数据库主从同步一致性
前言
Github:https://github.com/HealerJean
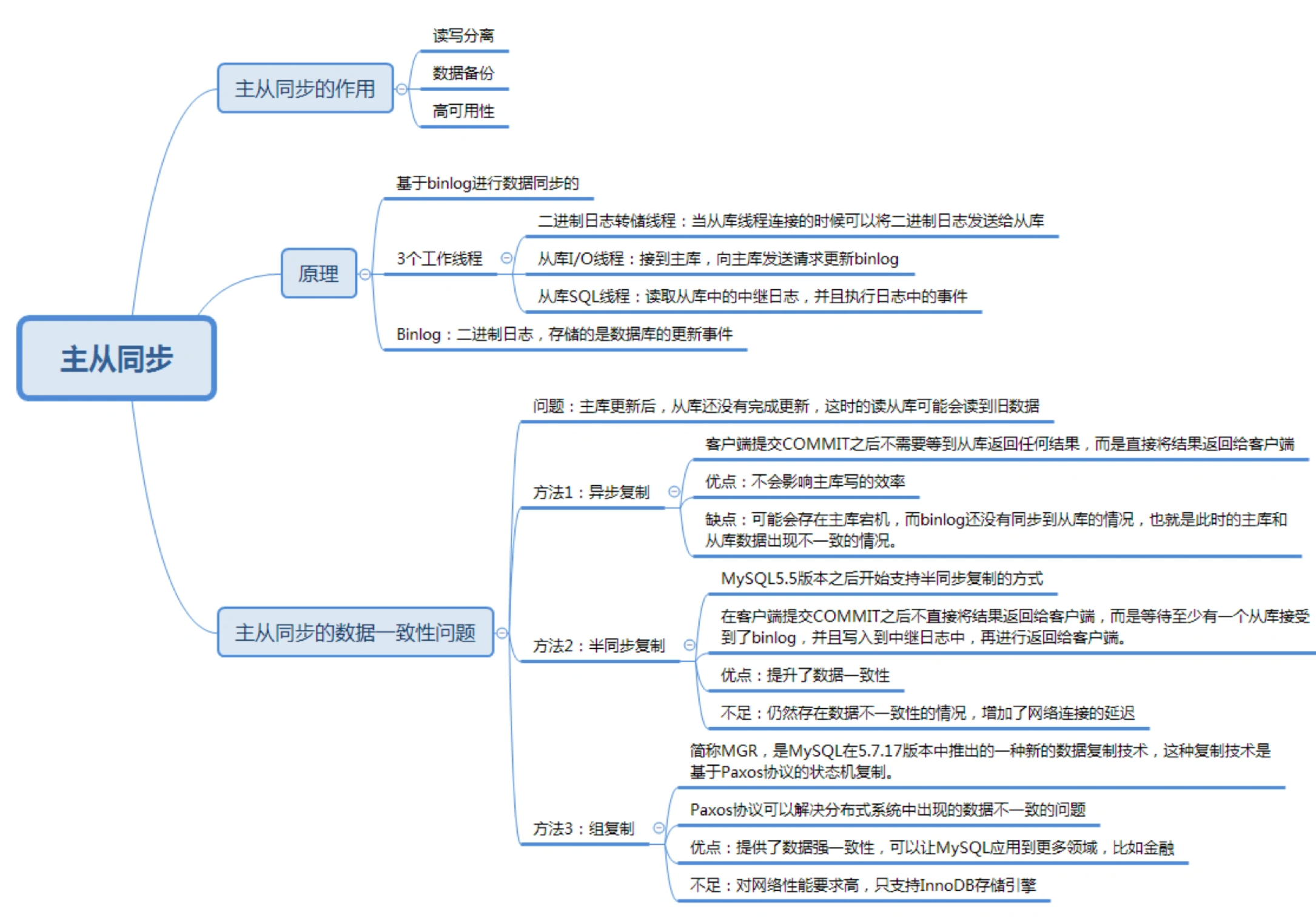
1、主从同步的作用是什么
1.1、读写分离
首先是可以读写分离。我们可以通过主从复制的方式来同步数据,然后通过读写分离提高数据库并发处理能力。
解决问题:简单来说就是同一份数据被放到了多个数据库中,其中一个数据库是
Master主库,其余的多个数据库是Slave从库。当主库进行更新的时候,会自动将数据复制到从库中,而我们在客户端读取数据的时候,会从从库中进行读取,也就是采用读写分离的方式。1、互联网的应用往往是一些“读多写少”的需求,采用读写分离的方式,可以实现更高的并发访问。原本所有的读写压力都由一台服务器承担,现在有多个“兄弟”帮忙处理读请求,这样就减少了对后端大哥(Master)的压力。
2、同时,我们还能对从服务器进行负载均衡,让不同的读请求按照策略均匀地分发到不同的从服务器上,让读取更加顺畅。
3、读取顺畅的另一个原因,就是减少了锁表的影响,比如我们让主库负责写,当主库出现写锁的时候,不会影响到从库进行
SELECT的读取。
1.2、数据备份+高可用性
数据备份:我们通过主从复制将主库上的数据复制到了从库上,相当于是一种热备份机制,也就是在主库正常运行的情况下进行的备份,不会影响到服务。
高可用性:数据备份实际上是一种冗余的机制,通过这种冗余的方式可以换取数据库的高可用性,也就是当服务器出现故障或宕机的情况下,可以切换到从服务器上,保证服务的正常运行。
2、主从同步的原理
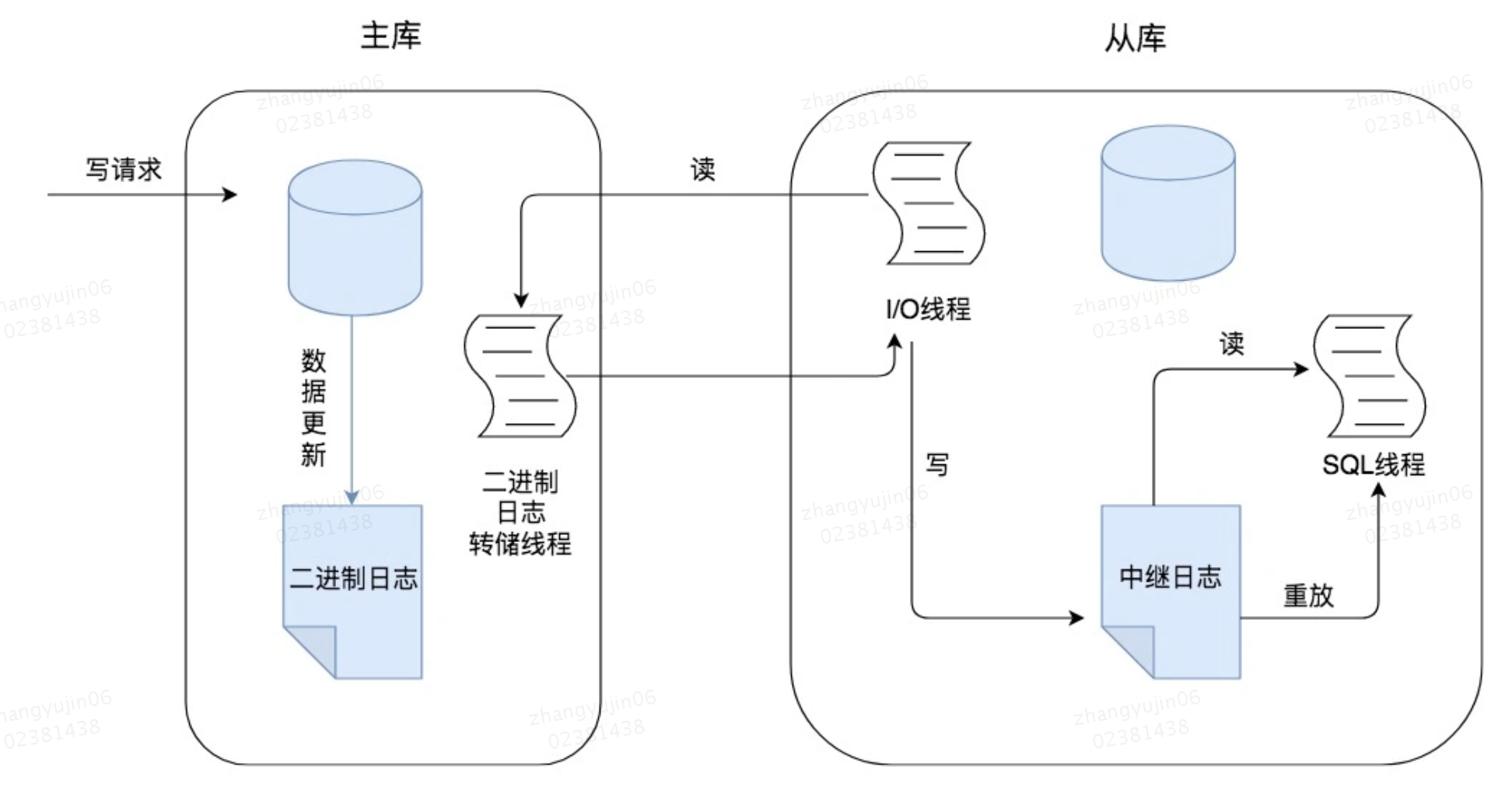
提到主从同步的原理,我们就需要了解在数据库中的一个重要日志文件,那就是Binlog二进制日志,它记录了对数据库进行更新的事件。实际上主从同步的原理就是基于
Binlog进行数据同步的。在主从复制过程中,会基于3个线程来操作,一个主库线程,两个从库线程。
二进制日志转储线程(Binlog dump thread)是一个主库线程。当从库线程连接的时候,主库可以将二进制日志发送给从库,当主库读取事件的时候,会在Binlog上加锁,读取完成之后,再将锁释放掉。
从库I/O线程会连接到主库,向主库发送请求更新Binlog。这时从库的I/O线程就可以读取到主库的二进制日志转储线程发送的Binlog更新部分,并且拷贝到本地形成中继日志(Relay log)。
从库SQL线程会读取从库中的中继日志,并且执行日志中的事件,从而将从库中的数据与主库保持同步。
3、如何解决主从同步的数据一致性问题
进行主从同步的内容是二进制日志,它是一个文件,在进行网络传输的过程中就一定会存在延迟(比如500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的数据不一致性问题。比如我们对一条记录进行更新,这个操作是在主库上完成的,而在很短的时间内(比如
100ms)又对同一个记录进行了读取,这时候从库还没有完成数据的更新,那么我们通过从库读到的数据就是一条旧的记录。
3.1、数据库层面
一致性从弱到强来进行划分,有以下3种复制方式
3.1.1、异步复制
异步模式就是客户端提交
COMMIT之后不需要等从库返回任何结果,而是直接将结果返回给客户端,这样做的好处是不会影响主库写的效率,但可能会存在主库宕机,而Binlog还没有同步到从库的情况,也就是此时的主库和从库数据不一致。这时候从从库中选择一个作为新主,那么新主则可能缺少原来主服务器中已提交的事务。所以,这种复制模式下的数据一致性是最弱的。
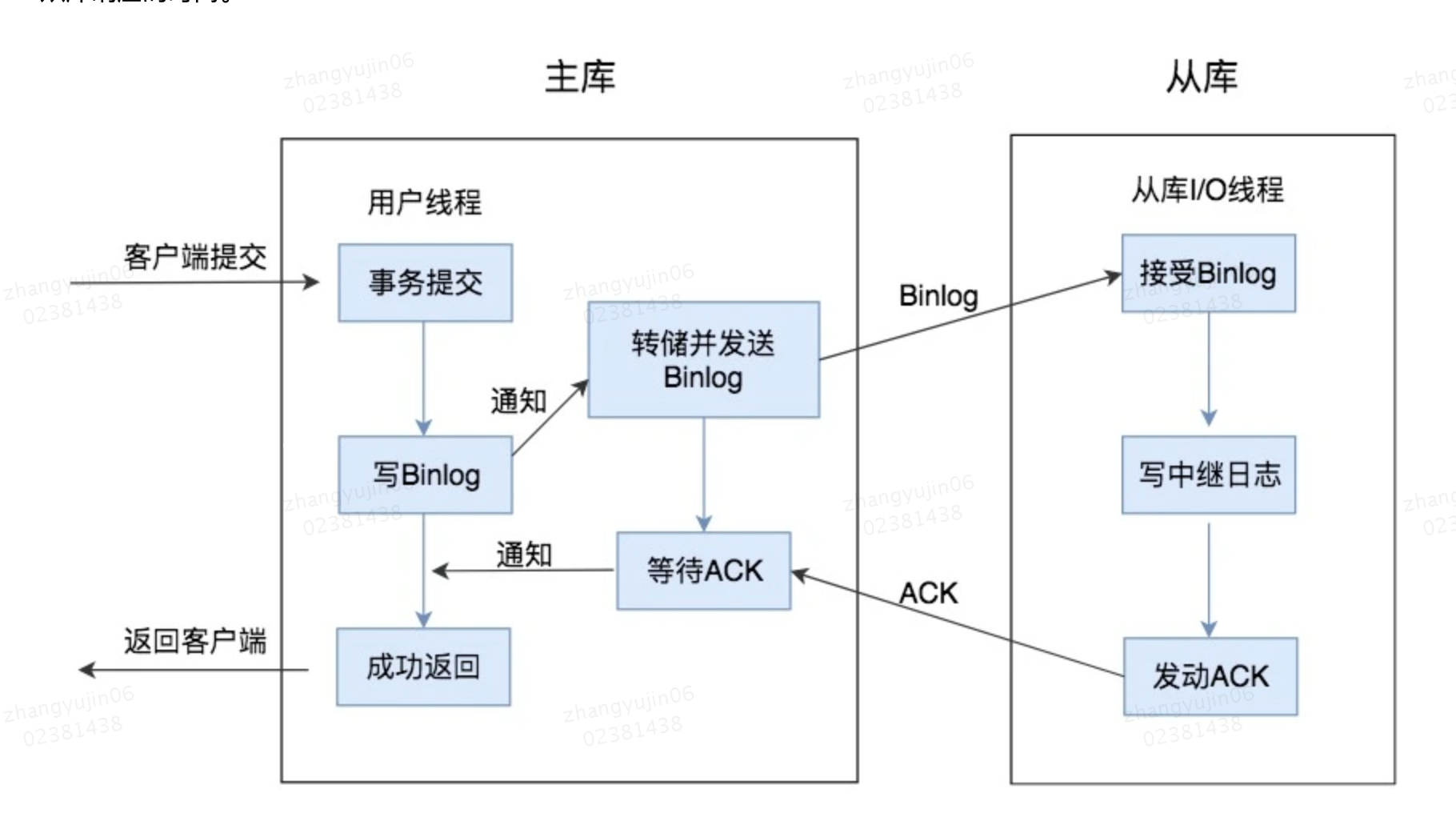
3.1.2、半同步复制
MySQL5.5版本之后开始支持半同步复制的方式。原理是在客户端提交COMMIT之后不直接将结果返回给客户端,而是等待至少有一个从库接收到了Binlog,并且写入到中继日志中,再返回给客户端。这样做的好处就是提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率。在
MySQL5.7版本中还增加了一个rpl_semi_sync_master_wait_for_slave_count参数,我们可以对应答的从库数量进行设置,默认为1,也就是说只要有1个从库进行了响应,就可以返回给客户端。如果将这个参数调大,可以提升数据一致性的强度,但也会增加主库等待从库响应的时间。
3.1.3、组复制 (有机会再看吧)
组复制技术,简称
MGR(MySQL Group Replication)。是MySQL在5.7.17版本中推出的一种新的数据复制技术,这种复制技术是基于Paxos协议的状态机复制。我刚才介绍的异步复制和半同步复制都无法最终保证数据的一致性问题,半同步复制是通过判断从库响应的个数来决定是否返回给客户端,虽然数据一致性相比于异步复制有提升,但仍然无法满足对数据一致性要求高的场景,比如金融领域。
MGR很好地弥补了这两种复制模式的不足。
3.2、应用层面
3.2.1、忽略
如果业务能接受,最推崇此法。
3.2.2、强制读主(重要场景必须使用)
很常见的微服务架构,可以避免数据库主从一致性问题。
1、使用一个高可用主库提供数据库服务
2、读和写都落到主库上
3、采用缓存来提升系统读性能
3.2.3、选择性读主
强制读主过于粗暴,毕竟只有少量写请求,很短时间,可能读取到脏数据。有没有可能实现,只有这一段时间,读主呢? 可以利用一个缓存记录必须读主的数据。
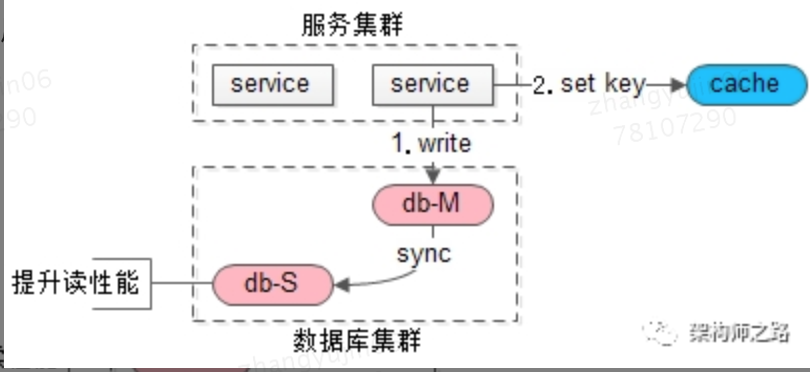
4.2.3.1、写请求
1、写主库
2、将哪个库,哪个表,哪个主键三个信息拼装一个
key设置到cache里,这条记录的超时时间,设置为“主从同步时延”(画外音:key的格式为“db:table:PK”,假设主从延时为1s,这个key的cache超时时间也为1s。)
4.2.3.2、读请求
当读请求发生时:这是要读哪个库,哪个表,哪个主键的数据呢,也将这三个信息拼装一个key,到cache里去查询,如果,
1、cache里有这个key,说明1s内刚发生过写请求,数据库主从同步可能还没有完成,此时就应该去主库查询
2、cache里没有这个key,说明最近没有发生过写请求,此时就可以去从库查询
以此,保证读到的一定不是不一致的脏数据。

