项目经验_之_位图BitMap
前言
Github:https://github.com/HealerJean
一、位图的简单计算
1、java
1)普通-增&删&查
package com.hlj.util.Z005BitSet;
import lombok.extern.slf4j.Slf4j;
/**
* @author zhangyujin
* @date 2022/6/30 18:02.
*/
@Slf4j
public class StatusEnums {
private final static long INIT = 1L << 0;
private final static long CHSI_VERIFY = 1L << 1;
private final static long GRADUATE = 1L << 2;
static {
System.out.println(Long.toBinaryString(INIT));
System.out.println(Long.toBinaryString(CHSI_VERIFY));
System.out.println(Long.toBinaryString(GRADUATE));
System.out.println();
}
/**
* 是否包含状态
*
* @param holder 当前状态
* @param position 标志位状态
* @return
*/
public static boolean hasStatus(long holder, long position) {
return (holder & position) == position;
}
/**
* 添加状态
*
* @param holder 当前状态
* @param position 添加状态标志位
* @return 新状态
*/
public static long addStatus(long holder, long position) {
if (hasStatus(holder, position)) {
return holder;
}
return holder | position;
}
/**
* 移除状态
*
* @param holder 当前状态
* @param position 移除状态标志位
* @return 新状态
*/
public static long removeStatus(long holder, long position) {
if (!hasStatus(holder, position)) {
return holder;
}
//异或移除
return holder ^ position;
}
public static void main(String[] args) {
long holder = 7L;
System.out.println(Long.toBinaryString(holder));
//0111
System.out.println(StatusEnums.hasStatus(holder, INIT));
// true -> 0001 在 0111 中
System.out.println(StatusEnums.hasStatus(holder, CHSI_VERIFY));
// true -> 0010 在 0111 中
System.out.println(StatusEnums.hasStatus(holder, GRADUATE));
// tuue -> 0100 在 0111 中
holder = StatusEnums.removeStatus(holder, INIT);
holder = StatusEnums.removeStatus(holder, CHSI_VERIFY);
holder = StatusEnums.removeStatus(holder, GRADUATE);
System.out.println(Long.toBinaryString(holder));
//0000
System.out.println(StatusEnums.hasStatus(holder, INIT));
// false -> 0001 不在 0111 中
System.out.println(StatusEnums.hasStatus(holder, CHSI_VERIFY));
// false -> 0010 不在 0111 中
System.out.println(StatusEnums.hasStatus(holder, GRADUATE));
// false -> 0100 不在 0111 中
}
}
a、场景-模拟签到
package com.hlj.util.Z005BitSet;
import java.util.*;
/**
* @author zhangyujin
* @date 2022/6/30 18:15.
*/
public class Sign {
//int最多可以容纳32位,0b表示需jdk1.8+支持,左边第一位永远为0,即正整数,无日期含义;右边31位表示日期,从左到右1-31天
private final static int monthSignRecord = 0b01111111111111111111111111111000;
private final static int DAY28 = 0x7ffffff8;
private final static int DAY29 = 0x7ffffffc;
private final static int DAY30 = 0x7ffffffe;
private final static int DAY31 = 0x7fffffff;
private final static int MONTH_MODEL = 0x40000000;
private final static Calendar CALENDAR = Calendar.getInstance(Locale.CHINA);
/**
* 签到总数
*
* @param holder 签到记录
* @return
*/
public static int signCount(int holder) {
return Integer.bitCount(holder);
}
/**
* 获取指定月是否全签到
*
* @param holder 签到记录
* @return
*/
public static boolean isSignFullInFixedMonth(int holder, int month) {
CALENDAR.set(Calendar.MONTH, month - 1);
int days = CALENDAR.getActualMaximum(Calendar.DATE);
switch (days) {
case 28:
return (holder & DAY28) == DAY28;
case 29:
return (holder & DAY29) == DAY29;
case 30:
return (holder & DAY30) == DAY30;
case 31:
return (holder & DAY31) == DAY31;
}
throw new IllegalArgumentException("month is illegal");
}
/**
* 获取指定月漏签次数
*
* @param holder 签到记录
* @return
*/
public static int unSignCountInFixedMonth(int holder, int month) {
// java 月份从0开始算,因此传入的月份需要减去1
CALENDAR.set(Calendar.MONTH, month - 1);
return CALENDAR.getActualMaximum(Calendar.DATE) - Integer.bitCount(holder);
}
/**
* 指定天是否签到
*
* @param holder 当前签到标识
* @param position 签到天标识位
* @return
*/
public static boolean isSignInFixedDay(int holder, int position) {
return (holder & position) == position;
}
/**
* 按照天签到
*
* @param holder 当前签到标识
* @param position 签到天标识位
* @return 新签到标识
*/
public static int signInFixedDay(int holder, int position) {
if (isSignInFixedDay(holder, position)) {
return holder;
}
return holder | position;
}
/**
* 批量签到,适合补签场景
*
* @param holder 当前签到标识
* @param days 批量签到序号
* @return 新签到标识
*/
public static int batchSign(int holder, List<Integer> days) {
Iterator<Integer> it = days.iterator();
while (it.hasNext()) {
holder = holder | getPosition(it.next());
}
return holder;
}
public static int getPosition(int position) {
//0b01000000000000000000000000000000 == 0x40000000 左边第一位永远为0,即正整数,无日期含义;右边31位表示日期,从右到左1-31天
return MONTH_MODEL >>> (position - 1);
}
public static void main(String[] args) {
int month = 5;
System.out.printf("签到记录:【%s】 %n", Integer.toBinaryString(monthSignRecord));
// 签到记录:【1111111111111111111111111111000】
System.out.printf("签到总数:【%d】 %n", signCount(monthSignRecord));
// 签到总数:【28】
System.out.printf("%d月漏签总数 %d %n", month, unSignCountInFixedMonth(monthSignRecord, month));
// 5月漏签总数 3
System.out.printf("全月是否全部签到 %b %n", isSignFullInFixedMonth(monthSignRecord, month));
// 全月是否全部签到 false
System.out.printf("签到前【%s】%n", Integer.toBinaryString(monthSignRecord));
// 签到前【1111111111111111111111111111000】
int signTemp = signInFixedDay(monthSignRecord, getPosition(30));
signTemp = signInFixedDay(signTemp, getPosition(31));
System.out.printf("签到后【%s】%n", Integer.toBinaryString(signTemp));
// 签到后【1111111111111111111111111111011】
System.out.printf("全月是否全部签到 %b %n", isSignFullInFixedMonth(signTemp, month));
// 全月是否全部签到 false
System.out.printf("批量签到前【%s】%n", Integer.toBinaryString(monthSignRecord));
// 批量签到前【1111111111111111111111111111000】
int signBatch = batchSign(monthSignRecord, Arrays.asList(29, 30, 31));
System.out.printf("批量签到后【%s】%n", Integer.toBinaryString(signBatch));
// 批量签到后【1111111111111111111111111111111】
System.out.printf("全月是否全部签到 %b %n", isSignFullInFixedMonth(signBatch, month));
// 全月是否全部签到 true
}
}
2、数据库
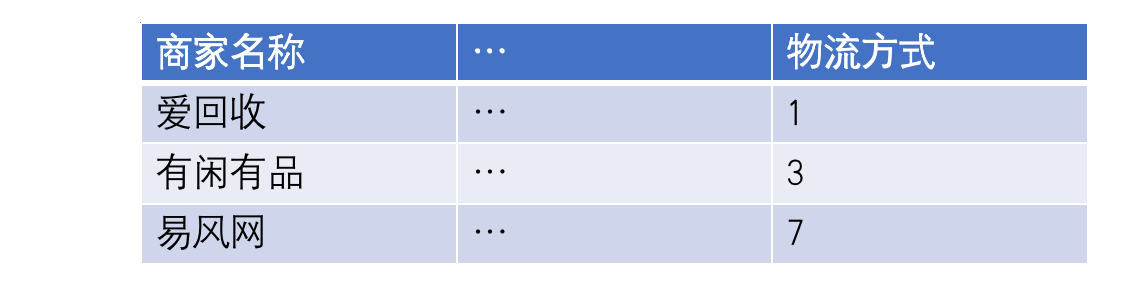
1)场景用例1:
查询所有支持快递物流的商家(物流方式包括 快递 上门 地铁)
a、传统的方式
1、数据库使用逗号分隔字符串,通过
find_in_set进行查询2、快递:1、快递+上门:3、快递 + 上门 + 地铁 : 7,通过
select * from ^ in (1, 3, 7 ……)
b、位图方式
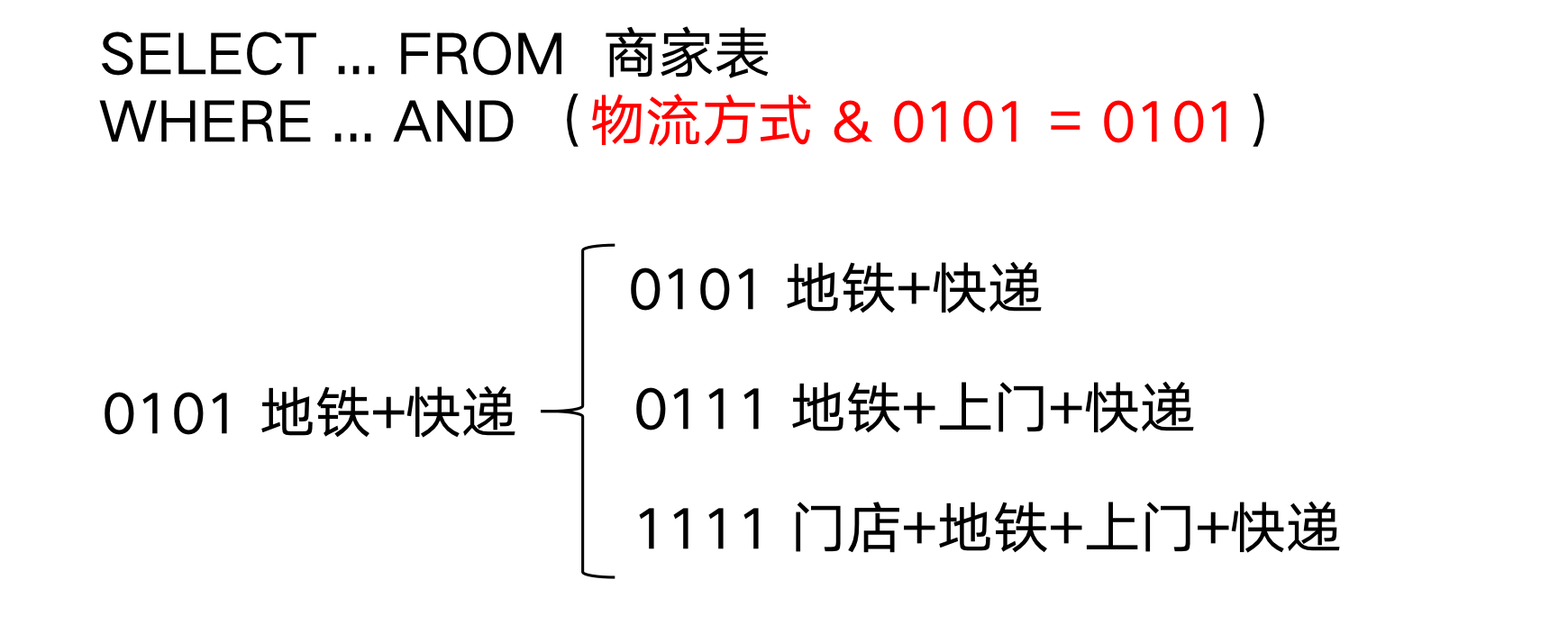
存储方式
左边第一位永远为
0,可以使用varchar()存储
CREATE TABLE `test`
(
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`status` varchar(32) NOT NULL COMMENT '产品状态 字典表 productstatus',
`update_user` bigint unsigned DEFAULT '0' COMMENT '更新人',
PRIMARY KEY (`id`) USING BTREE
) COMMENT ='测试表';
insert into test
(`status`,
`create_name`,
`update_user`)
values (1, 2, 3, '0101', 4, 5, 7, 9);
select LPAD(t.status & 0110, 4, '0') as '与运算' from test t;
# 0100
select LPAD(t.status | 0110, 4, '0') as '或运算' from test t;
# 0111
select LPAD(t.status ^ 0110, 4, '0') as '异或运算' from test t;
# 0011
3、redis
位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是
byte数组。我们 可以使用普通的get/set直接获取和设置整个位图的内容,也可以使用位图操作getbit/setbit等将byte数组看成「位数组」来处理。在我们平时开发过程中,会有一些
bool型数据需要存取,比如用户一年的签到记录, 签了是1,没签是0,要记录365天。如果使用普通的key/value,每个用户要记录365个,当用户上亿的时候,需要的存储空间是惊人的。为了解决这个问题,
Redis提供了位图数据结构,这样每天的签到记录只占据一个位,365天就是365个位,46个字节 (46*8bit = 368 > 365一个稍长一点的字符串) 就可以完全容纳下,这就大大 节约了存储空间。

1)基本使用
Redis的位数组是自动扩展,如果设置了某个偏移位置超出了现有的内容范围,就会自动将位数组进行零扩充。
案例:接下来我们使用位操作将字符串设置为 hello (不是直接使用 set 指令),首先我们需要得到 hello 的 ASCII 码
| ASCII | 二进制 |
|---|---|
| h | 01101000 |
| e | 01100101 |
| l | 01101100 |
| l | 01101100 |
| o | 01101111 |
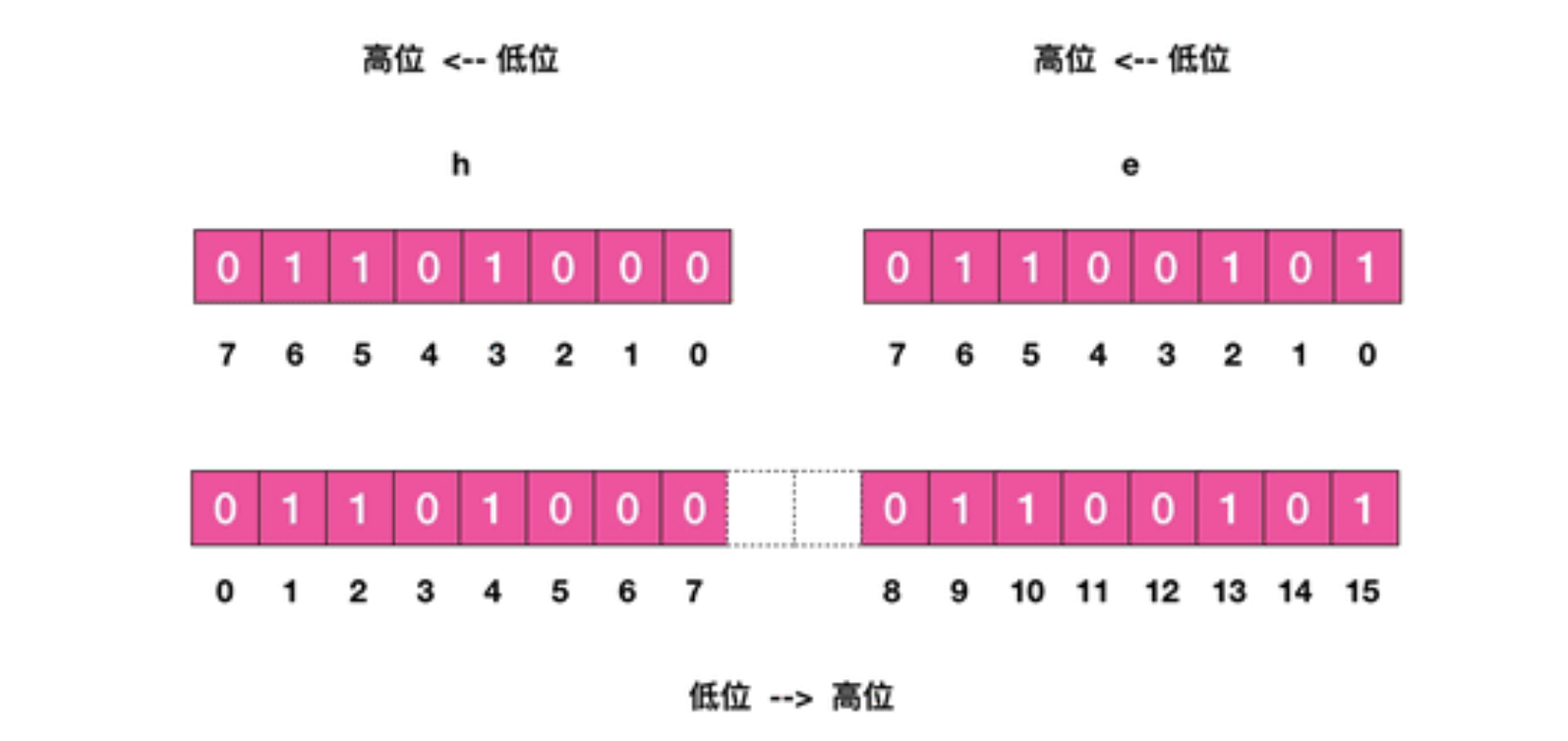
接下来我们使用 redis-cli 设置第一个字符,也就是位数组的前 8 位,我们只需要设置值为 1 的位,如上图所示,
⬤ h 字符只有 1/2/4 位需要设置
⬤ e 字符只有 9/10/13/15 位需要设置。
⬤ l字符只有17 、18、 20、 21
⬤ ………………
127.0.0.1:6379> setbit s 1 1
(integer) 0
127.0.0.1:6379> setbit s 2 1
(integer) 0
127.0.0.1:6379> setbit s 4 1
(integer) 0
127.0.0.1:6379> get s
"h"
127.0.0.1:6379> setbit s 9 1
(integer) 0
127.0.0.1:6379> setbit s 10 1
(integer) 0
127.0.0.1:6379> setbit s 13 1
(integer) 0
127.0.0.1:6379> setbit s 15 1
(integer) 0
127.0.0.1:6379> get s
"he"
a、零存零取
「零存」就是使用
setbit对位值进行逐个设置,
127.0.0.1:6379> setbit w 1 1
(integer) 0
127.0.0.1:6379> setbit w 2 1
(integer) 0
127.0.0.1:6379> setbit w 4 1
(integer) 0
127.0.0.1:6379> getbit w 1
(integer) 1
127.0.0.1:6379> getbit w 2
(integer) 1
127.0.0.1:6379> getbit w 4
(integer) 1
127.0.0.1:6379> getbit w 5
(integer) 0
b、整存零取
「整存」就是使用字符串一次性填充所有位数组,覆盖掉旧值。
127.0.0.1:6379> set w h # 整存 (integer) 0
127.0.0.1:6379> getbit w 1
(integer) 1
127.0.0.1:6379> getbit w 2
(integer) 1
127.0.0.1:6379> getbit w 4
(integer) 1
127.0.0.1:6379> getbit w 5
(integer) 0
c、不可打印字符,显示16进制
如果对应位的字节是不可打印字符,
redis-cli会显示该字符的 16 进制形式。
127.0.0.1:6379> setbit x 0 1
(integer) 0
127.0.0.1:6379> setbit x 1 1
(integer) 0
127.0.0.1:6379> get x
"\xc0"
2)统计和查找
Redis提供了位图统计指令bitcount和位图查找指令bitpos,⬤
bitcount用来统计指定位置范围内1的个数,⬤
bitpos用来查找指定范围内出现的第一个0或1。
start和end参数是字节索引(第几个字符),也就是说指定的位范围必须是8的倍数, 而不能任意指定 这很奇怪,我表示不是很能理解
Antirez为什么要这样设计。因为这个设 计,我们无法直接计算某个月内用户签到了多少天,而必须要将这个月所覆盖的字节内容全 部取出来 (getrange可以取出字符串的子串) 然后在内存里进行统计,这个非常繁琐。
1、通过 bitcount 统计用户一共签到了多少天,
2、通过 bitpos 指令查找用户从 哪一天开始第一次签到。
如果指定了范围参数[start, end],就可以统计在某个时间范围内用户 签到了多少天,用户自某天以后的哪天开始签到。
127.0.0.1:6379> set w hello
OK
127.0.0.1:6379> bitcount w # 总共有
(integer) 21
127.0.0.1:6379> bitcount w 0 0 # 第一个字符中 1 的位数,h -> 3个1
(integer) 3
127.0.0.1:6379> bitcount w 0 1 # 前两个字符中 1 的位数 he -> 7个1
(integer) 7
127.0.0.1:6379> bitpos w 0 # 第一个bit 0 位
(integer) 0
127.0.0.1:6379> bitpos w 1 # 第一个bit 1 位
(integer) 1
127.0.0.1:6379> bitpos w 1 1 1 # 从第二个字符算起(1-1),第一个 1 位
(integer) 9
127.0.0.1:6379> bitpos w 1 2 2 # 从第三个字符算起(2-2),第一个 1 位
(integer) 17
3)魔术指令 bitfield
前文我们设置 (
setbit) 和获取 (getbit) 指定位的值都是单个位的,如果要一次操作多个位,就必须使用管道来处理。不过
Redis的3.2版本以后新增了一个功能强大的指令,有了这条指令,不用管道也可以一次进行多个位的操作。⬤
bitfield有三个子指令,分别是get/set/incrby,它们都可以对指定位片段进行读写,但是最多只能处理64个连续的位,如果 超过64位,就得使用多个子指令,bitfield可以一次执行多个子指令。
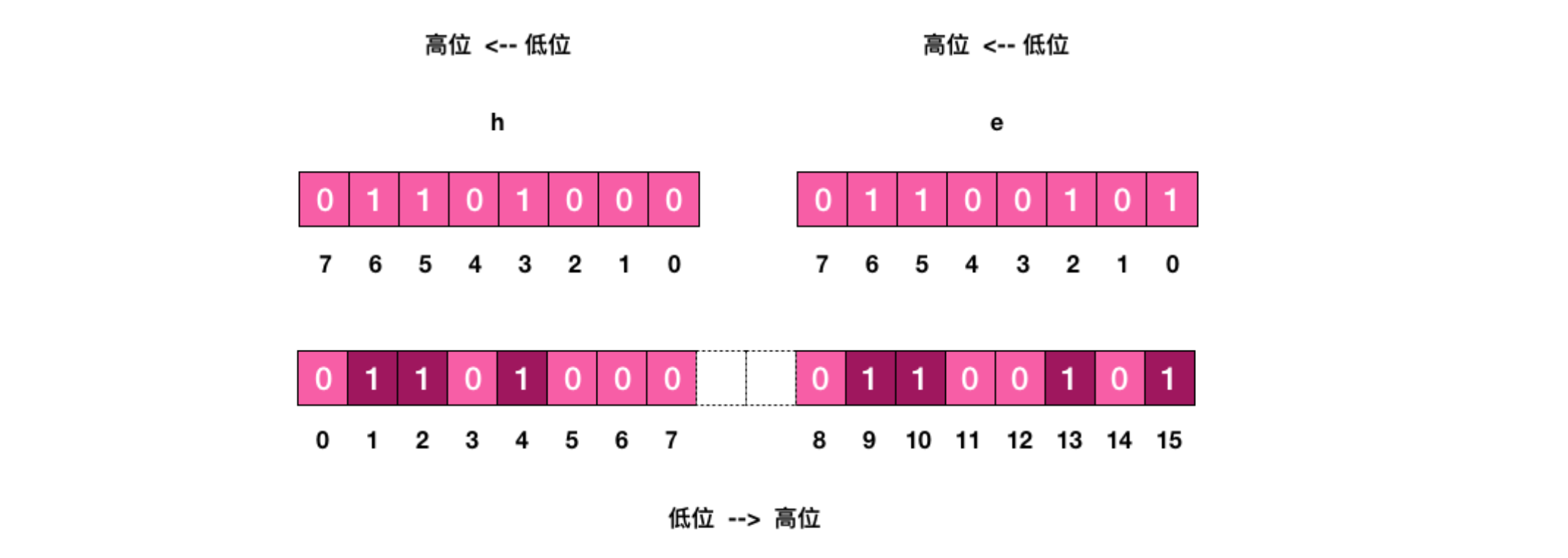
⬤ 有符号数是指获取的位数组中第一个位是符号位,剩下的才是值,如果第一位是 1,那就是负数。(有符号数最多可以获取 64 位)
⬤ 无符号数表示非负数,没有符号位,获取的位数组全部都是值。无符号数只能获取 63 位(因为首位表示正数/负数)
127.0.0.1:6379> set w hello
OK
127.0.0.1:6379> bitfield w get u4 0 # 从第一个位开始取 4 个位,结果是无符号数 (u)
(integer) 6
0110 -> 6
127.0.0.1:6379> bitfield w get u3 2 # 从第三个位开始取 3 个位,结果是无符号数 (u)
(integer) 5
101 -> 5
127.0.0.1:6379> bitfield w get i4 0 # 从第一个位开始取 4 个位,结果是有符号数 (i)
1) (integer) 6
0110 -> 0开头表示正数 -> 6
127.0.0.1:6379> bitfield w get i3 2 # 从第三个位开始取 3 个位,结果是有符号数 (i)
1) (integer) -3
101 -> 1开头表示负数 -> 减1 -> 100 取反 011 -> 3 -> 加负号 -3
a、一次执行多个指令
127.0.0.1:6379> bitfield w get u4 0 get u3 2 get i4 0 get i3 2
1) (integer) 6
2) (integer) 5
3) (integer) 6
4) (integer) -3
b、set:修改字符
然后我们使用 set 子指令将第二个字符 e 改成 a,a 的 ASCII 码是 97。
127.0.0.1:6379> bitfield w set u8 8 97 #从第9个位开始,将接下来的 8 个位用无符号数 97 替换
1) (integer) 101
127.0.0.1:6379> get w
"hallo"
c、incrby:自增
再看第三个子指令
incrby,它用来对指定范围的位进行自增操作。既然提到自增,就有可能出现溢出,bitfield指令提供了溢出策略子指令overflow,用户可以选择溢出行为。⬤ 如果增加了正数,会出现上溢
⬤ 如果增加的是负数,就会出现下溢出。
1、折返 (wrap)
Redis默认的处理是折返。如果出现了溢出,就将溢出的符号位丢掉。◯ 如果是
8位无符号数255, 加 1 后就会溢出,会全部变零。◯ 如果是
8位有符号数127,加1后就会溢出变成-128。
127.0.0.1:6379> set w hello
OK
127.0.0.1:6379> bitfield w incrby u4 2 1 # 从第三个位开始,对接下来的 4 位无符号数 +1
1) (integer) 11
127.0.0.1:6379> bitfield w incrby u4 2 1
1) (integer) 12
127.0.0.1:6379> bitfield w incrby u4 2 1
1) (integer) 13
127.0.0.1:6379> bitfield w incrby u4 2 1
1) (integer) 14
127.0.0.1:6379> bitfield w incrby u4 2 1
1) (integer) 15
127.0.0.1:6379> bitfield w incrby u4 2 1 # 溢出折返了
1) (integer) 0
2、饱和截断 SAT
饱和截断 (
sat),超过了范围就停留在最大/最小值。`
127.0.0.1:6379> set w hello
OK
127.0.0.1:6379> bitfield w overflow sat incrby u4 2 1 # 从第三个位开始,对接下来的 4 位无符号数 +1
1) (integer) 11
127.0.0.1:6379> bitfield w overflow sat incrby u4 2 1
1) (integer) 12
127.0.0.1:6379> bitfield w overflow sat incrby u4 2 1
1) (integer) 13
127.0.0.1:6379> bitfield w overflow sat incrby u4 2 1
1) (intege) 14
127.0.0.1:6379> bitfield w overflow sat incrby u4 2 1
1) (integer) 15
127.0.0.1:6379> bitfield w overflow sat incrby u4 2 1 # 保持最大值
1) (integer) 15
3、失败不执行 FAIL
失败 (
fail) 报错不执行
127.0.0.1:6379> set w hello
OK
127.0.0.1:6379> bitfield w overflow fail incrby u4 2 1 1) (integer) 11
127.0.0.1:6379> bitfield w overflow fail incrby u4 2 1 1) (integer) 12
127.0.0.1:6379> bitfield w overflow fail incrby u4 2 1 1) (integer) 13
127.0.0.1:6379> bitfield w overflow fail incrby u4 2 1 1) (integer) 14
127.0.0.1:6379> bitfield w overflow fail incrby u4 2 1 1) (integer) 15
127.0.0.1:6379> bitfield w overflow fail incrby u4 2 1 # 不执行
1) (nil)
二、BitMap
| 数据结构 | 用哈希? | 有冲突? | 解决冲突? | 概率估算? | 准确率 |
|---|---|---|---|---|---|
| RoaringBitmap | ❌ | ❌ | — | ❌ | 100% |
| HashMap | ✅ | ✅ | ✅(链表等) | ❌ | 100% |
| Bloom Filter | ✅ | ✅ | ❌ | ✅ | <100%(有误判) |
| HyperLogLog | ✅ | — | — | ✅ | 近似(~98%) |
1、BitMap 简介
1)优点
1、节约内存:针对海量数据的存储,可以极大的节约存储成本!当需要存储一些很大,且无序,不重复的整数集合,那使用
Bitmap的存储成本是非常低的。2、天然去重: 因为
bitmap每个值都只对应唯一的一个位置,不能存储两个值,所以Bitmap结构天然适合做去重操作。3、快速定位: 同样因为其下标的存在,可以快速定位数据!比如想判断数字 ` 99999
是否存在于该bitmap中,若是使用传统的集合型存储,那就要逐个遍历每个元素进行判断,时间复杂度为O(N)。而由于采用Bitmap存储,只要查看对应的下标数的值是0还是1即可,时间复杂度为O(1)。所以使用bitmap可以非常方便快速的查询某个数据是否在bitmap`中。4、二进制判断: 还有因为其类集合的特性,对于一些集合的交并集等操作也可以支持!比如想查询[1,2,3]与[3,4,5] 两个集合的交集,用传统方式取交集就要两层循环遍历。而
Bitmap实现的底层原理,就是把01110000和00011100进行与操作就行了。而计算机做与、或、非、异或等等操作是非常快的。
2)缺点
1、类型单一:只能存储正整数而不能是其他的类型;
2、稀疏存储不适合:不适合存储稀疏的集合,比如,一个集合存放了两个数
[1,99999999],那用bitmap存储的话就很不划算,这也与它本来节约存储的优点也背离了;3:重复数据无法存储:不适用于存储重复的数据。
3)优化
既然
bitmap的优点如此突出,那应该如何去优化它存在的一些局限呢?1、 针对存储非正整数的类型,如字符串类型的,可以考虑将字符串类型的数据利用类似
hash的方法,映射成整数的形式来使用bitmap,但是这个方法会有hash冲突的问题,解决这个可以优化hash方法,采用多重hash来解决,但是根据经验,这个效果都不太好,通常的做法就是针对字符串建立映射表的方式。2、针对
bitmap的优化最核心的还是对于其存储成本的优化,毕竟大数据领域里面,大多数时候数据都是稀疏数据,而我们又经常需要使用到bitmap的特长,比如去重等属性,所以存在一些进一步的优化,比较知名的有WAH、EWAH、RoaringBitmap等,其中性能最好并且应用最为广泛的当属RoaringBitmap
2、实现方案 - BitSet
缺点1:只能处理
32位2^32 =4294967296。缺点2:不适合存储稀疏的集合,比如,一个集合存放了两个数
[1,99999999],那用 它 存储的话就很不划算
package com.hlj.util.Z005BitSet;
import org.junit.Test;
import java.util.Arrays;
import java.util.BitSet;
/**
* BitSet的应用场景 海量数据去重、排序、压缩存储
* BitSet的基本操作 and(与)、or(或)、xor(异或)
* Bitset,也就是位图,由于可以用非常紧凑的格式来表示给定范围的连续数据而经常出现在各种算法设计中。
* 基本原理是,用1位来表示一个数据是否出现过,0为没有出现过,1表示出现过。使用用的时候既可根据某一个是否为0表示此数是否出现过。
*/
public class D01BitSet {
/**
* 给定一个的整数数组,请找到其中缺少的数字。
*/
private void printMissingNumber(int[] numbers, int count) {
System.out.println("一共有" + count + "个数据:目前数组为" + Arrays.toString(numbers));
// 一共有10个数据:目前数组为[1, 2, 3, 4, 6, 9, 8]
// 一共有多少数字,
BitSet bitSet = new BitSet(count);
// 将指定索引处的位设置为 true。
for (int number : numbers) {
bitSet.set(number - 1);
}
//一共丢失了多少位
int missingCount = count - numbers.length;
int lastMissingIndex = 0; // 索引从0开始
for (int i = 0; i < missingCount; i++) {
//返回第一个设置为 false 的位的索引,这发生在指定的起始索引或之后的索引上。
lastMissingIndex = bitSet.nextClearBit(lastMissingIndex);
System.out.println(++lastMissingIndex);
}
}
@Test
public void start() {
// 丢失3个数据
printMissingNumber(new int[]{1, 2, 3, 4, 6, 9, 8}, 10);
// 丢失1个数据
printMissingNumber(new int[]{1, 2, 3, 5}, 5);
}
}
3、RoaringBitmap
为了解决
BitMap存储较为稀疏数据时,浪费存储空间较多的问题,我们引入了稀疏位图索引Roaring BitMap。RoarinBitMap有较高的计算性能及压缩效率。RoaringBitmap是一种高效的Bitmap压缩算法,目前已被广泛应用在各种语言和各种大数据平台。适合计算超高基维的,常用于去重、标签筛选、时间序列等计算中。
1)简介
a、数据分桶
⬤
RoaringBitmap将32位无符号整数按照高16位进行分桶,即最多可能有2^16=65536个桶,每个桶称为一个container。⬤ 存储数据时,根据数据的高
16位找到对应的桶(container),如果找不到则新建一个桶,然后将低16位放入该桶中。假设我们有一个
32位无符号整数N = 6200(其二进制表示为00000000 00000000 00011000 10110000,计算高16位
高
16位可以通过将整数右移16位来得到。右移操作会丢弃整数的低16位,并将高16位移到低16位的位置,high_16_bits = N >> 16, 对于N = 6200,因为6200小于2^16(即65536),所以它的高16位都是0。因此,high_16_bits的结果是0。计算低16位:
低
16位可以通过将整数与0xFFFF(即二进制的11111111 11111111)进行位与操作来得到。但是,对于6200来说,由于它的高16位都是 0,所以直接取它的值就是它的低16位(但这不是一个通用的方法,仅适用于这种情况)。通用的方法是:low_16_bits = N & 0xFFFF;对于N = 6200,low_16_bits就是6200本身。
b、高效存储与查询
⬤ 通过将数据分桶并使用不同类型的容器存储,
RoaringBitmap能够高效地存储和查询大量数据。⬤ 在查询时,首先根据数值的高
16位找到对应的桶,然后在桶中使用适当的容器进行查找。高
16位作为索引查找具体的数据块,当前索引值为0,低16位作为value进行存储。
RoaringBitMap在进行数据存储时,会先根据高16位找到对应的索引key(二分查找),低16位作为key对应的value,先通过key检查对应的container容器,如果发现container不存在的话,就先创建一个key和对应的container,否则直接将低16位存储到对应的container中。
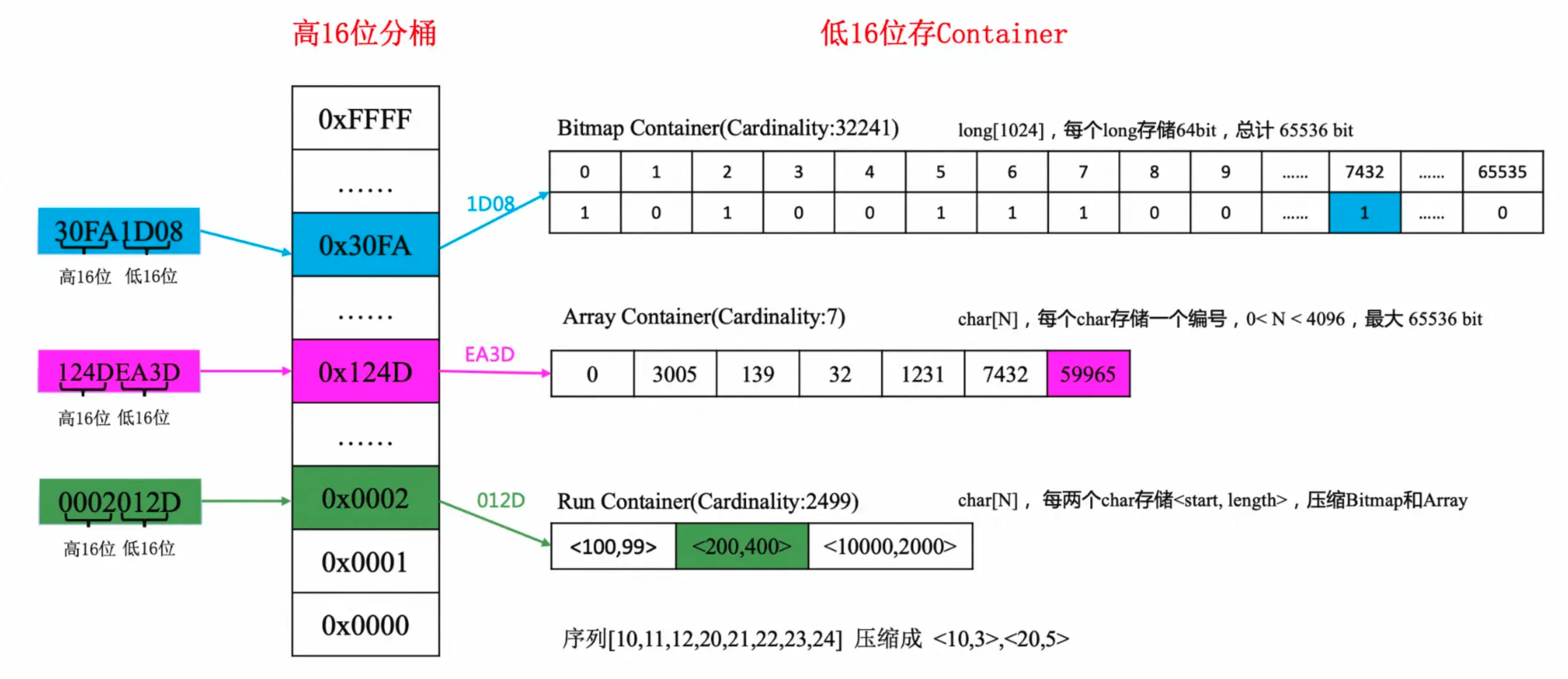
**举例说明 **
1、数据准备
假设数据包括:[11, 12, 13, 14, 15, 27, 28, 29, 6200, 6202, 6204, …]
2、分桶与存储
⬤ 以整数 6200 为例,其 16 进制表示为 00001838,高 16 位为0000,低16位为 1838。
⬤ 首先,根据高16 位 0000 找到对应的桶(假设这是第一个桶)。
⬤ 然后,检查该桶中是否已经存在,如果不存在则创建一个新的 ArrayContainer。
⬤ 将低 16 位1838(即十进制中的 6200 )添加到 ArrayContainer 中。
⬤ 对于连续的整数序列(如 11 到 15 ),这些可能会存储在 RunContainer 中,以减少存储空间。
3、查询操作
⬤ 当需要查询某个数值(如 6202 )是否存在时,同样先根据高 16 位找到对应的桶。
⬤ 然后在桶中使用相应的容器进行查找。
⬤ 如果数值存在,则返回结果;如果不存在,则表示该数值不在集合中。
2)简单使用
@Test
public void test() {
// 创建两个 RoaringBitmap 实例
RoaringBitmap bitmap1 = new RoaringBitmap();
RoaringBitmap bitmap2 = new RoaringBitmap();
// 向 bitmap1 添加元素
bitmap1.add(1);
bitmap1.add(100);
bitmap1.add(1000);
// 向 bitmap2 添加元素
bitmap2.add(100);
bitmap2.add(200);
bitmap2.add(1000);
// 执行交集操作
RoaringBitmap intersection = RoaringBitmap.and(bitmap1, bitmap2);
System.out.println("Intersection: " + intersection); // 应该包含 100 和 1000
// Intersection: {100,1000}
// 执行差集操作 (bitmap1 - bitmap2)
RoaringBitmap difference = RoaringBitmap.andNot(bitmap1, bitmap2);
System.out.println("Difference (bitmap1 - bitmap2): " + difference); // 应该只包含 1
// Difference (bitmap1 - bitmap2): {1}
// 检查元素是否存在
boolean contains100 = bitmap1.contains(100);
System.out.println("Does bitmap1 contain 100? " + contains100); // 输出 true
// Does bitmap1 contain 100? true
// 输出 bitmap1 的内容
System.out.println("Bitmap1: " + bitmap1);
// Bitmap1: {1,100,1000}
}
3)存储对比
a、连续数据
分别向位图中插入
1w、10w、100w、1000w条连续数据,并且对比BitMap和RoaringBitMap占用空间的大小。比较结果如下
| 10w数据占用空间 | 100w数据占用空间 | 1000w数据占用空间 | |
|---|---|---|---|
BitMap |
97.7KB |
976.6KB |
9.5MB |
RoaringBitMap |
16KB |
128KB |
1.2MB |
@Test
public void testSizeOfBitMap() {
//对比占用空间大小 - 10w元素
RoaringBitmap roaringBitmap3 = new RoaringBitmap();
byte[] bits2 = new byte[100000];
for (int i = 0; i < 100000; i++) {
roaringBitmap3.add(i);
bits2[i] = (byte) i;
}
System.out.println("10w数据 roaringbitmap byte size:"+ roaringBitmap3.getSizeInBytes());
System.out.println("10w数据 位图数组 byte size:"+bits2.length);
RoaringBitmap roaringBitmap4 = new RoaringBitmap();
byte[] bits3 = new byte[1000000];
for (int i = 0; i < 1000000; i++) {
roaringBitmap4.add(i);
bits3[i] = (byte) i;
}
System.out.println("100w数据 roaringbitmap byte size:"+ roaringBitmap4.getSizeInBytes());
System.out.println("100w数据 位图数组 byte size:"+bits3.length);
RoaringBitmap roaringBitmap5 = new RoaringBitmap();
byte[] bits4 = new byte[10000000];
for (int i = 0; i < 10000000; i++) {
roaringBitmap5.add(i);
bits4[i] = (byte) i;
}
System.out.println("1000w数据 roaringbitmap byte size:"+ roaringBitmap5.getSizeInBytes());
System.out.println("1000w数据 位图数组 byte size:"+bits4.length);
}
b、稀疏数据
位图所占用空间大小只和位图中索引的最大值有关系,现在我们向位图中插入
1和999w两个偏移量位的元素,再次对比BitMap和RoaringBitMap所占用空间大小。
| 占用空间 | |
|---|---|
BitMap |
9.5MB |
RoaringBitMap |
24 Byte |
@Test
public void testSize() {
RoaringBitmap roaringBitmap5 = new RoaringBitmap();
byte[] bits4 = new byte[10000000];
for (int i = 0; i < 10000000; i++) {
if (i == 1 || i == 9999999) {
roaringBitmap5.add(i);
bits4[i] = (byte) i;
}
}
System.out.println("两个稀疏数据 roaringbitmap byte size:"+ roaringBitmap5.getSizeInBytes());
System.out.println("两个稀疏数据 位图数组 byte size:"+bits4.length);
}
4)容器类型
| 数据特征 | 推荐容器 | 是否自动转换 |
|---|---|---|
| 元素 < 4096,稀疏 | ArrayContainer |
自动 |
| 元素 > 4096,稠密 | BitmapContainer |
自动 |
| 大量连续区间 | RunContainer |
需手动调用 runOptimize() |
- 对于时间序列、自增
ID、日志偏移量等连续数据,在构建完成后立即调用runOptimize()。 - 对于随机
ID集合,无需干预,Roaring会自动在Array/Bitmap间切换。 - 避免频繁增删导致容器反复转换(可批量操作后统一优化)。
a、数组容器( Array Container)
用于存储稀疏数据。当
container中的Integer数量小于4096时,使用Short类型的有序数组来存储值。由于short为2字节,因此n个数据占用2n字节。当数据量达到4096时,会转换为BitmapContainer
- 举例:假设我们需要存储一个整数集合,其中包含的元素相对较少且分布不均。
- 例如,集合中只包含少数几个整数,如{1, 1000, 20000}。在这个例子中,我们可以使用
ArrayContainer来存储这些元素。ArrayContainer内部使用一个有序的Short数组来存储数据,这样可以方便地进行二分查找,提高查询效率。
- 例如,集合中只包含少数几个整数,如{1, 1000, 20000}。在这个例子中,我们可以使用
-
结构
-
底层是一个升序排列的
short[]数组 -
每个元素是低 16 位的值(0~65535 → 可用
short表示) -
初始容量为 4,动态扩容(类似
ArrayList)
-
-
内存占用
-
若有
n个元素,则占用 2n 字节-
ArrayContainer存储的是 低16位的整数值(范围 0 ~ 65535) -
因此,每个元素就用一个
short存储其实际数值。 -
// 存储 {1, 1000, 20000} short[] data = {1, 1000, 20000}; // 占用 3 × 2 = 6 字节
-
- 例如:100 个元素 → 200 字节;4096 个元素 →
8192字节(=8KB) -
4096是硬性阈值:- 因为
4096 × 2 字节 = 8192 字节 = 8KB,正好等于BitmapContainer的固定大小。
- 因为
-
-
操作性能
-
查找:二分查找,
O(log n) -
插入/删除:需移动元素,
O(n),但 n 小所以快 -
合并/交集:双指针遍历,适合稀疏数据
-
b、位图容器(Bitmap Container)
位图容器(
Bitmap Container):用于存储稠密数据。无论container中存储了多少个数据,其占用的空间始终是8KB(因为需要65536个bit来表示0到65535的所有可能值)
- 举例:如果我们需要存储一个包含大量整数的集合,且这些整数在较低的
16位范围内分布较为密集,- 例如:集合中包含大量连续的整数或者整数分布较为均匀。在这种情况下,使用
BitmapContainer会更高效。BitmapContainer内部使用一个固定长度的Long数组来表示位图,每个bit位表示一个可能的整数值是否存在。由于BitmapContainer的固定长度为1024个Long(即65536个bit),因此无论存储多少数据,其占用的空间都是固定的(8KB)。
- 例如:集合中包含大量连续的整数或者整数分布较为均匀。在这种情况下,使用
-
结构
-
固定大小的位图:
65536bit =8192byte =8KB -
每个
bit表示对应数值是否存在
-
-
内存占用:恒为
8KB,与实际元素数量无关 -
操作性能
-
查找/插入/删除:
O(1)(直接操作 bit) -
位运算(
AND/OR/XOR):极快(按 word 批量操作) -
迭代所有元素:需遍历全部
65536位,较慢(但可用优化跳过零块)
-
c、运行长度编码容器(Run Container)
运行长度编码容器(
Run Container):采用行程长度编码(Run Length Encoding,RLE)来压缩连续的数据。对于连续出现的数字,只记录初始数字和后续数量,从而节省存储空间。。
- 举例:当需要存储一系列连续的整数时,
RunContainer会非常有用。- 例如,集合中包含连续的整数序列{11, 12, 13, 14, 15, 27, 28, 29}。
RunContainer使用行程长度编码(Run Length Encoding,RLE)来压缩这些数据,只记录序列的起始值和长度。在这个例子中,序列会被压缩为两个二元组(11,4)和(27,2),表示从11开始有4个连续递增的值,从27开始有2个连续递增的值。这种压缩方式可以大大减少存储空间,并提高查询效率。
- 例如,集合中包含连续的整数序列{11, 12, 13, 14, 15, 27, 28, 29}。
-
结构
-
使用
RLE(Run-LengthEncoding) 存储连续区间 -
数据表示为一系列
(start, length)对 -
底层用两个
char[]或交替的short[]存储(start和len各占 2 字节)
-
-
内存占用
-
若有
k个连续区间,则占用4k字节 -
极端例子:
- 全连续(0~65535)→ 1 个区间 → 4 字节!
- 完全不连续(每个数孤立)→ 65536 个区间 → 262,144 字节(比 Bitmap 还大!)
-
-
操作性能
-
查找:需遍历区间,
O(k) -
插入/删除:可能分裂或合并区间,逻辑复杂
-
序列化/压缩:非常高效(尤其对时间戳、自增 ID)
-
-
适用场景
-
数据高度连续或分段连续
-
如:时间窗口内的事件 ID、数据库自增主键、日志序列号
-
4)FAQ
a、超过 32 位的二进制怎么处理
- 扩展
RoaringBitmap:对于64位整数,由于long型整数通常是64位的,而传统的RoaringBitmap是为32位整数设计的,因此不能直接使用32位的RoaringBitmap来处理long型的整数。 - 寻找支持
64位整数的类似RoaringBitmap的数据结构,如Roaring64NavigableMap和Roaring64Bitmap等;当处理long型的整数时,通过一些扩展或修改来支持64位整数。
b、32 位、64 位 Roaring 的硬上限:512 MB
32位RoaringBitmap:最多支持2^32 - 1 ≈ 42.9 亿个不同的整数(即位索引范围[0, 2³²))。-
因其底层使用
2¹⁶ = 65,536个容器,每个BitmapContainer最大 8192 字节: -
无论你存 1 个还是 42 亿个 int,最大就是
512MB,这是它的优势。
-
64位Roaring64NavigableMap:理论上支持2^64个整数(实际受限于JVM堆内存和物理资源)。
c、用布隆过滤器还是压缩位图?
-
布隆过滤器:其内存占用主要取决于位数
m和哈希函数的数量k。通过调整这些参数,可以控制布隆过滤器的内存占用和误报率。 -
RoaringBitmap:其内存占用取决于整数的分布情况和所使用的容器的类型。对于稀疏的整数集合,RoaringBitmap可能比布隆过滤器更节省内存;但对于稠密的整数集合,情况可能有所不同。
| 特性 | Roaring64Bitmap | Roaring64NavigableMap |
|---|---|---|
| 底层结构 | 哈希表 (HashMap) + 32位容器 | 红黑树 (TreeMap) + 32位容器 |
| 元素顺序 | 无序 | 严格升序(按64位值) |
| 导航操作 | 不支持 | 支持(ceiling/floor/first/last) |
| 范围查询 | 需遍历全部数据 | 高效范围扫描(subMap/headMap) |
| 插入/查找 | O(1) 平均时间复杂度 | O(log C) 时间复杂度 (C=容器数量) |
| 内存占用 | 略低(无树节点开销) | 略高(树结构指针开销) |
| 顺序遍历 | 需额外排序 | 原生高效(缓存友好) |
d、优缺点
-
优点:
-
响应快:直接机器内存取值,快速返回结果,满足接口TP999:50ms内需求,但严重依赖机器性能。
-
水平分组:数据量多的情况下,可考虑分组内水平扩容机器,增加接口整体承载量
-
-
缺点:
-
启动慢:由于加载到机器内存,导致每次重启机器总要全量加载所有群体
-
水平扩容困难:分组内可以水平扩容,但是固定分组后,单机器的内存有限,达到上限扩容分组困难;
-
资源耗费:物理机资源耗费比较大
-
5)自定义压缩 Bitmap
a、 ArrayContainer
public class ArrayContainer {
public byte[] values;
public ArrayContainer(int initialCapacity) {
this.values = new byte[initialCapacity];
}
}
b、CompressedBitmap
package com.hlj.util.Z005BiMap.模拟bitMap;
/**
* CompressedBitmap
*
* @author zhangyujin
* @date 2024/9/14
*/
public class CompressedBitmap {
/**
* 表示“是”或“已设置”,即该位为1
*/
public static final char Y = 1;
/**
* 表示“否”或“未设置”,即该位为0
*/
public static final char N = 0;
/**
* 每个“容器”负责管理 16 个 bit 位。这是分片的基础单位。
*/
public static final int ARRAY_CONTAINER_SIZE = 16;
/**
* 容器数组,每个元素是一个ArrayContainer对象
*/
ArrayContainer[] containers;
/**
* 初始化容量:根据传入的 initialCapacity(最大可表示的位数),计算需要多少个容器。
*
*
* @param initialCapacity initialCapacity
* @return {@link }
*/
public CompressedBitmap(long initialCapacity) {
// 每个容器管 16 个位,所以总共需要 initialCapacity / 16 个容器,不考虑向上去整
int containersSize = (int) (initialCapacity / ARRAY_CONTAINER_SIZE);
// 创建一个 ArrayContainer 类型的数组,初始时所有元素为 null(延迟初始化,节省内存)。
this.containers = new ArrayContainer[containersSize];
}
/**
* bitMap添加数据
*
* @param offset offset
*/
public void add(long offset) {
// 1、根据偏移量定位容器所在分片
int shardIndex = getShardIndex(offset);
ArrayContainer container = containers[shardIndex];
if (container == null) {
container = new ArrayContainer(ARRAY_CONTAINER_SIZE);
}
// 2、根据偏移量定位容器内部位置
int shardOffset = getShardOffset(offset);
container.values[shardOffset] = Y;
containers[shardIndex] = container;
}
/**
* 获取偏移量数据
*
* @param offset offset
* @return 获取值(1 || 0)
*/
public int get(long offset) {
int shardIndex = getShardIndex(offset);
ArrayContainer container = containers[shardIndex];
if (container == null) {
return N;
}
int shardOffset = getShardOffset(offset);
if (Y == container.values[shardOffset]) {
return Y;
}
return N;
}
/**
* 计算 offset 属于第几个容器/分片。
*
* @param offset offset
* @return {@link int}
*/
public int getShardIndex(long offset) {
// offset 是从 1 开始计数的!比如:offset=1~16 → 索引 0;offset=17~32 → 索引 1,等等。
return (int) ((offset - 1) / ARRAY_CONTAINER_SIZE);
}
/**
* 根据偏移量定位容器内部位置
*
* @param offset offset
* @return {@link int}
*/
public int getShardOffset(long offset) {
return (int) ((offset - 1) % ARRAY_CONTAINER_SIZE);
}
}
c、测试使用
@Test
public void test(){
CompressedBitmap bitmap = new CompressedBitmap(64);
bitmap.add(63);
System.out.println(bitmap.get(63));
// 1
System.out.println(bitmap.get(64));
// 0
System.out.println(bitmap.get(2));
// 0
}
4、Roaring64NavigableMap
Roaring64NavigableMap中,单个桶(即一个high-key对应的RoaringBitmap)的最大内存占用 ≈ 512 MB
- 核心原理:
Roaring64NavigableMap通过 分层结构 支持 64 位整数 - 关键拆分:
value = (high_key << 32) | low_value - 存储方式:
TreeMap<Long, RoaringBitmap> - -
key= 高 32 位 (作为桶标识) - -
value= 低 32 位 (存储在标准RoaringBitmap容器中)
1)原理:单桶内存真相
-
单桶最大内存 = 512 MB
-
仅当低
32位全满时(存储 42.9 亿个值,范围[0, 2³²))-
RoaringBitmap fullBucket = new RoaringBitmap(); fullBucket.add(0L, 4294967296L); // 低32位全集 System.out.println(fullBucket.serializedSizeInBytes()); // ≈ 512 MB
-
| 数据特征 | 容器类型 | 内存占用 | 说明 |
|---|---|---|---|
| 空桶 | 无容器 | 0 B (不创建对象) | lazy initialization |
| 1 个元素 | ArrayContainer |
80–120 B | 对象头(16B)+数组(12B)+对齐填充 |
| 4,095 个稀疏元素 | ArrayContainer |
≈8.2 KB | 4095×2B + 对象开销 |
| 4,096+ 连续元素 | BitmapContainer |
8,192 B (固定) | 65536 位 = 8KB |
| 10,000 个密集元素 | 1+ 个 BitmapContainer |
8–16 KB | 按 16 位 key 自动分片 |
| 42.9 亿元素 (全集) | 65,536 × BitmapContainer | 512 MB | 65536×8KB = 512MB |
2)内存分析
a、为什么Roaring64 比 32 位多 1.5–2 倍内存?
-
无免费午餐:
64位支持是以“元数据膨胀”为代价换来的。 - 额外结构:
- 外层
TreeMap<Integer, RoaringBitmap>存储(highKey → lowBitmap) - 每个
Map.Entry≈ 32–48 字节 RoaringBitmap实例本身 ≈60–100字节(即使只含 1 个容器)
- 外层
- 内存构成分析(1 亿中度稀疏 ID,
high-key=5,000)
| 组件 | 内存占比 | 说明 |
|---|---|---|
低 32 位数据 |
65% | 与 RoaringBitmap 相同的压缩效率 |
TreeMap 结构 |
20% | 节点指针(24B/节点)+红黑树颜色标记 |
RoaringBitmap 对象 |
15% | 每个桶 64–100B 基础开销 + 容器数组 |
| 总计膨胀 | +78% | vs 纯 32 位实现 |
b、Roaring64 没有固定上限,内存波动比较大
- 理论上可无限扩展(只要堆够大),但:
- 每增加一个
high-key,就增加一个RoaringBitmap对象 - 当
high-key>10,000,内存增长趋近线性,失去压缩意义
- 每增加一个
3)使用建议
a、避免直接使用 Roaring64:
- 永远不要用
Roaring64存储高位随机的 64 位整数 (如 UUID、加密哈希)。- 仅当满足 high-key ≤ 5000 + 需要范围查询 时,才用
Roaring64NavigableMap - 永远优先考虑:
ID重设计 > 映射压缩 > 分片 >
- 仅当满足 high-key ≤ 5000 + 需要范围查询 时,才用
- 在数据规模 >1 亿或
high-key>1,000 时- 务必用真实数据采样压测
- 理论估算在极端分布下误差可达
200%
- 先做
ID重设计或映射压缩,可节省 60–90% 内存并避免 GC 灾难。- 随机
ID用 映射表压缩: - 业务
ID重设计(用 32 位 ID + 分片)
- 随机
b、救命方案:避免内存爆炸
// 方案1:业务分片 (high-key 隔离)
int shard = (int)(userId % 256); // 256 个分片
Roaring64NavigableMap[] shards = new Roaring64NavigableMap[256];
// 方案2:Long-to-Int 映射 (随机 ID 场景)
Map<Long, Integer> idMapper = new Caffeine.newBuilder()
.maximumSize(100_000_000)
.build();
RoaringBitmap compactSet = new RoaringBitmap(); // 仅用 32 位版
4)FAQ:
a、高危 high-key > 10,000 需极度谨慎?
-
内存黑洞:
-
/ 高位随机的 1000 万个 long (如 UUID 转 long) Roaring64NavigableMap map = new Roaring64NavigableMap(); for (int i = 0; i < 10_000_000; i++) { map.add(ThreadLocalRandom.current().nextLong()); // high-key ≈ 1000 万 } // 实际内存: 3.2 GB (理论原始数据仅 80 MB!)
-
-
GC灾难:100万对象 →Young GC从12ms→95ms500万对象 → 可能触发ConcurrentModeFailure(G1 GC)
-
序列化瘫痪:
10万 high-key 的 map 序列化后 ≈ 120 MB- 网络传输 + 反序列化耗时 > 2 秒(1Gbps 网络)
b、High-key 安全阈值(生产环境实测)
High-key 数量 |
风险等级 | 可行场景 | 替代方案 |
|---|---|---|---|
| < 1,000 | 安全 | 实时查询、在线服务 | 无需分片 |
| 1,000 – 10,000 | 监控使用 | 离线计算、批处理 | 增加堆内存 20% |
| 10,000 – 50,000 | 高风险 | 仅限数据仓库 | 必须分片 + Off-heap |
| > 50,000 | 禁止 | 无 | 换用 Sux4J/EWAH 或自建 ID 映射 |
c、大对象防御:强制分片 + 定期清理
- 32 位数据:优先不分片,直到单对象>300MB
- 64 位数据:
high-key< 1000:用 32-64分片high-key> 5000:必须做 Long-to-Int映射
public class ShardedRoaringSet {
private final int shardCount = 256;
private final Roaring64NavigableMap[] shards = new Roaring64NavigableMap[shardCount];
public void add(long value) {
int shard = (int)(value % shardCount); // 业务相关分片
if (shards[shard] == null) {
shards[shard] = new Roaring64NavigableMap();
}
shards[shard].add(value);
// 防御性检查:单分片 high-key > 4000 时告警
if (shardHighKeyCount(shard) > 4000) {
triggerCompaction(shard); // 后台压缩或迁移
}
}
}
核心原则:分片数 = max(业务需求, 性能约束)
| 场景特征 | 总规模 | 推荐分片数 | 单分片规模 | 关键考量点 |
|---|---|---|---|---|
| 32位整数 + 全局查询为主 | ≤ 4000 万 | 1 | 全量 | 单 RoaringBitmap 性能最优 |
| 32位整数 + 混合查询 | 4000 万-2 亿 | 4-16 | 2500万-5000万 | 避免单对象>200MB |
64位整数 (high-key<1000) |
1-10 亿 | 8-32 | 3000万-1.2亿 | 控制单分片 high-key < 500 |
| 64位高度随机ID | >1 亿 | 必须映射压缩 | - | 优先 Long-to-Int,非分片 |
| 时序数据 | 任意规模 | 按时间窗口 | 1-24小时数据 | 与查询时间范围对齐 |
| 用户行为分析 | >5 亿 | 用户分桶 | 10-50万用户/桶 | 与业务维度对齐 |
- 长规分片建议
| 总元素规模 | 32位整数推荐分片 | 64位整数推荐分片 | 关键修正说明 |
|---|---|---|---|
| ≤ 4000 万 | 1 | 1-4 | 32 位整数无需分片,64 位需控制 high-key |
| 4000 万 – 2 亿 | 4-8 | 8-16 | 32 位版单对象 > 200MB 时 GC 压力剧增 |
| 2 亿 – 10 亿 | 16-32 | 16-64 | 64 位版必须监控 high-key /分片< 500 |
| > 10 亿 | 32-64 | 映射压缩优先 |
e、高位随机:Long-to-Int 映射
- 优势:
- 内存降低 60–80%(实测 1 亿随机 long 从 4.2GB → 800MB)
- 支持超大规模(10 亿+ ID 可行)
- 代价:
- 额外映射表存储(约 12B/ID)
- 查询增加 1 次映射开销(微秒级)
// 步骤1: 建立全局映射 (存储在Redis/LevelDB)
Map<Long, Integer> globalIdMap = new OffHeapMap(); // 使用堆外存储
// 步骤2: 转换后使用 32 位 RoaringBitmap
RoaringBitmap usersInExperiment = new RoaringBitmap();
for (Long userId : rawUserIds) {
int compactId = globalIdMap.computeIfAbsent(userId, k -> assignNewId());
usersInExperiment.add(compactId);
}
// 步骤3: 查询时反向转换
for (Integer compactId : usersInExperiment) {
Long originalId = globalIdMap.reverseLookup(compactId);
// 处理业务逻辑
}
5)Roaring64Bitmap 和 Roaring64NavigableMap 比较
| 特性 | Roaring64Bitmap |
Roaring64NavigableMap |
|---|---|---|
| 底层结构 | LongKeyMap<RoaringBitmap> (优化HashMap) |
TreeMap<Long, RoaringBitmap> (红黑树) |
| 存储原理 | 高32位→桶索引,低32位→32位 RoaringBitmap |
同左,但桶按高32位有序存储 |
| 首次添加0L | 分配1个容器 | 分配1个容器 + 红黑树节点(48B) |
| 序列化格式 | 自定义二进制(紧凑) | 兼容标准TreeMap(冗余) |
| 元素顺序 | 无序 | 严格升序(按64位值) |
| 范围查询 | 需遍历全部数据 | 高效范围扫描(subMap/headMap) |
| 内存占用 | 略低(无树节点开销) | 略高(树结构指针开销) |

// Roaring64NavigableMap 独有功能
Roaring64NavigableMap bitmap = new Roaring64NavigableMap();
bitmap.add(100L);
bitmap.add(200L);
// 范围导航 (Roaring64Bitmap无法高效实现)
long after150 = bitmap.higher(150); // 返回200
long last = bitmap.last(); // 返回200
// 范围视图
NavigableMap<Long, RoaringBitmap> subrange = bitmap.subMap(50L, true, 150L, true); // [100]
Roaring64NavigableMap 在时序数据和范围查询场景中无可替
| 方法 | 定义 | 性能关键点 | 替代成本 |
|---|---|---|---|
ceiling() |
返回大于等于给定 key 的最小键,若不存在返回 null |
O(log n) 直达 | 扫描全部high-key |
floor() |
返回小于等于给定 key 的最大键,若不存在返回 null |
O(log n) 回溯 | 全量排序+二分查找 |
pollFirst() |
检索并移除第一个(最小)键值对,若为空返回 null |
O(log n) 移除 | 两次O(n)扫描 |
subMap() |
返回指定范围 [fromKey, toKey) 的视图(不复制数据!) | 零拷贝视图 | 复制100%数据 |
5、实现方案- Redis 实现压缩
Redis本身是支持Bitmap存储的,但是压缩的Bitmap是不支持的。根据上面的原理,同样可以把一个大的Bitmap转成一个个小的Bitmap来达到压缩的目的。
1)方案实现
a、CompressedBitInfo
@Data
public class CompressedBitInfo {
/**
* 真实offset
*/
private long sourceOffset;
/**
* 分桶的编号
*/
private long bucketIndex;
/**
* 桶内的offset
*/
private long bucketOffset;
/**
* key
*/
private String bitKey;
/**
* bitValue
*/
private Boolean bitValue;
}
b、CompressedBizBO
@Data
public class CompressedBizBO {
/**
* key
*/
private String key;
/**
* 过期时间
*/
private Integer expireSeconds;
/**
* 桶大小
*/
private Long bucketSize;
}
c、CompressedBitUtils
@Slf4j
public class CompressedBitUtils {
/**
* 设置压缩位图在offset上的值,并且设置过期时间(秒)
*/
public static CompressedBitInfo setCompressedBit(CompressedEnum.CompressedInfoEnum compressedInfoEnum,
long offset) {
return setCompressedBit(compressedInfoEnum, offset, true);
}
/**
* 删除压缩位图在offset上的值(相当于设置为false)
*/
public static CompressedBitInfo remCompressedBit(CompressedEnum.CompressedInfoEnum compressedInfoEnum,
long offset) {
return setCompressedBit(compressedInfoEnum, offset, false);
}
/**
* 设置压缩位图在offset上的值,并且设置过期时间(秒)
*/
public static CompressedBitInfo setCompressedBit(CompressedEnum.CompressedInfoEnum compressedInfoEnum,
long offset,
boolean value) {
FilterCompressedConfiguration filterCompressedConfiguration = SpringUtils.getBean(FilterCompressedConfiguration.class);
CompressedBizBO compressedBiz = filterCompressedConfiguration.getCompressedBizMap().get(compressedInfoEnum.getCode());
CompressedBitInfo bitInfo = getBitInfo(compressedInfoEnum, offset);
String bitKey = bitInfo.getBitKey();
RedisService redisService = SpringUtils.getBean(RedisService.class);
redisService.setBit(bitKey, bitInfo.getBucketOffset(), value);
redisService.expire(bitKey, compressedBiz.getExpireSeconds());
long sourceOffset = getSourceOffset(compressedInfoEnum, bitInfo.getBucketIndex(), bitInfo.getBucketOffset());
bitInfo.setSourceOffset(sourceOffset);
bitInfo.setBitValue(value);
return bitInfo;
}
/**
* 获取压缩位图在offset上的值
*/
public static CompressedBitInfo getCompressedBit(CompressedEnum.CompressedInfoEnum compressedInfoEnum, long offset) {
CompressedBitInfo bitInfo = getBitInfo(compressedInfoEnum, offset);
String bitKey = bitInfo.getBitKey();
log.debug("getCompressedBit with key:{}, offset:{}", bitKey, bitInfo.getBucketOffset());
RedisService redisService = SpringUtils.getBean(RedisService.class);
Boolean bitValue = redisService.getBit(bitKey, bitInfo.getBucketOffset());
long sourceOffset = getSourceOffset(compressedInfoEnum, bitInfo.getBucketIndex(), bitInfo.getBucketOffset());
bitInfo.setSourceOffset(sourceOffset);
bitInfo.setBitValue(bitValue);
return bitInfo;
}
/**
* 获取压缩位图每个小桶的子key集合
*/
public static List<String> getAllBucketKeys(CompressedEnum.CompressedInfoEnum compressedInfoEnum, long maxOffset) {
List<String> result = Lists.newArrayList();
FilterCompressedConfiguration filterCompressedConfiguration = SpringUtils.getBean(FilterCompressedConfiguration.class);
CompressedBizBO compressedBiz = filterCompressedConfiguration.getCompressedBizMap().get(compressedInfoEnum.getCode());
CompressedBitInfo bitInfo = getBitInfo(compressedInfoEnum, maxOffset);
for (int i = 0; i <= bitInfo.getBucketIndex(); i++) {
String bitKey = getBitKey(compressedBiz.getKey(), i);
result.add(bitKey);
}
return result;
}
/**
* 删除所有桶里的的Bitmap
*/
public static void deleteAllCompressedBit(CompressedEnum.CompressedInfoEnum compressedInfoEnum, long maxOffset) {
FilterCompressedConfiguration filterCompressedConfiguration = SpringUtils.getBean(FilterCompressedConfiguration.class);
CompressedBizBO compressedBiz = filterCompressedConfiguration.getCompressedBizMap().get(compressedInfoEnum.getCode());
CompressedBitInfo bitInfo = getBitInfo(compressedInfoEnum, maxOffset);
for (int i = 0; i < bitInfo.getBucketIndex(); i++) {
String bitKey = getBitKey(compressedBiz.getKey(), i);
RedisService redisService = SpringUtils.getBean(RedisService.class);
redisService.expire(bitKey, 0);
}
}
/**
* 将java中的bitmap转换为redis的字节数组
*/
private static byte[] getByteArray(List<Long> bits) {
Iterator<Long> iterator = bits.iterator();
BitSet bitSet = new BitSet();
while (iterator.hasNext()) {
long offset = iterator.next();
bitSet.set((int) offset);
}
byte[] targetBitmap = bitSet.toByteArray();
convertJavaToRedisBitmap(targetBitmap);
return targetBitmap;
}
/**
* 将java中的字节数组转换为redis的bitmap数据形式
*
* @param bytes
*/
private static void convertJavaToRedisBitmap(byte[] bytes) {
int len = bytes.length;
for (int i = 0; i < len; i++) {
byte b1 = bytes[i];
if (b1 == 0) {
continue;
}
byte transByte = 0;
for (byte j = 0; j < 8; j++) {
transByte |= (b1 & (1 << j)) >> j << (7 - j);
}
bytes[i] = transByte;
}
}
/**
* getBitInfo
*/
public static CompressedBitInfo getBitInfo(CompressedEnum.CompressedInfoEnum compressedInfoEnum, long sourceOffset) {
FilterCompressedConfiguration filterCompressedConfiguration = SpringUtils.getBean(FilterCompressedConfiguration.class);
CompressedBizBO compressedBiz = filterCompressedConfiguration.getCompressedBizMap().get(compressedInfoEnum.getCode());
CompressedBitInfo bucketInfo = new CompressedBitInfo();
bucketInfo.setSourceOffset(sourceOffset);
long bucketSize = compressedBiz.getBucketSize();
long bucketIndex = sourceOffset / bucketSize;
bucketInfo.setBucketIndex(bucketIndex);
long bucketOffset = sourceOffset % bucketSize;
bucketInfo.setBucketOffset(bucketOffset);
String bitKey = getBitKey(compressedBiz.getKey(), bucketIndex);
bucketInfo.setBitKey(bitKey);
return bucketInfo;
}
public static String getBitKey(String key, long bucketIndex) {
return new StringBuffer(key).append("_").append(bucketIndex).toString();
}
/**
* getSourceOffset
*
* @param bucketIndex bucketIndex
* @param bucketIndex bucketIndex
* @param bucketOffset bucketOffset
* @return {@link long}
*/
public static long getSourceOffset(CompressedEnum.CompressedInfoEnum compressedInfoEnum, long bucketIndex, long bucketOffset) {
FilterCompressedConfiguration filterCompressedConfiguration = SpringUtils.getBean(FilterCompressedConfiguration.class);
CompressedBizBO compressedBiz = filterCompressedConfiguration.getCompressedBizMap().get(compressedInfoEnum.getCode());
return bucketIndex * compressedBiz.getBucketSize() + bucketOffset;
}
}
d、CompressedEnum
public interface CompressedEnum {
/**
* CompressedKeyEnum
*/
@Getter
@AllArgsConstructor
enum CompressedInfoEnum implements CompressedEnum {
DEFAULT("default", "默认"),
;
/**
* key
*/
private final String code;
/**
* 描述
*/
private final String desc;
}
}
e、FilterCompressedConfiguration
@Slf4j
@Data
@Configuration
@ConfigurationProperties("filter")
public class FilterCompressedConfiguration {
/**
* 压缩过滤器配置
*/
private Map<String, CompressedBizBO> compressedBizMap;
}
2)Redis 高效写入
由于直接
setbit的方式写入数据耗时太长,因此探索了如下方式:一次写入一个字节数组的数据,增加每次的写入量,并减少写入次数,最终达到快速写入的目的。
1、首先,将 bitmap 进行拆分,生成一个个小的 bitmap ,经过测试小 bitmap 的大小维持在 65536 时比较合理。
2、然后,将 Java Bitmap 转换为 Java 字节,再将 Java 字节转换为 Redis 字节,通过 Set key byte的方式写入 Redis 缓存。
问题1:为什么要将 Java 字节转换为 Redis 字节,然后再写入呢?直接将 Java 的 BitSet 使用 toByteArray() 转换成字节数组,然后写入到 Redis 中不行么?
答案:实际上写入是可以的,但是读取数据的时候,就不能直接使用 Redis 的 getbit 方法来直接判断指定偏移量 offset 的值了,因为接口性能还需要 getbit 方法来保障。
**问题2:那为什么不能直接写入并读取 **
答案:这是因为 Java 字节和 Redis 字节在存储结构上不相同 ,一个是大端存储,一个是小端存储,,一个 8 位的 byte:00000010,Java 中表示 2 ,就是说从右向左是第二位为true ;但是 Redis 中是从左向右读,表示偏移量为 6 的为 true,正好相反。
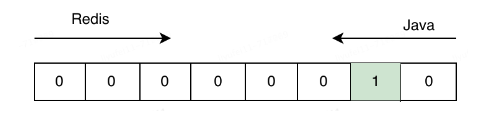
/**
* 将java中的bitmap转换为redis的字节数组
*
*/
private byte[] getByteArray(List<Long> bits) {
Iterator<Long> iterator = bits.iterator();
BitSet bitSet = new BitSet();
while (iterator.hasNext()) {
long offset = iterator.next();
bitSet.set((int) offset);
}
byte[] targetBitmap = bitSet.toByteArray();
convertJavaToRedisBitmap(targetBitmap);
return targetBitmap;
}
/**
* 将java中的字节数组转换为redis的bitmap数据形式
*
* @param bytes
*/
private static void convertJavaToRedisBitmap(byte[] bytes) {
int len = bytes.length;
for (int i = 0; i < len; i++) {
byte b1 = bytes[i];
if (b1 == 0) {
continue;
}
byte transByte = 0;
for (byte j = 0; j < 8; j++) {
transByte |= (b1 & (1 << j)) >> j << (7 - j);
}
bytes[i] = transByte;
}
}
3)数据加载策略(42.94 亿)
65536个桶,每个桶65536个offset(ID)40亿 大概500M(2^32/8/1024/1024)左右。
优点:
1、单值小:每个 bitmap 最多有 65536 个 Offset(bit 位),相当于最大 8kb ,不会在缓存中产生较大 key 而导致性能差
2、写入快:每个key 一次性写入到缓存,但是最多可以含有 65536 个 offset(ID),42.94 亿群体只需要 65536 次写入
3、查询效率高:getbit 支持查询 key 下面每个 offset ,时间复杂度是 O(1)
4、拆分压缩数据:拆分多个小的 bitmap ,相当于是对 bitmap 进行了压缩
三、建议
- 位图天然不适合“反查”
| 用途 | 数据结构 | Key 示例 |
|---|---|---|
| 圈人选人(标签 → 用户) | RoaringBitmap(本地 or Redis) |
tag:vip → Roaring(user_ids) |
| 查用户标签(用户 → 标签) | Redis Set / Hash |
user:tags:10086 → {vip, new_user, ...} |
1、内存压缩位图
1)优点
- 内存占用极小:对于稀疏数据具有极高压缩率。例如:
-
32位RoaringBitmap最多支持约42.9 亿(2³²)个元素,典型稀疏场景下仅需 几十MB到几百MB。 -
64位Roaring64NavigableMap同样高效:即使存储上亿个非连续long ID(如用户ID跨越10¹⁵),内存通常控制在500MB~2GB内(取决于密度)。
-
- 零
RPC查询延迟:数据全量加载至本地内存,查询完全本地化,TP999 < 1ms,无网络抖动。 - 批量标签合并效率高:多个业务标签(位图)可在本地直接执行
AND/OR/XOR 等集合运算,大幅减少对外 RPC 调用次数,尤其适合“多标签交并”类实时过滤场景。
2)缺点
- 启动慢、冷启动成本高:
- 应用重启时需从
OSS/S3/HDFS全量加载所有群体文件到内存 - 加载时间随数据量线性增长(如 10GB 文件可能需数分钟)。
- 应用重启时需从
- 运维能力弱:缺乏成熟的监控手段:无法直观查看“当前加载了哪些群体”、“内存中位图大小”、“
GC影响”等。 - 物理内存压力大,影响
JVMGC:- 大对象(如数百
MB的RoaringMap)驻留堆内 - 易导致
FullGC频繁或STW时间变长,影响服务稳定性。
- 大对象(如数百
3)FAQ
a、规模:内存预估
- 10 万稀疏局部连续
- 32 位版:0.3~1.5 MB
- 64 位 HashMap:0.6~2.2 MB
- 64 位 TreeMap:0.8~2.8 MB
- 100 万中度稀疏
- 32 位版:4~12 MB
- 64 位 HashMap:7~15 MB
- 64 位 TreeMap:8.5~18 MB
- 500 万局部密集
- 32 位版:18~45 MB(实际常 <30 MB,运行长度编码压缩效果好)
- 64 位 TreeMap:38~85 MB
- 1 亿稀疏局部连续
-
32 位版:25~70 MB
-
64 位 TreeMap:55~135 MB(high-key ≤500) 时
-
- 10 亿中度稀疏(high-key ≤10,000)
- 32 位版:不适用(超过 42.9 亿上限)
- 64 位
HashMap:400~750 MB - 64 位
TreeMap:500 MB~1 GB
- 10 亿完全随机(high-key ≈50 万)
- 64 位 HashMap:3.5~6.5 GB
- 64 位 TreeMap:4.2~7.8 GB
- 生产环境危险:GC 停顿 >300ms,Full GC >2 秒
- 50 亿数据
- 32 位版完全不可用
- 高位连续(时序数据):2~4 GB(推荐场景)
- 完全随机:内存爆炸(>16 GB),必须换方案
b、选型 决策指南
- 选 32 位
RoaringBitmap 当:- 数据 ≤40 亿
- 无 64 位整数需求
- 需要最低内存开销
- 选 64 位
HashMap当:high-key≤10,000- 不需要范围查询
- 内存敏感型应用
- 选 64 位
TreeMap当:high-key≤5,000- 需要
ceiling()/floor()操作 - 需要高效范围查询
4)适用场景
- 超高
TPS、低延迟要求的在线服务(如广告实时定向、风控拦截)。 - 多标签组合查询(如“北京+女性+近7天活跃”)。
- 可接受较长启动时间,且有足够物理内存保障。
2、 Redis 自研压缩位图
1)优点
- 内存与计算解耦:位图数据不常驻应用内存,避免 JVM 堆压和 GC 问题。
- 无需冷启动加载:应用启动快,按需从
Redis拉取所需群体。 - 保留压缩优势:大幅节省 Redis 内存**(尤其对稀疏/非连续 ID)。
2)缺点
- 引入一次
RPC开销:- 每次查询需
GET key → deserialize → compute - TP999 延迟受 Redis 网络和反序列化影响(通常 2–
10ms)。
- 每次查询需
- 多标签场景需多次请求
- 若需合并 5 个标签,则需 5 次 Redis GET(除非使用 pipeline 或 Lua 批量获取)。
- 标签越多,总耗时线性增长,难以满足超低延迟要求。
Redis集群分片管理复杂:- 数据量大的情况下,
key分散, - 大
value(如 >10MB)可能影响Redis性能,需合理设计 key 分片策略。
- 数据量大的情况下,
3)适用场景
- 中高 TPS 场景,可容忍几毫秒延迟。
- 标签数量较少(≤3 个)的实时判断,如“判断用户是否在 VIP 群体”。
- 不希望应用内存被位图长期占用,追求快速弹性扩缩容。
- 建议
32位使用,64位实现复杂,而且内存占用不好评估
3、普通 Redis Key-Value
1)优点
- 灵活性极高:可存储任意结构(
JSON、Protobuf、业务字段等)。 - 支持丰富操作:如
Hash的HGETALL、TTL、原子计数等。 - 运维成熟:
Redis自带监控、慢日志、内存分析工具。
2)缺点
- 内存效率极低
- 存储一个布尔状态(如签到)需完整
key(如"sign:uid:20251117"),每个 key 开销约 50–100 字节。 - 百万级用户 × 365 天 ≈ 数亿
keys,内存爆炸(可能达数十 GB)。
- 存储一个布尔状态(如签到)需完整
- 无法高效聚合统计:无法直接计算“本月签到人数”,需遍历或依赖外部计算。
- 不适合位图语义场景:本质是“用 KV 模拟位图”,属于反模式。
3)适用场景
- 需要附带业务属性的场景(如“用户签到 + 奖励积分”)。
- 非布尔型、结构化数据存储(如用户画像字段、配置项)。
- 数据量小、查询简单的辅助缓存。
