Redis原理之_鞭辟入里_线程IO模型
前言
Github:https://github.com/HealerJean
1、引入
问题1、Redis 单线程为什么还能这么快
Redis 将所有数据都放在内存,用一个单线程对外提供服务,单个节点在跑满一个
CPU核心的情 况下可以达到了10w/s的超高QPS。
答案:如下
1、它所有的数据都在内存中,所有的运算都是内存级别的运算。正因为 Redis 是单线 程,所以要小心使用 Redis 指令,对于那些时间复杂度为 O(n) 级别的指令,一定要谨慎使 用,一不小心就可能会导致 Redis 卡顿
2、单线程操作,避免了资源的竞争
**3、采用了非阻塞IO多路复用机制 **
问题2:为什么 Redis 中要使用 I/O 多路复用这种技术呢?
答案:Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的。
问题2、Redis 单线程如何处理那么多的并发客户端连接
答案:这个问题,有很多中高级程序员都无法回答,因为他们没听过多路复用这个词汇,不知 道 select 系列的事件轮询 API,没用过非阻塞 IO,所以下面来讲解这个东西。
问题3:什么是套接字?
套接字:套接字 (socket) 是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。
总之,套接字 Socket=(IP地址:端口号),套接字的表示方法是点分十进制的IP地址后面写上端口号,中间用冒号或逗号隔开。每一个传输层连接唯一地被通信两端的两个端点(即两个套接字)所确定。
2、几种 I/O 模型
1、同步阻塞
IO(Blocking IO):即传统的IO模型。2、同步非阻塞
IO(Non-blocking IO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。3、
IO多路复用(IO Multiplexing):即经典的Reactor设计模式,有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。4、异步
IO(Asynchronous IO):即经典的Proactor设计模式,也称为异步非阻塞IO。
2.1、阻塞IO
当我们调用套接字的读写方法(当使用
read或者write对某一个文件描述符进行读写时),默认它们是阻塞的,比如1、
read方法要传递进去一个参数n,表示读取这么多字节后再返回,如果没有读够,线程就会卡在那里,直到新的数据到来或者 连接关闭了,read方法才可以返回,线程才能继续处理。2、
write方法一般来说不会阻塞,除非内核为套接字分配的写缓冲区已经满了,write方法就会阻塞,直到缓存区中有空闲空间挪出来了。阻塞期间,整个
Redis服务就不会对其它的操作作出响应,导致整个服务不可用。这也就是传统意义上的,也就是我们在编程中使用最多的阻塞模型:
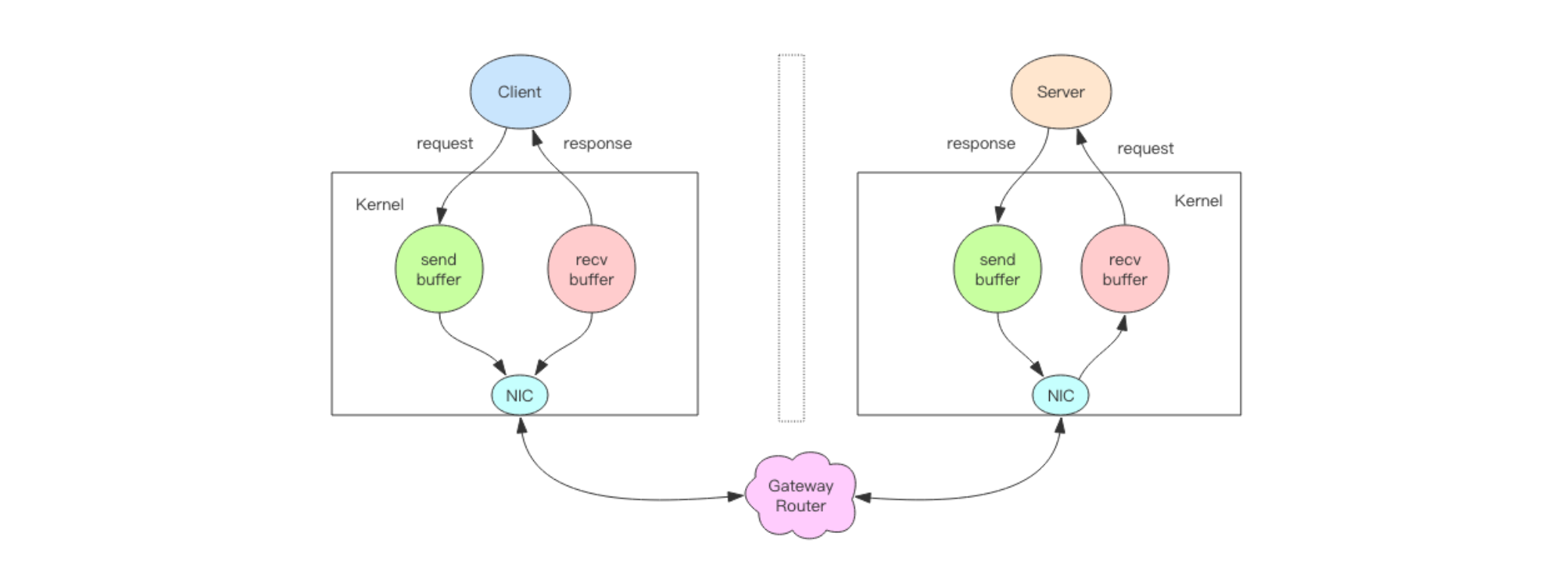
2.1.1、使用分析
1、如果接受到了一个客户端连接而不采用对应的一个线程去处理的话,首先
serverSocket.accept(); 无法去获取其它连接2、
inputStream.read()可以看到获取到数据后需要处理完成后才能处理接收下一份数据,正因如此在阻塞I/O模型的场景下我们需要为每一个客户端连接创建一个线程去处理3、阻塞模型虽然开发中非常常见也非常易于理解,但是由于它会影响其他
FD对应的服务,所以在需要处理多个客户端任务的时候,往往都不会使用阻塞模型。
/**
* 1、创建 ServerSocket
* 2、新建一个线程用于接收客户端连接 (伪异步 IO)
* 3、serverSocket.accept() 建立连接sock连接
* 4、每一个新来的连接给其创建一个线程去处理
* 5、阻塞式获取数据直到客户端断开连接
* 6、读取数据并处理
*/
@Test
public void test() throws IOException {
// 1、创建 ServerSocket
ServerSocket serverSocket = new ServerSocket(9999);
// 2、新建一个线程用于接收客户端连接 (伪异步 IO)
new Thread(() -> {
while (true) {
log.info("开始阻塞, 等待客户端连接");
try {
// 3、 serverSocket.accept() 建立连接sock连接
Socket socket = serverSocket.accept();
// 4、每一个新来的连接给其创建一个线程去处理
new Thread(() -> {
byte[] data = new byte[1024];
int len = 0;
log.info("客户端连接成功,阻塞等待客户端传入数据");
try {
// 5、 阻塞式获取数据直到客户端断开连接
InputStream inputStream = socket.getInputStream();
// 6、读取数据并处理
while ((len = inputStream.read(data)) != -1) {
log.info(new String(data, 0, len));
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
2.2、非阻塞IO
非阻塞
IO在套接字对象上提供了一个选项Non_Blocking,当这个选项打开时,读写方法不会阻塞,而是能读多少读多少,能写多少写多少。1、能读多少取决于内核为套接字分配的 读缓冲区内部的数据字节数。
2、能写多少取决于内核为套接字分配的 写缓冲区的空闲空间字节数。
3、读方法和写方法都会通过返回值来告知程序实际读写了多少字节。
有了非阻塞
IO意味着线程在读写IO时可以不必再阻塞了,读写可以瞬间完成然后线程可以继续干别的事了。
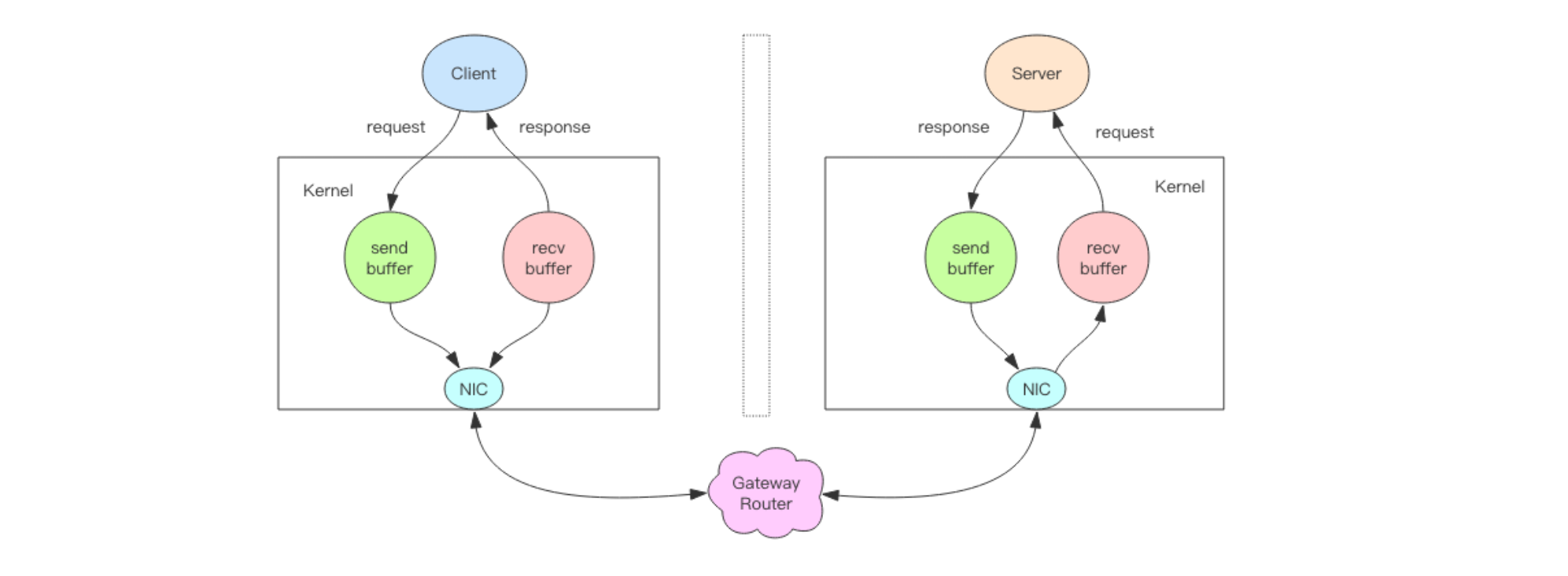
2.2.1、使用分析
非阻塞
IO有个问题1、要读数据,结果读了一部分就返回了,线程如何知道何时才应该继续读。也就是当数据到来时,线程如何得到通知。
2、要写数据,如果缓冲区满 了,写不完,剩下的数据何时才应该继续写,线程也应该得到通知。
在非阻塞·
I/O这种场景下需要我们不断的去轮询,也是会消耗大量的CPU资源的,一般很少采用这种方式,所以才出现了IO多路复用。1、在
Java中的NIO(非阻塞I/O,New I/O) 底层是通过多路复用I/O模型实现的。2、现实的场景也是诸如
netty,redis,nginx,nodejs都是采用的多路复用I/O模型
这里手写一段伪代码来看下:
Socket socket = serverSocket.accept();
// 不断轮询内核,哪个 socket 的数据是否准备好了
while (true) {
data = socket.read();
if (data != BWOULDBLOCK) {
// 表示获取数据成功
doSomething();
}
}
2.3、多路复用IO
简单理解就是:一个服务端进程可以同时处理多个套接字描述符。
Java中的NIO就是采用的多路复用机制,他在不同的操作系统有不同的实现,在windows上采用的是select,在unix/linux上是epoll。而poll模型是对select稍许升级大致相同。◯ 多路:多个客户端连接(连接就是套接字描述符)
◯ 复用:使用单进程就能够实现同时处理多个客户端的连接
通过增加进程和线程的数量来并发处理多个套接字,免不了上下文切换的开销,而
IO多路复用只需要一个进程就能够处理多个套接字,从而解决了上下文切换的问题。其发展可以分
select->poll→epoll三个阶段来描述。
⬤ 发展史
1、最先出现的是 select 。后由于 select 的一些痛点比如它在 32 位系统下,单进程支持最多打开 1024 个文件描述符(linux 对 IO 等操作都是通过对应的文件描述符实现的, socket 对应的是 socket 文件描述符)
2、poll 对其进行了一些优化,比如突破了 1024 这个限制,他能打开的文件描述符不受限制(但还是要取决于系统资源),但是基本上差不多,
3、上述 poll 中模型都有一个很大的性能问题导致产生出了 epoll。后面会详细分析
select 就是轮询,在 Linux 上限制个数一般为 1024 个
poll 解决了 select 的个数限制,但是依然是轮询
epoll 解决了个数的限制,同时解决了轮询的方式
2.3.1、如何简单理解 select/poll/epoll
场景:领导分配员工开发任务,有些员工还没完成。如果领导要每个员工的工作都要验收
check,那在未完成的员工那里,只能阻塞等待,等待他完成之后,再去check下一位员工的任务,造成性能问题。
2.3.1.1、select
解决思路:领导找个
Team Leader(后文简称TL),负责代自己check每位员工的开发任务解决方案:
TL的做法是:遍历问各个员工“完成了么?”,完成的待CR check无误后合并到Git分支,对于其他未完成的,休息一会儿后再去遍历….
1、select 函数:
select函数监视的文件描述符分 3 类,分别是writefds、readfds、和exceptfds。1、调用后
select函数会阻塞,直到有描述符就绪(有数据可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。2、当
select函数返回后,可以通过遍历fdset,来找到就绪的描述符。具体过程:
1、最简单的事件轮询
API是select函数,它是操作系统提供给用户程序的API。输入是读写描述符列表read_fds&write_fds,输出是与之对应的可读可写事件对应的文件描述符列表。2、同时还提供了一个
timeout参数,如果没有任何事件到来,那么就最多 等待timeout时间,线程处于阻塞状态。一旦期间有任何事件到来,就可以立即返回。时间过 了之后还是没有任何事件到来,也会立即返回。3、拿到事件后,线程就可以继续挨个处理相应 的事件。处理完了继续过来轮询。于是线程就进入了一个死循环,我们把这个死循环称为事件循环,一个循环为一个周期。
int select(int maxfdp1,fd_set *readset,fd_set *writeset,fd_set *exceptset,const struct timeval *timeout);
2、select存在的问题:
select具有良好的跨平台支持,其缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,select系统调用的性能在描述符特别多时性能会非常差。
linux对IO等操作都是通过对应的文件描述符实现的socket对应的是socket文件描述符
poll对其进行了一些优化,比如突破了1024这个限制,他能打开的文件描述符不受限制(但还是要取决于系统资源)
1、这个 TL 存在能力短板问题,最多只能管理 1024 个员工
2、很多员工的任务没有完成,而且短时间内也完不成的话,TL 还是会不停的去遍历问询,影响效率。
2.3.1.2、poll
解决思路/方案:换一个能力更强的
New Team Leader(后文简称 NTL),可以管理更多的员工,这个NTL可以理解为poll。
1、poll函数
poll改变了文件描述符集合的描述方式,使用了pollfd结构而不是select的fd_set结构,使得poll支持的文件描述符集合限制远大于select的1024。
intpoll(structpollfd*fds, nfds_t nfds,int timeout);
typedef struct pollfd{
int fd; // 需要被检测或选择的文件描述符
short events; // 对文件描述符fd上感兴趣的事件
short revents; // 文件描述符fd上当前实际发生的事件
} pollfd_t;
2.3.1.3、epoll
解决思路:在上一步
poll方式的NTL基础上,改进一下NTL的办事方法解决方案:遍历一次所有员工,如果任务没有完成,告诉员工待完成之后,其应该做 xx 操作(制定一些列的流程规范)。这样
NTL只需要定期check指定的关键节点就好了。这就是epoll。
epoll函数
epoll是Linux内核为处理大批量文件描述符而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。
intepoll_create(int size);
intepoll_ctl(int epfd,int op,int fd,struct epoll_event *event);
intepoll_wait(int epfd,struct epoll_event * events,int maxevents,int timeout);
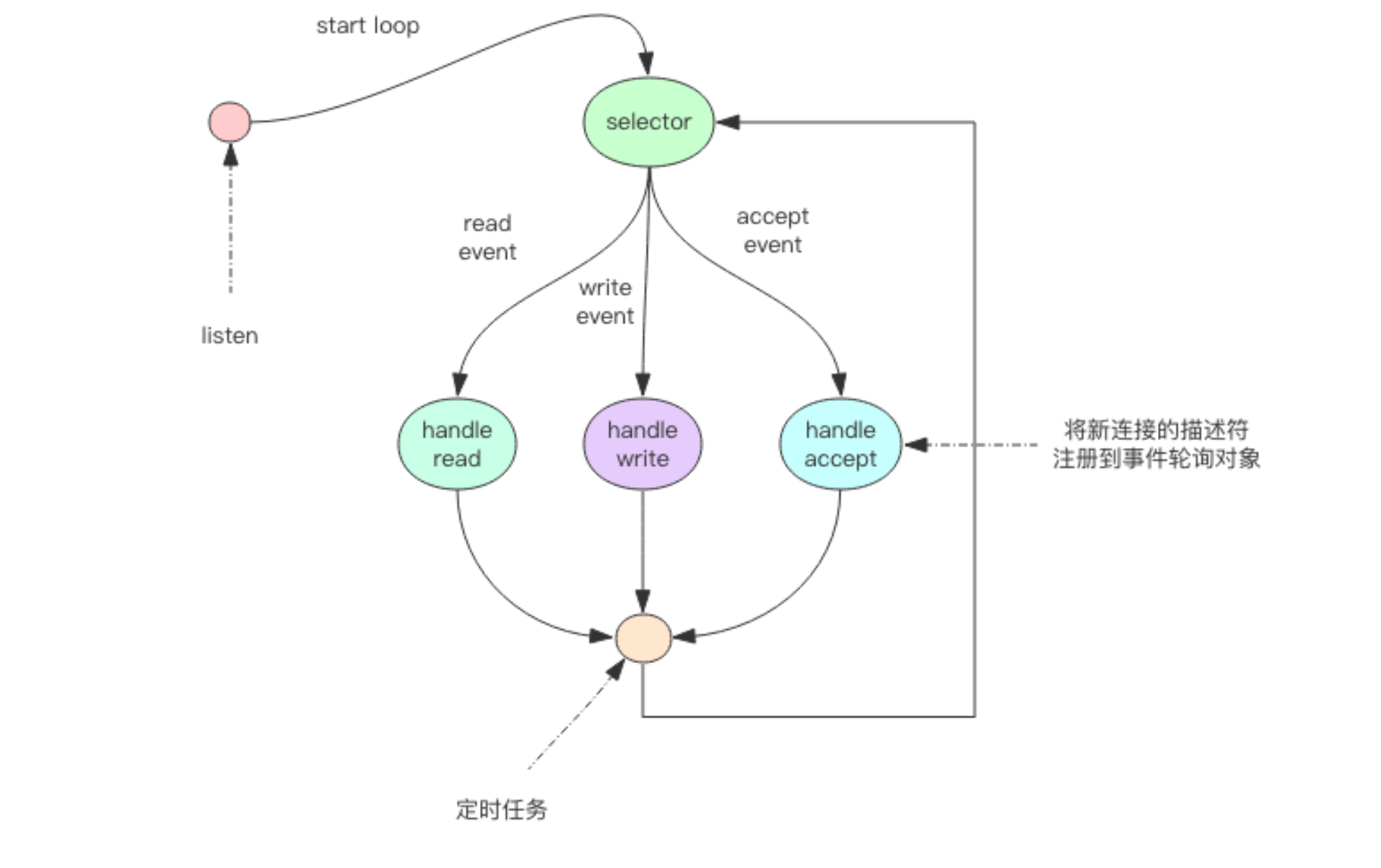
4、指令队列
Redis会将每个客户端套接字都关联一个指令队列。客户端的指令通过队列来排队进行顺序处理,先到先服务。
5、响应队列
Redis同样也会为每个客户端套接字关联一个响应队列。Redis服务器通过响应队列来将指令的返回结果回复给客户端。1、如果队列为空,那么意味着连接暂时处于空闲状态,不需要去获取写事件(因为是空闲哦),也就是可以将当前的客户端描述符从
write_fds里面移出来。2、等到队列有数据 了,再将描述符放进去。避免
select系统调用立即返回写事件(Redis发起),结果发现没什么数据可以 写。出这种情况的线程会飙高CPU。
6、定时任务
服务器处理要响应
IO事件外,还要处理其它事情。比如定时任务就是非常重要的一件 事。
问题1:如果线程阻塞在 select 系统调用上,定时任务将无法得到准时调度。那 Redis 是如何解 决这个问题的呢?
1、Redis 的定时任务会记录在一个称为最小堆的数据结构中。
2、这个堆中,最快要执行的任务排在堆的最上方。在每个循环周期,Redis 都会将最小堆里面已经到点的任务立即进行处理。
3、处理完毕后,将最快要执行的任务还需要的时间记录下来,这个时间就是 select 系统调用的 timeout 参数。因为 Redis 知道未来 timeout 时间内,没有其它定时任务需要处理,所以可以安心睡眠 timeout 的时间。

