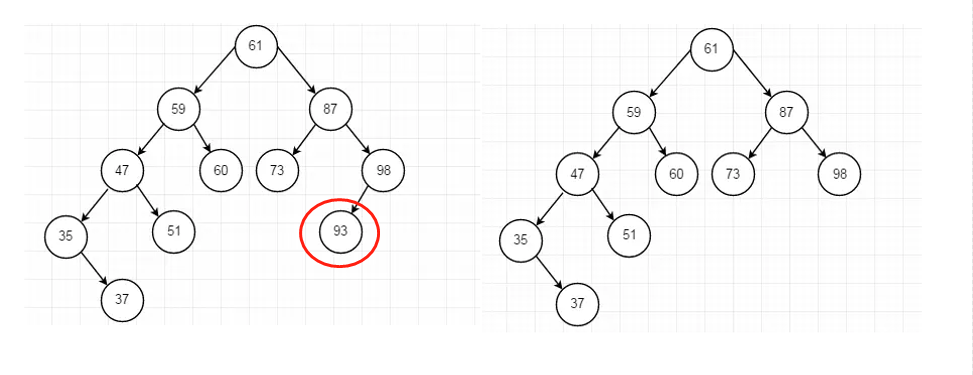
1.1.2.2、删除的节点35只有右子树/左子树
只有右子树:右子树替换删除节点
只有左子树:左子树替换删除节点
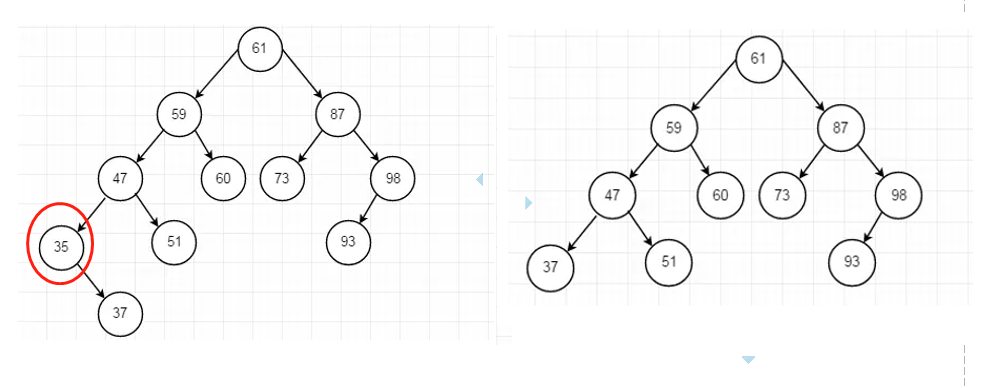
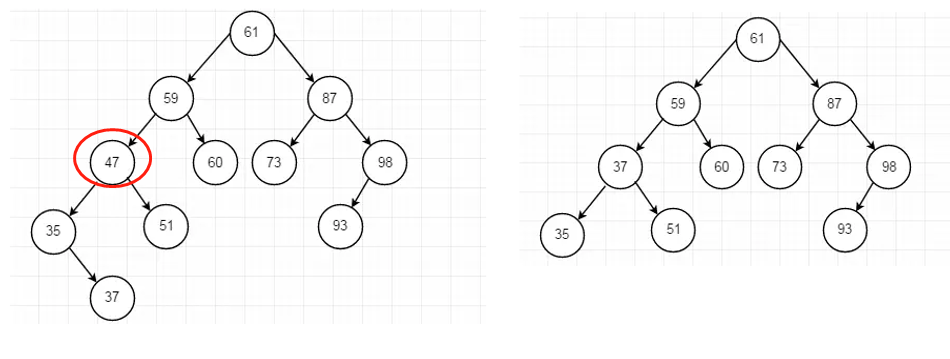
1.1.2.3、 删除的结点47既有左子树又有右子树
可以采用中序遍历的方式来得到删除结点的前驱和后继结点。选取前驱结`或者后继结点(具体哪个自己决定,我这里是选择的前驱节点)代替删除结点即可。
1、遍历:35 37 47 51 59 60 61 73 93 98
2、除的结点为47,则结点47的前驱结点为37,则直接将37结点替代47结点即可。
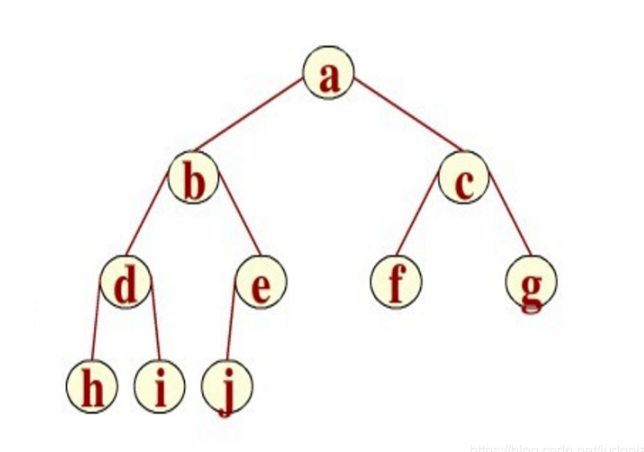
2、完全二叉树
2.1、完全二叉树
解释:当二叉树的深度为h时,它的h层节点必须都是连续靠左并不可隔开的,
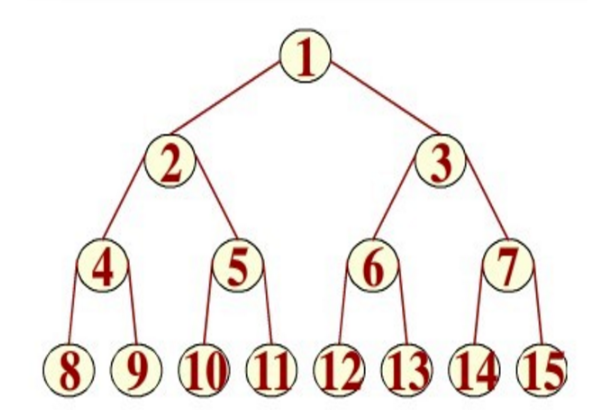
2.2、满二叉树
解释:指深度为k且有2^k-1个结点的二叉树。,也是完全二叉树
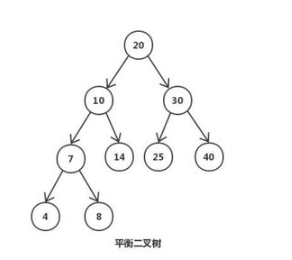
3、平衡二叉树
不管我们是执行插入还是删除操作,只要不满足平衡的条件,就要通过旋转来保存平衡,而因为旋转非常耗时,由此我们可以知道AVL树适合用于插入与删除次数比较少,但查找多的情况。 由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。
【平衡二叉树】优点:如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。平衡二叉树的目的是为了减少二叉查找树层次,提高查找速度 它查找的效率非常稳定,为O(log n)
【红黑树】优点:由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树,相对于要求严格的AVL树来说,它的旋转次数少,插入最多两次旋转,删除最多三次旋转,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。
缺点:当作为数据库结构的时候,数量量大的时候,深度也很大,每个父节点只能存在两个子节点,当数据量大的时候,那么树的深度依然会很大,可能就会超过十几二十层以上,对我们的磁盘寻址不利,依然会花费很多时间查找。
3.1、平衡二叉树
解释:
1、它的左右两个子树的高度差(平衡因子)的绝对值不超过1
2、左右两个子树都是一棵平衡二叉树,
3、平衡二叉树必定是二叉搜索树,反之则不一定
2.1.1、计算
2.1.1.1、插入
1、每当插入一个新结点时, 首先检查是否因插入新结点而破坏了二叉排序树的平衡性,
2、若是,则找出其中的最小不平衡子树,在保持二叉排序树特性的前提下,调整最小不平衡子树中各结点之间的链接关系,进行相应的旋转,使之成为新的平衡子树。
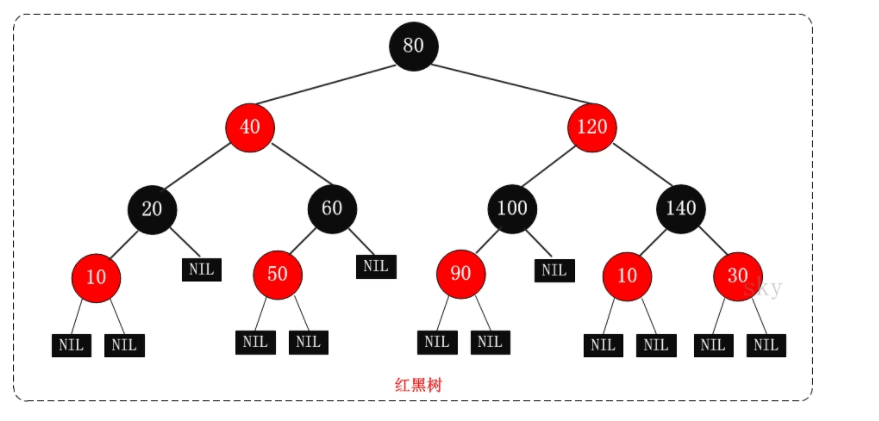
3.2、红黑树
红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。红黑树是一中弱平衡二叉树
解释:
1、每个结点或红或黑
2、根结点是黑色
3、空叶子结点是黑色
4、如果一个结点是红色,那么它的子节点都是是黑色
5、从任意一个结点出发到空的叶子结点经过的黑结点个数相同
4、Hash
解释:对数据进行Hash(散列)运算,主流的Hash算法有MD5、SHA256等等,然后将哈希结果作为文件指针可以从索引文件中获得数据的文件指针,再到数据文件中获取到数据
优点:我们在查找where Col2 = 22的记录时只需要**对22做哈希运算得到该索引所对应那行数据的文件指针,从而在MySQL的数据文件中定位到目标记录,查询效率非常高。但是也可能造成hash冲突
缺点:无法解决范围查询(Range)的场景,比如 select count(id) from sus_user where id >10;因此Hash这种索引结构只能针对字段名=目标值的场景使用。 不适合模糊查询(like)的场景
5、B树
记住,没有B-树,至于为什么,不知道,它是一颗多路平衡查找树
解释:m数阶数, k是节点个数
1、根节点至少1个关键字。
2、非根节点至少有m/2个关键字。
3、每个节点最多有m-1个关键字
4、每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
5、所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同。
6、每个节点都存有索引和数据,也就是对应的key和value。
根节点的关键字数量范围:
1 <= k <= m-1,非根节点的关键字数量范围:
m/2 <= k <= m-1。比如这里有一个5阶的B树,根节点数量范围:1 <= k <= 4,非根节点数量范围:2 <= k <= 4。
5.1、计算
5.1.1、插入
**1、判断当前结点key的个数是否小于等于m-1,如果满足,直接插入即可, **
**2、如果大于m-1,将节点的中间的key将这个节点分为左右两部分,中间的节点放到父节点中即可 **
举例:在5阶B树中,结点最多有4个key,最少有2个key(注意:下面的节点统一用一个节点表示key和value)
1、插入18,70,50,40
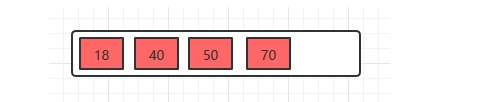
2、插入22:此时发现这个节点的关键字已经大于4了,所以需要进行分裂,分裂的规则在上面已经讲了,分裂之后,如下。
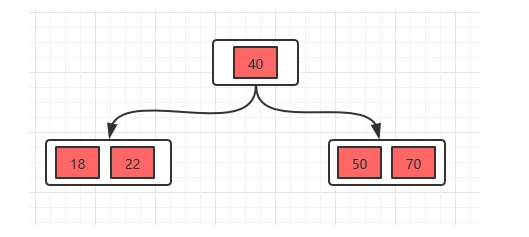
3、接着插入23,25,39
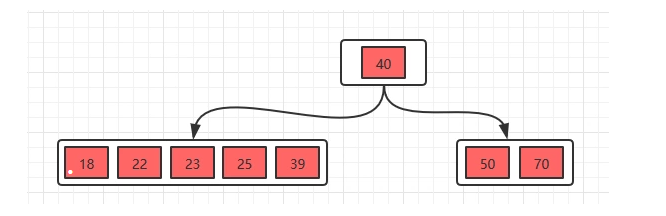
分裂得到下面的
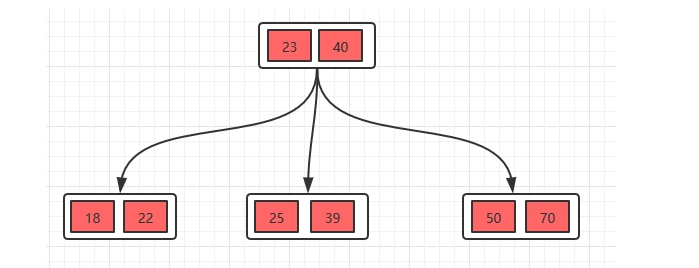
4、更过的插入的过程就不多介绍了,相信有这个例子你已经知道怎么进行插入操作了。
5.1.2、删除
B树的删除操作相对于插入操作是相对复杂一些的,但是,你知道记住几种情况,一样可以很轻松的掌握的。
举例:现在有一个初始状态是下面这样的B树,然后进行删除操作。
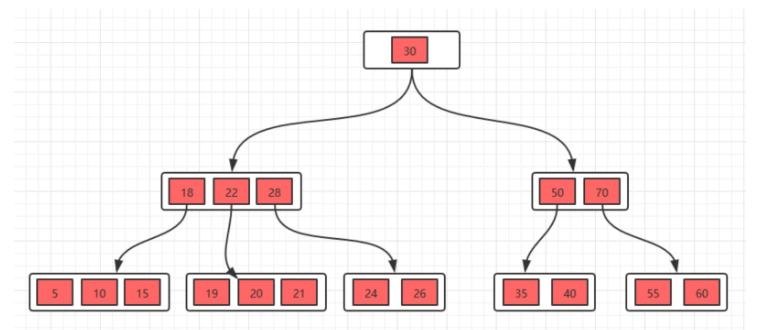
5.1.2.1、删除叶子节点
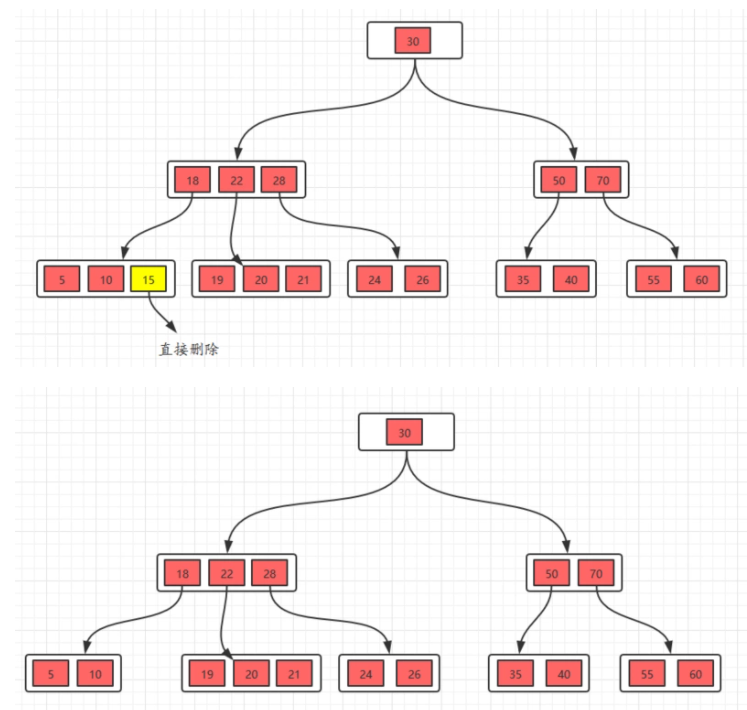
删除15
方法:这种情况是删除叶子节点的元素,如果删除之后,节点数还是大于
m/2,这种情况只要直接删除即可。
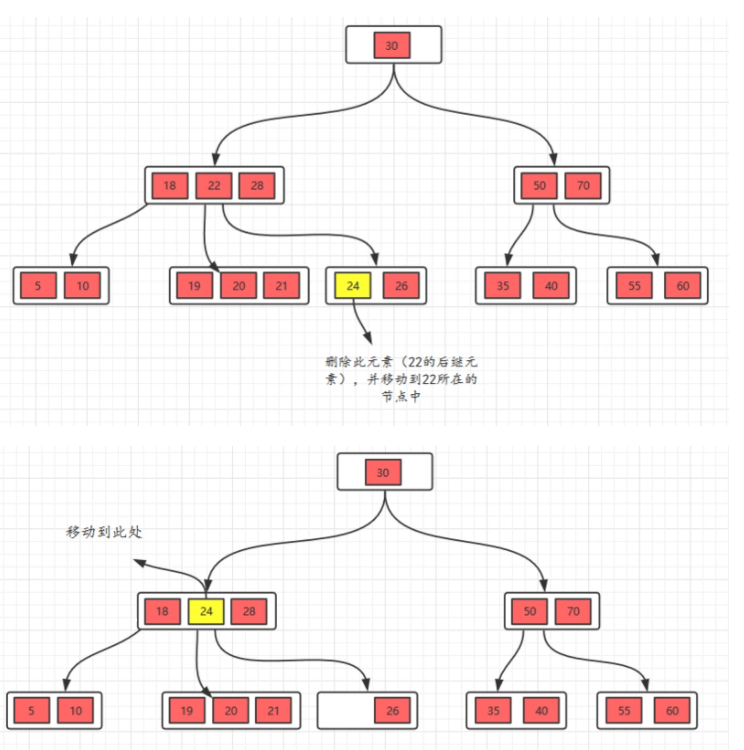
5.1.2.2、删除非叶子节点
删除22,22是非叶子节点,
**方法: **
1、对于非叶子节点的删除,我们需要用后继key(元素)覆盖要删除的key,然后在后继key所在的子支中删除该后继key。对于删除22,需要将后继元素24移到被删除的22所在的节点。
2、此时发现26所在的节点只有一个元素,小于2个(m/2),这个节点不符合要求,这时候的规则(向兄弟节点借元素)
3、它的兄弟节点的元素大于(m/2),也就是说兄弟节点的元素比最少值m/2多,将先将父节点的元素移到该节点,然后将兄弟节点的元素再移动到父节点。这样就满足要求了。
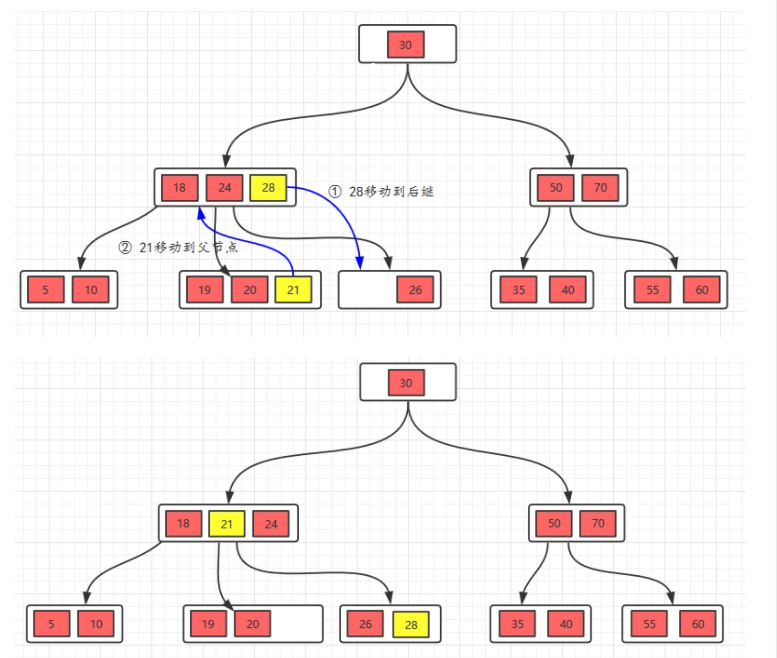
5.1.2.3、删除复杂的叶子节点
删除28
1、删除28之后,当前节点元素小于m/2,这个时候考虑向兄弟借点元素,但是发现兄弟节点没有多余的节点了(兄弟节点的元素个数 <= m/2)
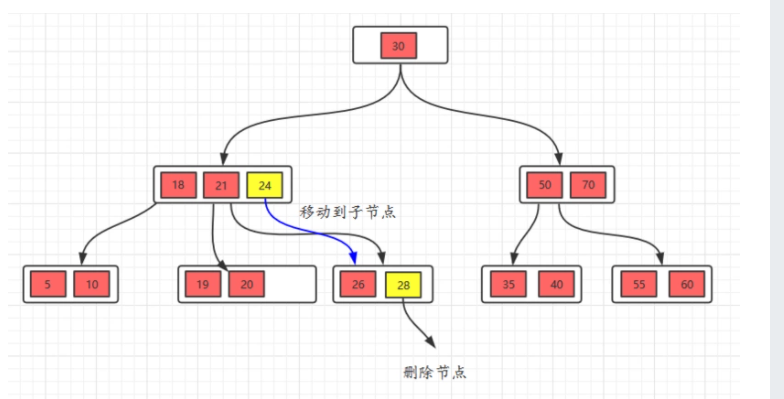
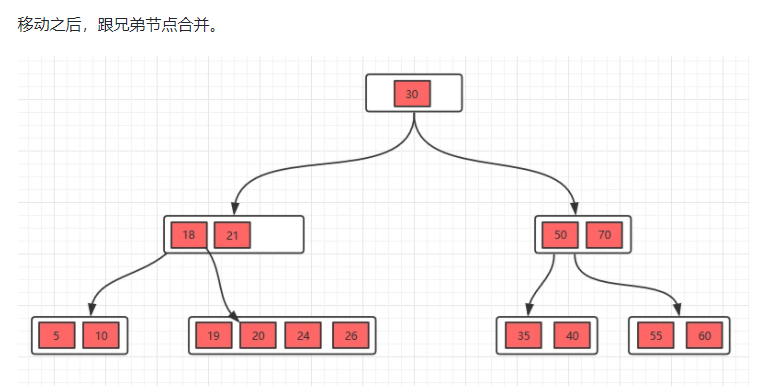
2、这个时候,讲父节点元素移动到该节点,然后,将当前节点及它的兄弟节点中的key合并,形成一个新的节点,移动之后,跟兄弟节点合并。
6、B+树
解释:m数阶数, k是节点个数
1、根节点至少一个元素
2、非根节点元素范围:m/2 <= k <= m-1
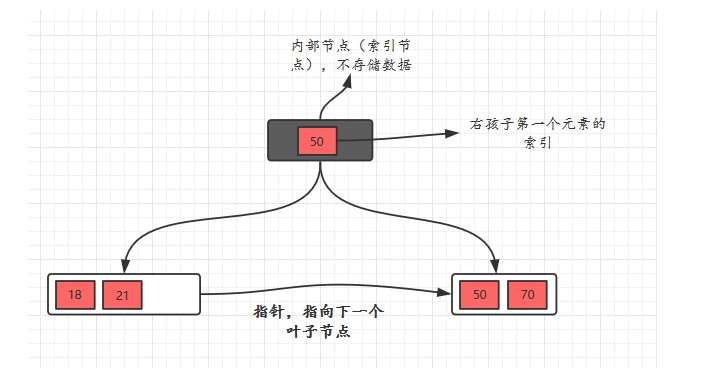
3、B+树有两种类型的节点:内部节点(非叶子节点)不存储数据,只存储索引,叶子节点存储数据(也会存储索引)。
4、内部结点(非叶子节点)中的key都按照从小到大的顺序排列,叶子结点中的记录也按照key的大小排列。
5、每个叶子结点都存有相邻叶子结点的指针
6、父节点存有右孩子的第一个元素的索引。(注意是孩子,不是右节点)
6.1、计算
对于插入操作很简单,只需要记住一个技巧即可:当节点元素数量大于m-1的时候,按中间元素分裂成左右两部分,中间元素分裂到父节点当做索引存储,但是,本身中间元素还是分裂右边这一部分的。
6.1.1、插入
方法: 当节点元素数量大于m-1的时候,按中间元素分裂成左右两部分,中间元素分裂到父节点当做索引存储,但是,本身中间元素还是分裂右边这一部分的。
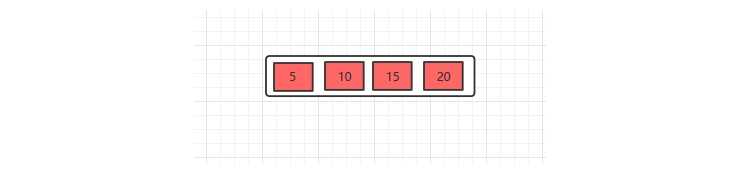
1、插入5,10,15,20
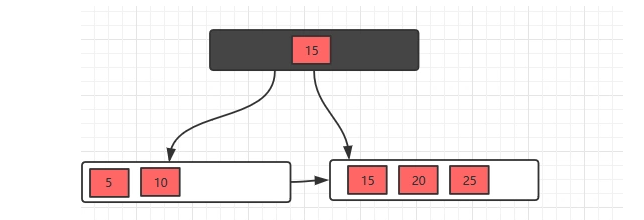
2、插入25,此时元素数量大于4(m-1)个了,分裂
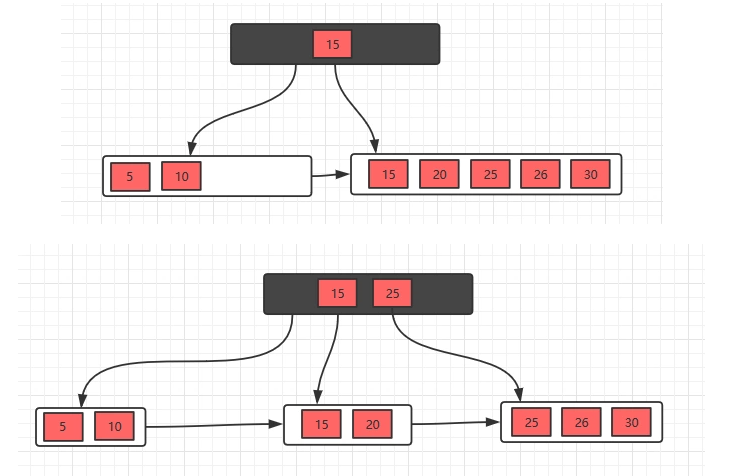
2、接着插入26,30,继续分裂
6.1.2、删除
对于删除操作是比B树简单一些的,
1、因为**叶子节点有指针的存在,向兄弟节点借元素时,不需要通过父节点了,而是可以直接通过兄弟节移动即可(前提是兄弟节点的元素大于m/2) **
2、然后更新父节点的索引;如果兄弟节点的元素不大于m/2(兄弟节点也没有多余的元素),则将当前节点和兄弟节点合并,并且删除父节点中的key,下面我们看看具体的实例。
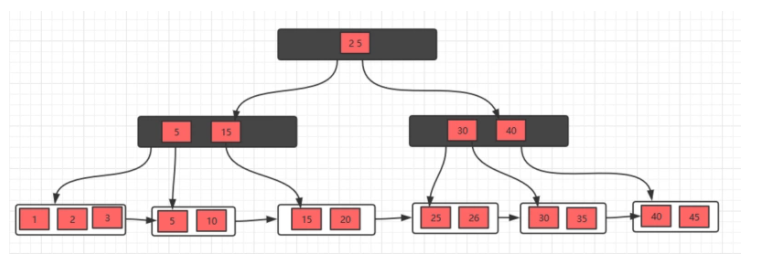
1、删除10,删除后,不满足要求,发现左边兄弟节点有多余的元素,所以去借元素,最后,修改父节点索引
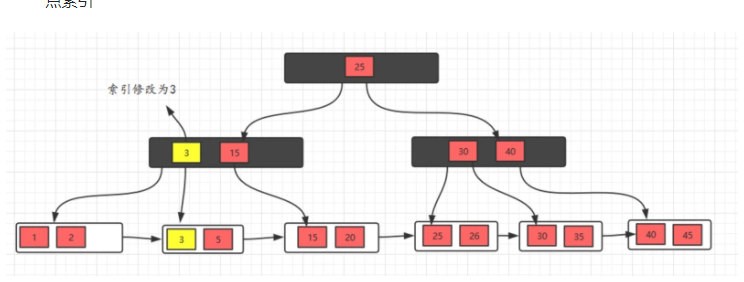
2、删除元素5,发现不满足要求,并且发现左右兄弟节点都没有多余的元素,所以,可以选择和兄弟节点合并,最后修改父节点索引,
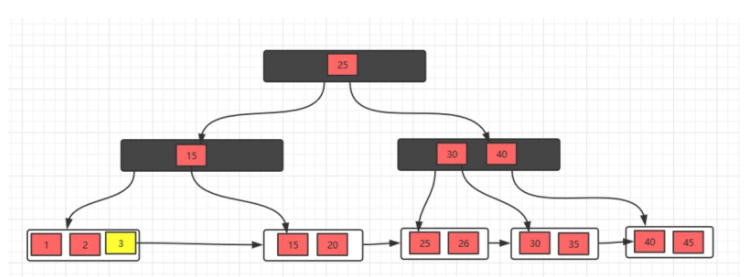
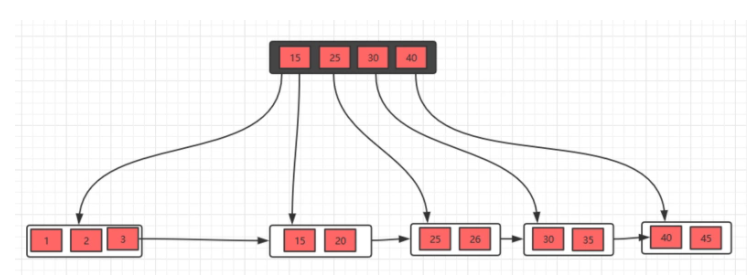
此时发现父节点索引也不满足条件,所以,需要做跟上面一步一样的操作
6.2、总结
B+树相对于B树有一些自己的优势,可以归结为下面几点。
1、B 树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了,B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
2、B+树结构没有在所有的节点里存储记录数据,而是只在最下层的叶子节点存储,上层的所有非叶子节点只存放索引信息,这样的结构可以让单个节点存放下更多索引值,同时只放索引翻页更快。使得查询的IO次数更少,所以也就使得它更适合做为数据库MySQL的底层数据结构了

