Redis畅通之_缓存问题
前言
Github:https://github.com/HealerJean
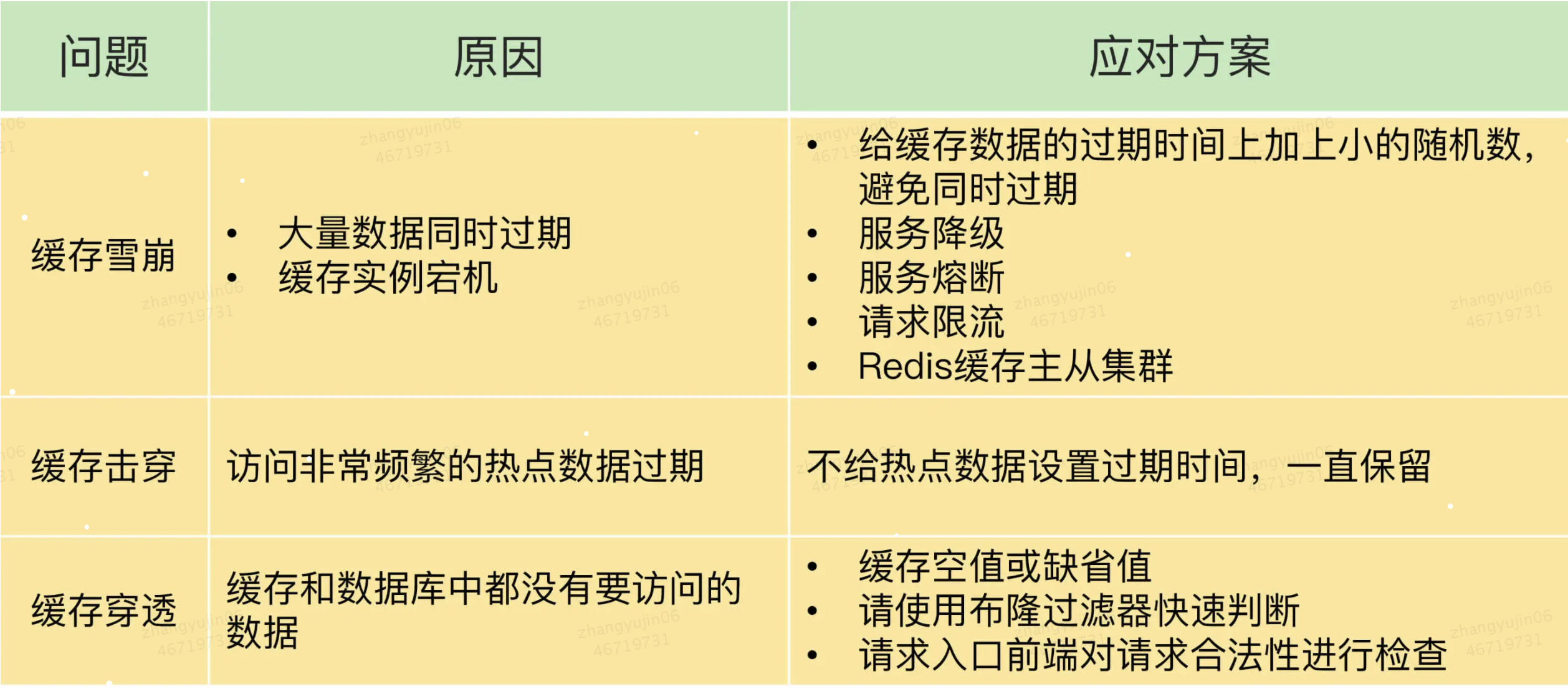
一、缓存雪崩
缓存雪崩是指大量的应用请求无法在
Redis缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增。
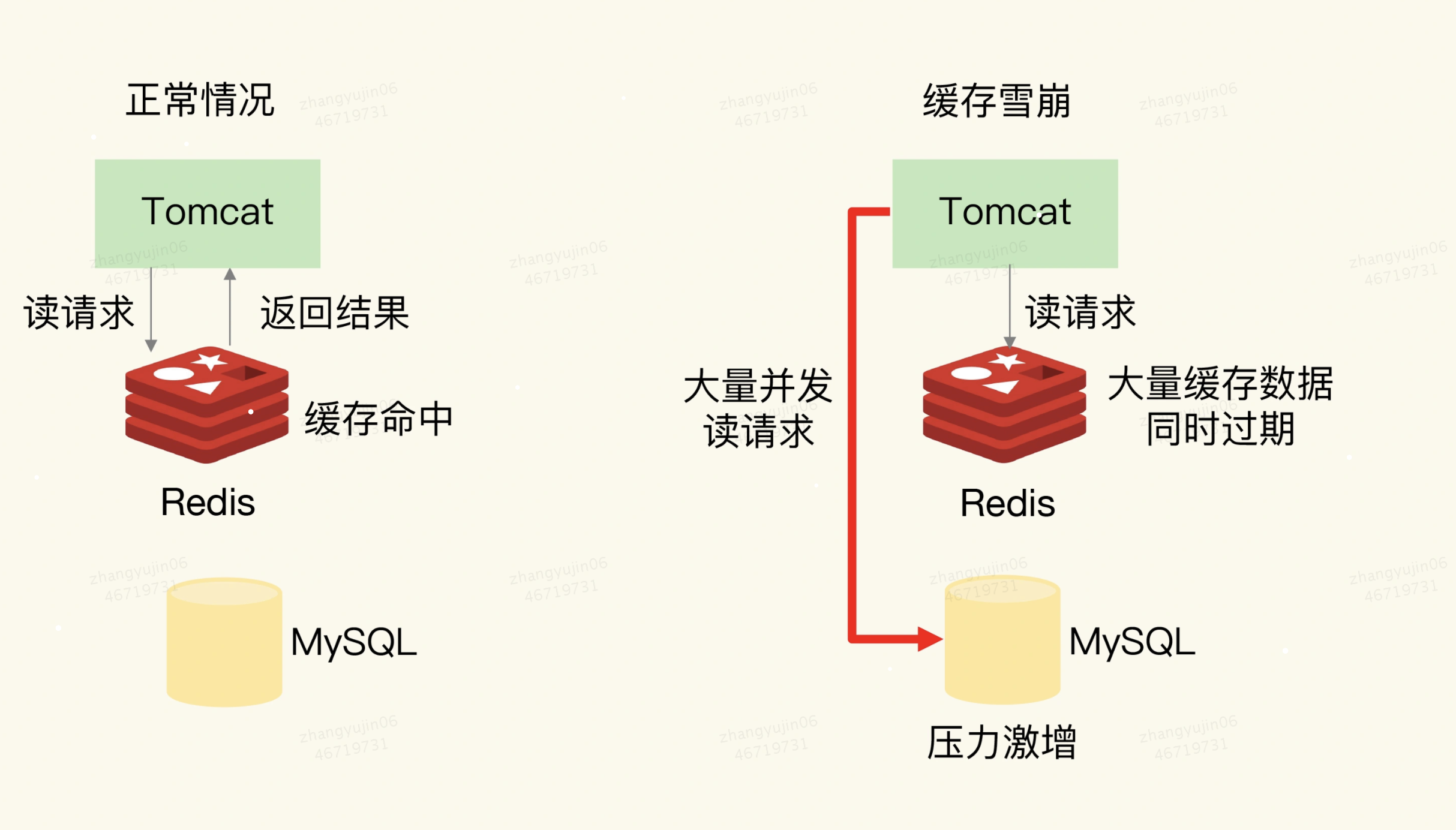
1、原因1:大量数据同时过期
解释:缓存中有大量数据同时过期,导致大量请求无法得到处理。
⬤ 当数据保存在缓存中,并且设置了过期时间时,在某一个时刻,大量数据同时过期,此时,应用再访问这些数据的话,就会发生缓存缺失。紧接着,应用就会把请求发送给数据库,从数据库中读取数据。
⬤ 如果应用的并发请求量很大,那么数据库的压力也就很大,这会进一步影响到数据库的其他正常业务请求处理。
1)方案1:缓存有效期随机
首先,我们可以避免给大量的数据设置相同的过期时间。如果业务层的确要求有些数据同时失效,你可以在用
EXPIRE命令给每个数据设置过期时间时,给这些数据的过期时间增加一个较小的随机数(例如,随机增加1~3分钟),这样一来,不同数据的过期时间有所差别,但差别又不会太大,既避免了大量数据同时过期,同时也保证了这些数据基本在相近的时间失效,仍然能满足业务需求。
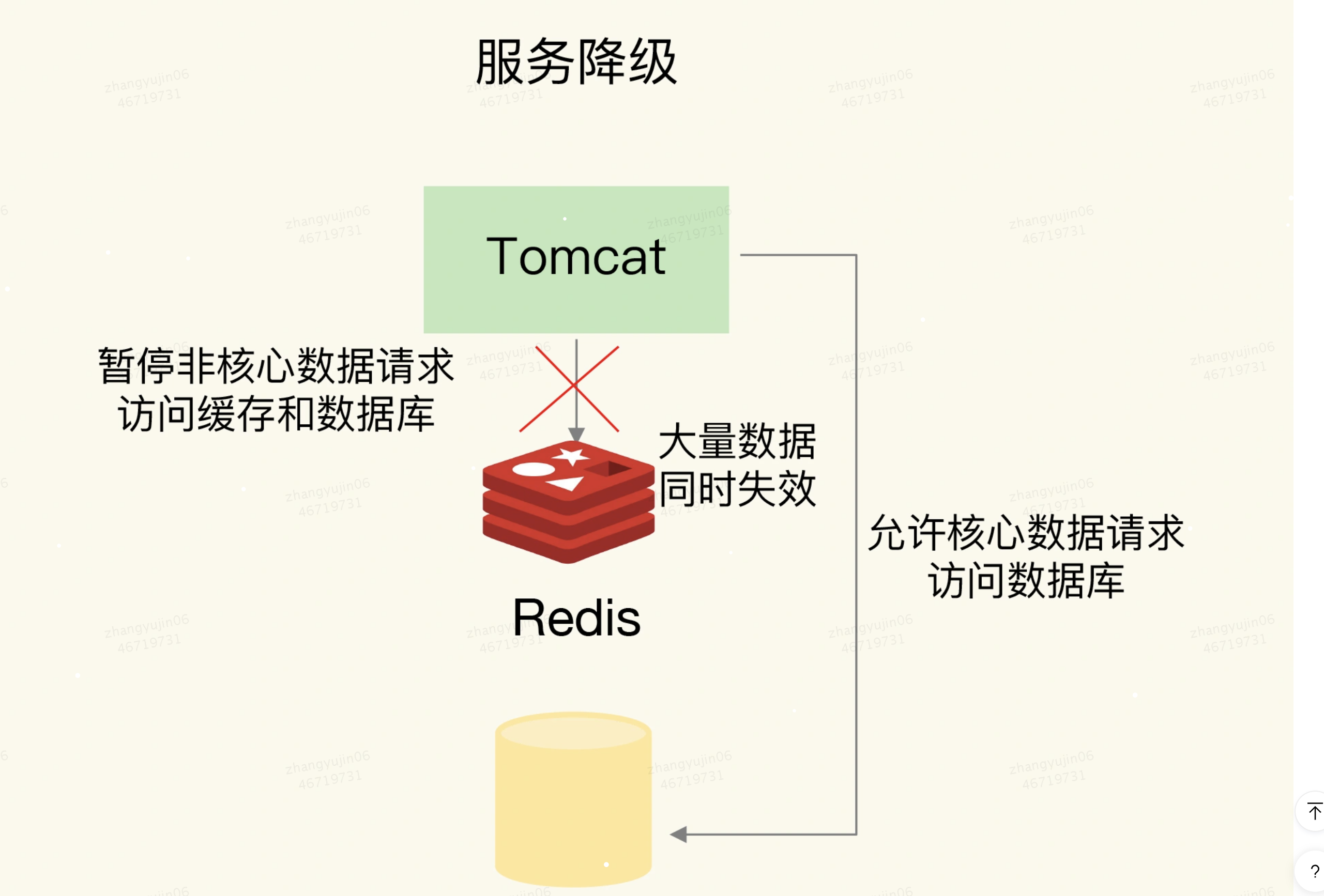
2)方案2:服务降级
服务降级,是指发生缓存雪崩时,针对不同的数据采取不同的处理方式。保证只有部分过期数据的请求会发送到数据库,数据库的压力就没有那么大了
⬤ 当业务应用访问的是非核心数据(例如电商商品属性)时,暂时停止从缓存中查询这些数据,而是直接返回预定义信息、空值或是错误信息;
⬤ 当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
2、原因2:Redis 缓存实例发生故障宕机了
解释:
Redis缓存实例发生故障宕机了,无法处理请求,这就会导致大量请求一下子积压到数据库层,从而发生缓存雪崩一般来说,一个
Redis实例可以支持数万级别的请求处理吞吐量,而单个数据库可能只能支持数千级别的请求处理吞吐量,它们两个的处理能力可能相差了近十倍。由于缓存雪崩,Redis缓存失效,所以,数据库就可能要承受近十倍的请求压力,从而因为压力过大而崩溃。
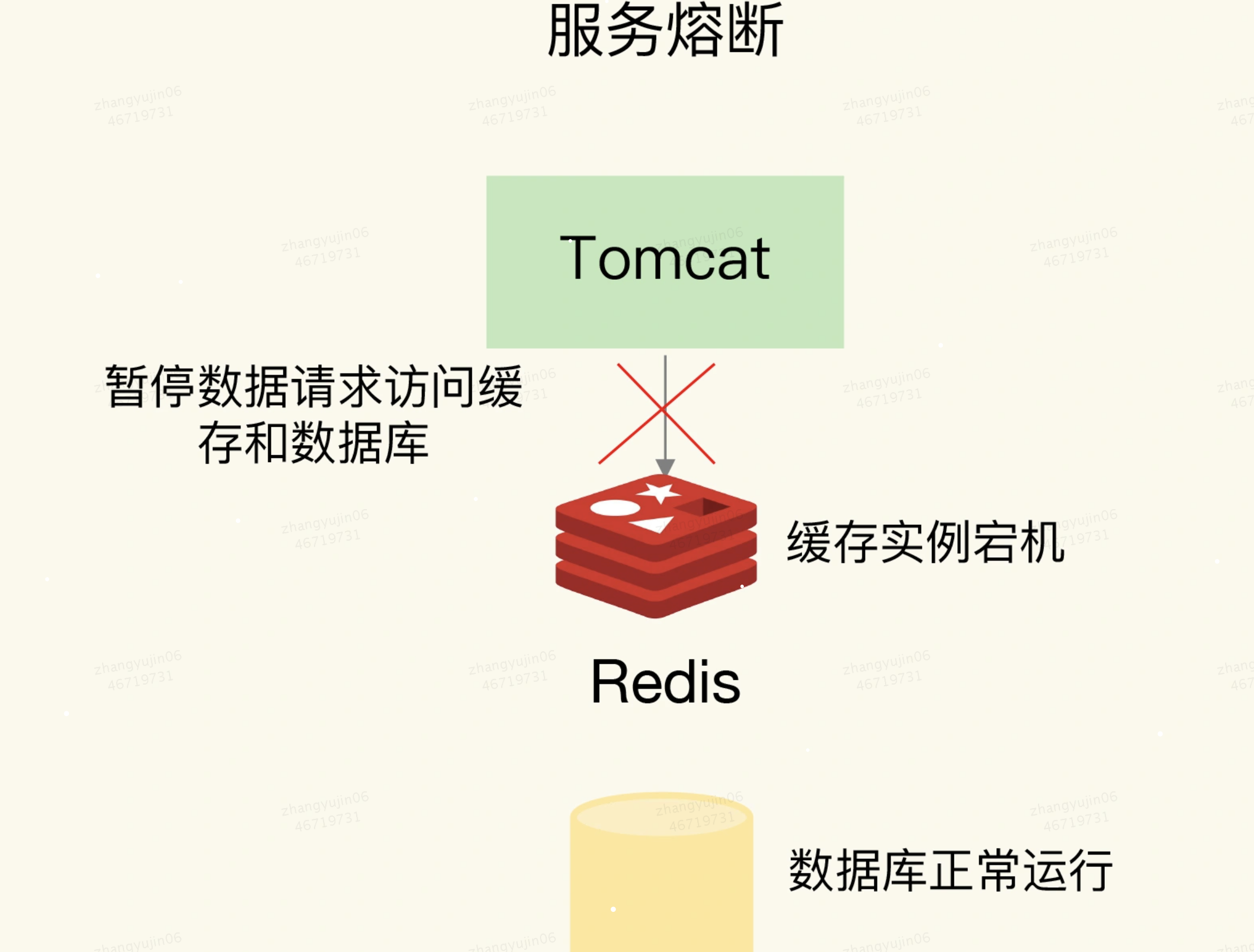
1)方案1:事后诸葛 -> 服务熔断
在业务系统运行时,我们可以监测
Redis缓存所在机器和数据库所在机器的负载指标,例如每秒请求数、CPU利用率、内存利用率等。如果我们发现
Redis缓存实例宕机了,而数据库所在机器的负载压力突然增加(例如每秒请求数激增),此时,就发生缓存雪崩了。大量请求被发送到数据库进行处理。我们可以启动服务熔断机制,暂停业务应用对缓存服务的访问,从而降低对数据库的访问压力,熔断解决,不太友好:
1、所谓的服务熔断,是指在发生缓存雪崩时,为了防止引发连锁的数据库雪崩,甚至是整个系统的崩溃,我们暂停业务应用对缓存系统的接口访问。
2、再具体点说,就是业务应用调用缓存接口时,缓存客户端并不把请求发给
Redis缓存实例,而是直接返回,等到Redis缓存实例重新恢复服务后,再允许应用请求发送到缓存系统。3、这样,就避免了大量请求因缓存缺失,而积压到数据库系统,保证了数据库系统的正常运行。
4、服务熔断虽然可以保证数据库的正常运行,但是暂停了整个缓存系统的访问,对业务应用的影响范围大。我们应该尽可能减少这种影响,所以采用限流机制,
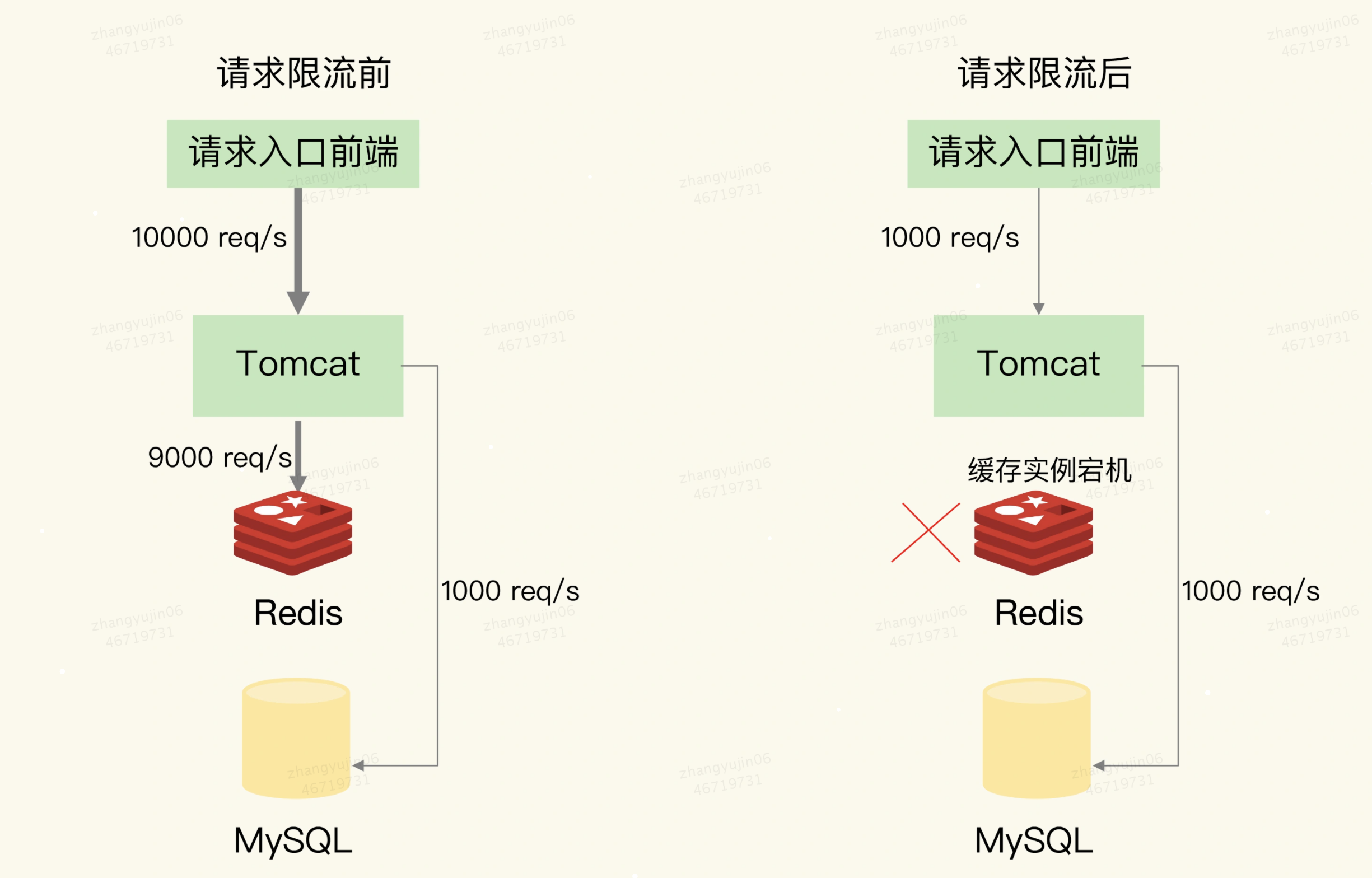
2)方案2:事后诸葛 -> 限流
服务熔断虽然可以保证数据库的正常运行,但是暂停了整个缓存系统的访问,对业务应用的影响范围大。为了尽可能减少这种影响,我们也可以进行请求限流。
这里说的请求限流,就是指,我们在业务系统的请求入口前端控制每秒进入系统的请求数,避免过多的请求被发送到数据库。
举例。假设业务系统正常运行时,请求入口前端允许每秒进入系统的请求是1万个,其中,9000个请求都能在缓存系统中进行处理,只有1000个请求会被应用发送到数据库进行处理。
此时:一旦发生了缓存雪崩,数据库的每秒请求数突然增加到每秒1万个,此时,我们就可以启动请求限流机制,在请求入口前端只允许每秒进入系统的请求数为1000个,再多的请求就会在入口前端被直接拒绝服务。所以,使用了请求限流,就可以避免大量并发请求压力传递到数据库层。
3)、方案3:事前防御 -> Redis高可用集群
通过主从节点的方式构建
Redis缓存高可靠集群。如果Redis缓存的主节点故障宕机了,从节点还可以切换成为主节点,继续提供缓存服务,避免了由于缓存实例宕机而导致的缓存雪崩问题。
3、总结
1、保证使用Redis高可用集群
2、服务系统有限流机制
3、Redis 大面积宕机之后,要有熔断机制
4、缓存时间要设置成随机的
5、支持服务降级,缓存大面积失效后有通过业务优先级进行数据访问
二、缓存击穿
缓存击穿的情况,经常发生在热点数据过期失效时
缓存击穿是指:针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,访问该数据的大量请求,一下子都发送到了后端数据库,导致了数据库压力激增,会影响数据库处理其他请求。
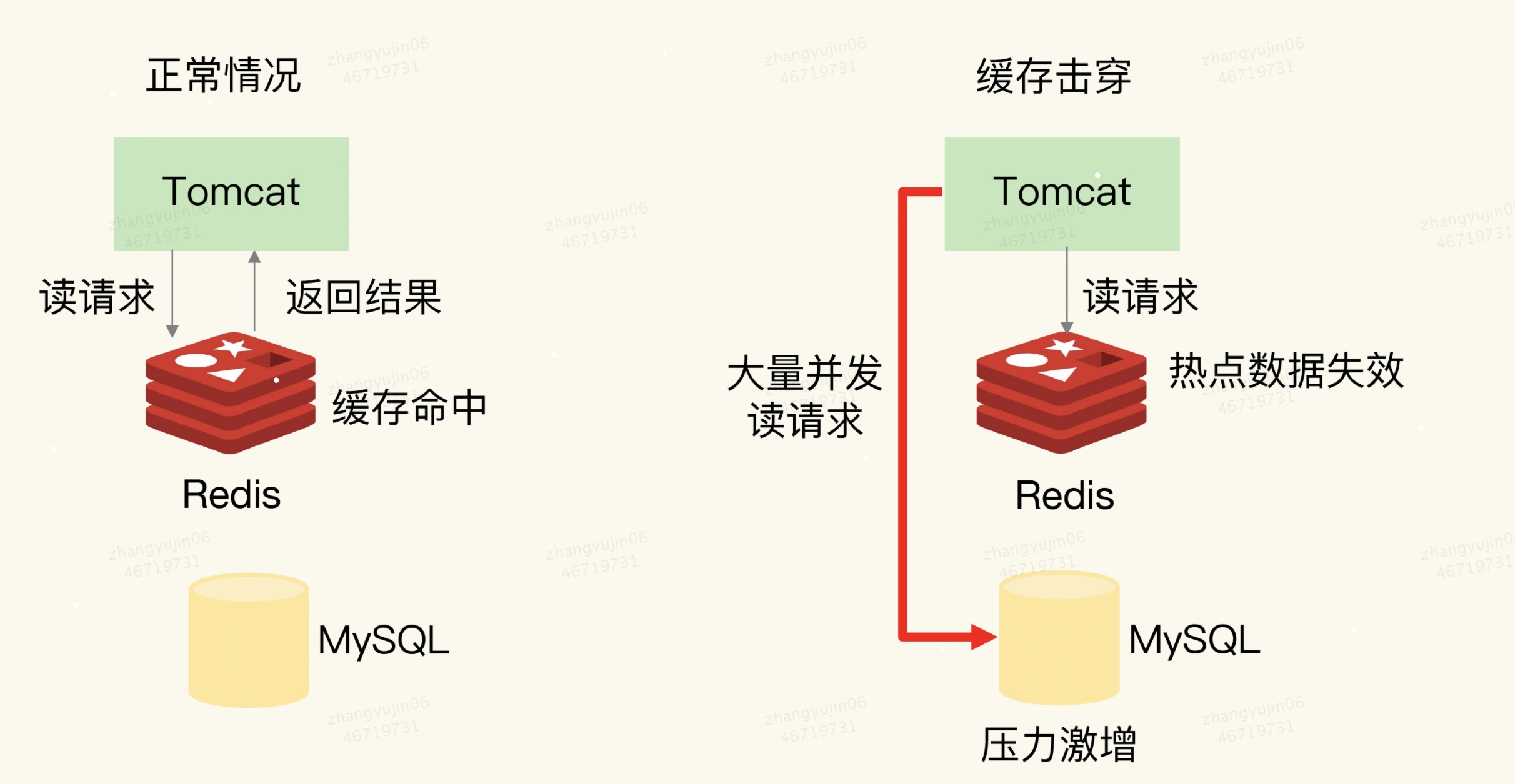
1)方案1:热点数据不设置过期时间
为了避免缓存击穿给数据库带来的激增压力,解决方法也比较直接,对于访问特别频繁的热点数据,我们就不设置过期时间了。这样一来,对热点数据的访问请求,都可以在缓存中进行处理,而
Redis数万级别的高吞吐量可以很好地应对大量的并发请求访问。
2)分布式锁
分布式锁,排队访问
三、缓存穿透
缓存穿透是指:要访问的数据既不在
Redis缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。此时,应用也无法从数据库中读取数据再写入缓存,来服务后续请求,这样一来,缓存也就成了“摆设”,如果应用持续有大量请求访问数据,就会同时给缓存和数据库带来巨大压力
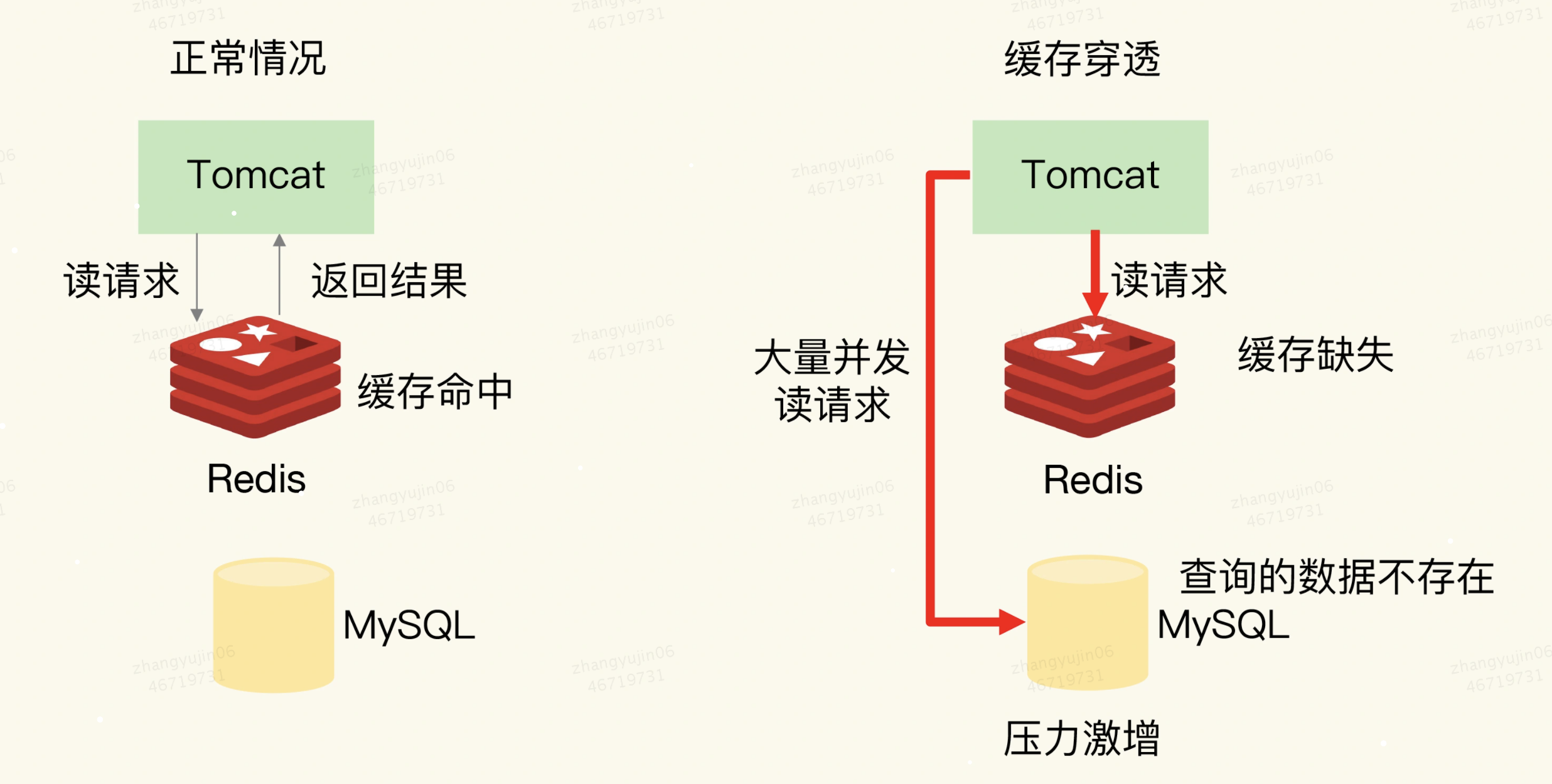
1、原因:
1、业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
2、恶意攻击:专门访问数据库中没有的数据。
2、解决方案:
1)缓存空值或缺省值
一旦发生缓存穿透,我们就可以针对查询的数据,在
Redis中缓存一个空值或是和业务层协商确定的缺省值例如,库存的缺省值可以设为0 或者空字符串。紧接着,应用发送的后续请求再进行查询时,就可以直接从
Redis中读取空值或缺省值,返回给业务应用了,避免了把大量请求发送给数据库处理,保持了数据库的正常运行。
2)方案2:布隆过滤器
bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回,没有的话就是肯定没有。布隆过滤器的关键就在于hash算法和容器大小,要缓存全量的key,这就要求全量的key数量不大,10亿条数据以内最佳,因为10亿条数据大概要占用1.2GB的内存,⬤ 正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。
⬤ 如果不存在,就不用再去数据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询
Redis和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。⬤ 布隆过滤器可以使用
Redis实现,本身就能承担较大的并发访问压力。
3)方案3:请求检测,拦截恶意请求
缓存穿透的一个原因是有大量的恶意请求访问不存在的数据,正常用户是不会这样暴力功击,只有是恶意者才会这样做,可以在网关
NG作一个配置项,为每一个IP设置访问阈值。个有效的应对方案是在请求入口前端,对业务系统接收到的请求进行合法性检测,把恶意的请求,例如请求参数不合理、请求参数是非法值、请求字段不存在 直接过滤掉,不让它们访问后端缓存和数据库。这样一来,也就不会出现缓存穿透问题了。
a、guava实现的布隆过滤器
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
</dependencies>
public class BloomFilterTest {
private static final int capacity = 1000000;
private static final int key = 999998;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), capacity);
static {
for (int i = 0; i < capacity; i++) {
bloomFilter.put(i);
}
}
public static void main(String[] args) {
/*返回计算机最精确的时间,单位微妙*/
long start = System.nanoTime();
if (bloomFilter.mightContain(key)) {
System.out.println("成功过滤到" + key);
}
long end = System.nanoTime();
System.out.println("布隆过滤器消耗时间:" + (end - start));
int sum = 0;
for (int i = capacity + 20000; i < capacity + 30000; i++) {
if (bloomFilter.mightContain(i)) {
sum = sum + 1;
}
}
System.out.println("错判率为:" + sum);
}
}
成功过滤到999998
布隆过滤器消耗时间:215518
错判率为:318
可以看到,100w个数据中只消耗了约0.2毫秒就匹配到了key,速度足够快。然后模拟了1w个不存在于布隆过滤器中的key,匹配错误率为318/10000,也就是说,出错率大概为3%,跟踪下BloomFilter的源码发现默认的容错率就是0.03:
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
四、总结
服务熔断、服务降级、请求限流这些方法都是属于“有损”方案,在保证数据库和整体系统稳定的同时,会对业务应用带来负面影响。
⬤ 例如使用服务降级时,有部分数据的请求就只能得到错误返回信息,无法正常处理。
⬤ 如果使用了服务熔断,那么,整个缓存系统的服务都被暂停了,影响的业务范围更大。
⬤ 如果使用了限流机制后,整个业务系统的吞吐率会降低,能并发处理的用户请求会减少,会影响到用户体验。
所以,建议是,尽量使用预防式方案:
⬤ 针对缓存雪崩,合理地设置数据过期时间,以及搭建高可靠缓存集群;
⬤ 针对缓存击穿,在缓存访问非常频繁的热点数据时,不要设置过期时间;
⬤ 针对缓存穿透,提前在入口前端实现恶意请求检测,或者规范数据库的数据删除操作,避免误删除。
五、热点Key
Hotkey,即热点key,指的是在一段时间内,该key的访问量远远高于其他的rediskey, 导致大部分的访问流量在经过分片之后,都集中访问到某一个redis实例上。
Hotkey会将请求全部打在一个节点上,容易造成性能瓶颈;若value也比较大,也会造成网卡达到瓶颈。需要发现hotkey,并进行相应处理(如限流,打散处理)。因此需要开发自动发现
hotkey的功能,以便对hotkey可以进行相应处理。
1、如何发现热点Key
1)凭借业务经验,进行预估哪些是热 key
正常开发中,热点
key,在创造之初就应该能知道了 比如:某商品在做秒杀,那这个商品的key就可以判断出是热key。但是缺点很明显,并非所有业务都能预估出哪些
key是热key。
2)指标打点
使用缓存的地方进行打点,打点看数量其实也能很快得到
3)用 redis 自带命令(无)
问题1:Redis 本身能直接识别热 key 吗?
答案:不能,Redis 官方没有提供内置的“热 key 扫描”功能(比如类似 --bigkeys 的 --hotkeys 是不存在的)。
| 命令 | 是否存在 | 说明 |
|---|---|---|
✅ redis-cli --bigkeys |
存在 | Redis 官方支持,用于扫描大 key(自 Redis 2.8 起) |
❌ redis-cli --hotkeys |
不存在 | Redis 没有这个命令,官方未提供热 key 扫描功能 |
问题2:那怎么识别热 key?
答案:必须借助外部手段
2、解决热点Key
1)热点key打散
找到对应的热点
key,将这些热key进行分散处理 (和大key解决方案有点像)比如一个热
key名字叫hotkey,可以被分散为hotkey#1、hotkey#2、hotkey#3,……hotkey#n,这n个key分散存在多个缓存节点,然后client端请求时,随机访问其中某个后缀的hotkey,这样就可以把热key的请求打散,避免一个缓存节点过载
2)利用二级缓存
比如利用
ehcache,或者一个HashMap都可以。在你发现热key以后,把热key加载到系统的JVM中。 针对这种热key请求,会直接从jvm中取,而不会走到redis层。假设此时有十万个针对同一个
key的请求过来,如果没有本地缓存,这十万个请求就直接怼到同一台redis上了。 现在假设,你的应用层有50台机器,OK,你也有jvm缓存了。这十万个请求平均分散开来,每个机器有2000个请求,会从JVM中取到value值,然后返回数据。避免了十万个请求怼到同一台redis上的情形。

