领域驱动设计领域建模_3_领域模型设计要素
前言
Github:https://github.com/HealerJean
一、实体
实体(
entity) 这个词被我们广泛使用,甚至过分使用。设计数据库时,我们用到实体。实体必须包括属性与行为。一个典型的实体应该具备3个要素:**1、身份标识;2、属性;3、领域行为。 **实体无须承担 “增删改查” 的职责。实体拥有的变更状态的领域行为,修改的只是对象的内存状态,与持久化无关
1、身份标识
身份标识(
identity,简称为ID)是实体对象的必要标志,在领域驱动设计中,没有身份标识的领域对象就不是实体。⬤ 一些实体只要求身份标识具有唯一性即可,如评论(
Comment)实体、博客 (Blog)实体或文章(Article)实体的身份标识,都可以使用自动增长的Long类型、随机数、UUID或GUID。这样的身份标识并无任何业务含义。⬤ 有些实体的身份标识规定了一定的组合规则,例如公民 (
Citizen)实体、员工(Employee)实体与订单(Order)实体的身份标识,遵循了一定的业务规则。这样的身份标识蕴含了领域知识,体现了领域概念,1、订单(
Order)实体可能会将下单渠道号、支付渠道号、业务类型、下单日期组装在订单ID中2、公民 (
Citizen)实体的身份标识就是“公民身份号码”这一领域概念。定义规则的好处在于我们可以通过解析身份标识获取有用的领域信息,例如解析订单号即可获知该订单的下单渠道、支付渠道、业务类型与下单日期等,解析一个公民的身份号码可以直接获得该公民的部分基础信息,如出生日期、性别等。”
2、属性
实体的属性 用来说明主体的静态特征,并持有数据与状态。
通常,我们会依据粒度的粗细将属性分为原子属性与组合属性。
⬤ 原子属性:定义为开发语言内建类型的属性就是原子属性,如整型、布尔型、字符串类型等,表述了不可再分的属性概念。
⬤ 组合属性:通过自定义类型来表现,可以封装高内聚的一系列属性,实则也体现了主体内嵌的领域概念。
public class Product extends Entity<ProductId> {
private String name;
private int quantity;
private Category category;
private Weight weight;
private Volume volume;
private Price price;
}
⬤ Product 实体的 name、quantity 属性属于原子属性,分别被定义为 String 与 int 类型;
⬤ category、weight、volume、price 等属性为组合属性,类型为自定义的 Category、Weight、Volume 和 Price 类型
问题1:两种属性间是否存在分界线?例如,能否将 category 定义为 String 类型,将 weight 定义为 double 类型?又或者,能不能将 name 定义为 Name 类型,将 quantity 定义为 Quantity 类型?
答案:划定这条边界线的标准就是:该属性是否存在约束规则、组合因子或属于自己的领域行为。
1)约束规则
1、相较于产品的名称
(name) 属性而言,产品的类别 (category) 属性具有更强的约束性。产品的类别多而细,且存在一个复杂的层次结构,单单靠一个字符串无法表达如此丰富的约束条件与层次结构。2、如果需求对产品名称也有明确的约束,例如长度约束、字符内容约束,自然也应该将其定义为
Name类型。
2)组合因子
判断属性是否不可再分,如重量 (
weight) 与体积(volume)属性有着明显的特征:需要值与计数单位共同组合。如果只有值而无单位,就会因为单位不同导致计算错误、概念混乱,例如,2kg与2g显然是不同的值,不能混为一谈。至于数量(
quantity) 属性之所以被设计为原子属性,是因为在当前业务背景下假定它没有计数单位的要求,无须组合。如果需求要求商品数量的单位存在诸如万、亿的变化,又或者以箱、盒、件等不同的量化单位区分不同的商品,作为原子属性的quantity就缺乏业务的表现能力,必须定义为组合属性。
3)领域行为
多数静态语言不支持为内建类型扩展自定义行为,要为属性添加属于自己的领域行为,只能选择组合属性。如
Product的价格(price) 属性需要提供针对该领域概念的运算行为,若不定义为Price组合属性,就无法封装这些领域行为。
3、领域行为
实体拥有领域行为,可以更好地说明其作为主体的动态特征。一个不具备动态特征的对象,是一个哑对象,一个“蠢”对象。这样的对象明明坐拥宝山(自己的属性)而不自知,还去求助他人操作自己的状态,着实有些“愚蠢”。
1)变更状态的领域行为
实体对象的状态由属性持有。实体对象允许调用者更改其状态。
1、许多语言都支持通过
get与set访问器(或类似的语法糖)访问状态,这实际上是技术因素干扰着领域模型的设计。2、领域驱动设计认为,由业务代码组成的实现模型是领域模型的一部分,业务代码中的类名、方法名应从业务角度表达领域逻辑。领域专家最好也能够参与到编程元素的命名讨论上,使得业务代码遵循统一语言。
如果不考虑一些框架对实体类
get/set访问器的限制,应让变更状态的方法名满足业务含义。例如,修改产品价格的领域行为应该定义为changePriceTo(newPrice)方法,而非setPrice(newPrice):
public class Product extends Entity<ProductId> {
public void changePriceTo(Price newPrice) {
if (!this.price.sameCurrency(newPrice)) {
throw new CurrencyException("Cannot change the price of this product to a different currency");
}
this.sellingPrice = newPrice;
}
}
这时的领域行为不再是一个简单的设置操作,它蕴含了领域逻辑。方法名也传递了业务知识,突破了 set 访问器的范畴,成了实体类拥有的领域行为,也满足了信息专家模式的要求,形成了对象之间行为的协作。
2)自给自足的领域行为
自给自足意味着实体对象只操作了自己的属性,不外求于别的对象。这种领域行为最容易管理,因为它不会和别的实体对象产生依赖。即使实现逻辑发生了变化,只要定义好的接口无须调整,就不会将变化传递出去。
例如,一个订单结算
OrderSettlement实体定义了payNumber、paidAmount和payments属性。payments属性为List<Payment>类型。订单结算实体定义了计算总额的领域行为。正常情况下,订单结算的总额就是paidAmount的值,但是,当payNumber的值等于payments的记录个数时,需要检查payments的总额是否等于paidAmount。如果不相等,就要抛出异常来说明订单结算存在问题。该领域行为对应的方法totalAmount()定义为:
public class OrderSettlement extends Entity<OrderSettlementId> {
private Integer payNumber;
private Money payAmount;
private List<Payment> payments;
public Money totalAmount() {
if (payNumber == payments.size()) {
if (!payAmount.equals(totalPayAmount())) {
throw new OrderSettlementException("Error with calculating total price for Order Settlement.");
}
}
return payAmount;
}
private Money totalPayAmount() {
Money totalAmount = new Money(0);
for (Payment payment : payments) {
totalAmount = totalAmount.add(payment.getPayAmount());
}
return totalAmount;
}
}
3)互为协作的领域行为
实体不可能都做到自给自足,有时也需要调用者提供必要的信息。这些信息往往通过方法参数传入,这就形成了领域对象之间互为协作的领域行为。
TradeOrder与TaxAdjustments根据自己拥有的数据各自计算自己的税额部分,从而完成合理的职责协作。这种协作方式体现了职责的分治
public class TaxAdjustments {
private List<TaxAdjustment> taxAdjustments;
private BigDecimal zero = BigDecimal.ZERO.setScale(taxDecimals, taxRounding);
public BigDecimal totalTaxAdjustments() {
return taxAdjustments
.stream
.reduce(zero, (ta, agg) -> agg.add(ta.getAmount()));
}
public BigDecimal manuallyAddedTaxAdjustments() {
return taxAdjustments
.stream
.filter(ta -> ta.isManual())
.reduce(zero, (ta, agg) -> agg.add(ta.getAmount()));
}
}
public class TradeOrder {
public BigDecimal calculateTotalTax(TaxAdjustments taxAdjustments) {
BigDecimal existedOrderTax = taxAdjustments.totalTaxAdjustments();
BigDecimal manuallyAddedOrderTax = taxAdjustments.manuallyAddedTaxAdjustments();
BigDecimal taxDifference = existedOrderTax
.substract(manuallyAddedOrderTax).setScale(taxDecimals, taxRounding);
return totalAmount().multiply(taxDifference).setScale(taxDecimals, taxRounding);
}
}
二、值对象
值对象 (
valueobject) 通常作为实体的属性。1、当我们只关心一个模型元素的属性时,应把它归类为值对象。值对象是不可变的。不要为它分配任何标识
2、在进行领域设计建模时,可优先考虑使用值对象而非实体对象建模。值对象没有唯一标识,就可以卸下管理身份标识的负担。值对象设计为不变的,就不用考虑并发访问带来的问题,因此比实体对象更容易维护,更容易测试,更容易优化,也更容易使用,它是设计建模模型元素的第一选择。
1、值对象与实体的本质区别
实体与值对象的本质区别在于是否拥有唯一的身份标识
问题1:一个领域概念到底该用值对象还是实体类型
| 判断标准 | 实体 | 值对象 |
|---|---|---|
| 对象身份标识判断 | 依据值 | 依据身份标识 |
| 对象的属性值是否变化 | 如果变化了,维持相同的标识 | 如果变化了,是完全不同的对象 |
| 对象生命周期的管理 | 实体在创建之后,系统就需要负责跟踪它状态的变化情况,直到它被删除。有的对象虽然通过值进行相等性判断,但在具体业务场景中,又可能面对生命周期管理的需求。这时,就需要将该对象定义为实体 | 值对象没有身份标识,无须管理其生命周期,从对象的角度看,它可以随时被创建或被销毁,甚至也可以被随意克隆用到不同的业务场景 |
2、不变性
考虑到值对象只需关注值的特点,领域驱动设计建议尽量将值对象设计为不变类。若能保证值对象的不变性,就可以减少并发控制的成本,因为一个不变的类是线程安全的。
举例:Money 类的 faceValue 与 currency 字段均被声明为 final 字段,由构造函数初始化。faceValue 字段的类型为不变的double 类型,currency 字段为不变的枚举类型。add() 与 minus() 方法并没有直接修改当前对象的值,而是返回了一个新的 Money 对象。显然,既要保证对象的不变性,又要满足更新状态的需求,就需要用一个保存了新状态的实例来“替换”原有的不可变对象。
这种方式看起来会导致大量对象被创建,从而占用不必要的内存空间,影响程序的性能,但事实上,由于值对象往往比较小,内存分配的开销并没有想象中的大。由于不可变对象本身是线程安全的,无须加锁或者提供保护性副本,因此它在并发编程中反而具有性能优势。
@Immutable
public final class Money {
private final double faceValue;
private final Currency currency;
public Money() {
this(0d, Currency.RMB)
}
public Money(double value, Currency currency) {
this.faceValue = value;
this.currency = currency;
}
public Money add(Money toAdd) {
if (!currency.equals(toAdd.getCurrency())) {
throw new NonMatchingCurrencyException("You cannot add money with different currencies.");
}
return new Money(faceValue + toAdd.getFaceValue(), currency);
}
public Money minus(Money toMinus) {
if (!currency.equals(toMinus.getCurrency())) {
throw new NonMatchingCurrencyException("You cannot remove money with different currencies.");
}
return new Money(faceValue - toMinus.getFaceValue(), currency);
}
}
3、领域行为
值对象的名称容易让人误会它只该拥有值,不应拥有领域行为。实际上,只要采用了对象建模范式,无论实体对象还是值对象,都需要遵循面向对象设计的基本原则,之所以将其命名为值对象,是为了强调对它的领域概念身份的确认,即关注重点在于值。
值对象拥有的往往是 “自给自足的领域行为”。这些领域行为能够让值对象的表现能力变得更加丰富,更加智能。它们通常为值对象提供如下能力:
1)自我验证
当一个值对象拥有自我验证的能力时,拥有和操作值对象的实体类就会变得轻松许多。否则,实体类就可能充斥大量的验证代码,干扰了读者对主要领域逻辑的理解。
按照职责分配的要求,一旦实体的属性定义为值对象,就连带着需要将属性值的验证职责也转移到值对象,做到自我验证。
⬤ 自我验证提高程序健壮性: 自我验证方法保证了值对象的正确性。如果我们将每个组成实体属性的值对象都定义为具有自我验证能力的类,就可以使得组成程序的基本单元变得更加健壮,间接提高了整个软件系统的健壮性。值对象的验证逻辑是领域逻辑的一部分,我们应为其编写单元测试。
⬤ 不可协助外部资源:自我验证的领域行为仅验证外部传入的设置值。倘若验证功能还需求助外部资源,例如查询数据库以检查 name 是否已经存在,这样的验证逻辑就不再是 “自给自足”的,不能交由值对象承担。
public final class ZipCode {
private final String zipCode;
public ZipCode(String zipCode) {
validate(zipCode);
this.zipCode = zipCode;
}
public String value() {
return this.zipCode;
}
private void validate(String zipCode) {
if (Strings.isNullOrEmpty(zipCode)) {
throw new InvalidZipCodeException("Zip code could not be null or empty");
}
if (!isValid(zipCode)) {
throw new InvalidZipCodeException("Valid zip code is required");
}
}
private boolean isValid(String zipCode) {
String reg = "[1-9]\\d{5}";
return Pattern.matches(reg, zipCode);
}
}
public class Address {
private final String province;
private final String city;
private final String street;
private final ZipCode zip;
public Address(String province, String city, String street, ZipCode zip) {
validate(province, city, street, zip); // 方法中还需要验证zip为null的情况
this.province = province;
this.city = city;
this.street = street;
this.zip = zip;
}
}
2)自我组合
值对象往往牵涉对数据值的运算。为了更好地表达其运算能力,可定义相同类型值对象的组合运算方法,使得值对象具备自我组合能力
public enum LengthUnit {
MM(1),
CM(10),
DM(100),
M(1000);
private int ratio;
LengthUnit(int ratio) {
this.ratio = ratio;
}
int convert(Unit target, int value) {
return value * ratio / target.ratio;
}
}
LengthUnit 枚举的字段值 ratio 并未定义 getRatio() 方法,因为该数据并不需要提供给外部调用者。当 Length 对象计算长度时,若需单位换算,可以调用 LengthUnit 的 convert() 方法,而不是获得 ratio 的换算比例。这才是正确的行为协作模式:
public class Length {
private int value;
private LengthUnit unit;
public Length() {
this(0, LengthUnit.MM)
}
public Length(int value, LengthUnit unit) {
this.value = value;
this.unit = unit;
}
public Length add(Length toAdd) {
int convertedValue = toAdd.unit.convert(this.unit, toAdd.value);
return new Length(convertedValue + this.value, this.unit);
}
}
3)自我运算
自我运算是根据业务规则对属性值进行运算的行为。根据需要,参与运算的值也可以通过参数传入。例如,
Location值对象拥有longitude与latitude属性值,只需再提供另一个地理位置,就可计算两个地理位置之间的直线距离:
@Immutable
public final class Location {
private final double longitude;
private final double latitude;
public Location(double longitude, double latitude) {
this.longitude = longitude;
this.latitude = latitude;
}
public double getLongitude() {
return this.longitude;
}
public double getLatitude() {
return this.latitude;
}
public double distanceOf(Location location) {
double radiansOfStartLongitude = Math.toRadians(longitude);
double radiansOfStartDimension = Math.toRadians(latitude);
double radiansOfEndLongitude = Math.toRadians(location.getLongitude());
double raidansOfEndDimension = Math.toRadians(location.getLatitude());
return Math.acos(
Math.sin(radiansOfStartLongitude) * Math.sin(radiansOfEndLongitude) +
Math.cos(radiansOfStartLongitude) * Math.cos(radiansOfEndLongitude) *
Math.cos(raidansOfEndLatitude - radiansOfStartLatitude)
);
}
}
在定义了计算距离的领域行为后,Location 对象就拥有了运算的能力,可以与其他领域模型对象产生行为的协作。例如,要查询距当前位置最近的餐厅,领域服务 RestaurantService 调用了Location 的 distanceOf() 方法
public class RestaurantService {
private static long RADIUS = 3000;
private RestaurantRepository restaurantRepo;
@Override
public Restaurant neareastRestaurant(Location location) {
List<Restaurant> restaurants = restaurantRepo.allRestaurantsOf(location, RADIUS);
if (restaurants.isEmpty()) {
throw new RestaurantException("Required restaurants not found.");
}
Collections.sort(restaurants, new RestaurantComparator(location));
return restaurants.get(0);
}
private final class RestaurantComparator implements Comparator<Restaurant> {
private Location currentLocation;
public RestaurantComparator(Location currentLocation) {
this.currentLocation = currentLocation;
}
@Override
public int compare(Restaurant r1, Restaurant r2) {
return r1.getLocation().distanceOf(currentLocation)
.compareTo(r2.getLocation().distanceOf(currentLocation));
}
}
}
三、聚合
在理解聚合(
aggregate)的概念之前,需要先理清面向对象设计中类之间的关系。”
1、类的关系
正如生活中的我们难以做到“老死不相往来”,类之间必然存在关系。如此才可以通力合作。
1)泛华关系、继承关系
泛化关系体现了通用的父类与特定的子类之间的关系。在编程语言中往往表示为子类继承父类或子类派生自父类。父类定义通用的特征,特化的子类在继承了父类的特征之外,定义了符合自身特性的特殊实现。泛化关系在
UML类图中以空心三角形加实线的形式表现。泛化关系会导致子类与父类之间的强耦合,父类发生的任何变更都会传递给子类,形成所谓的“脆弱的基(父)类”。修改父类的实现需要慎之又慎,因为一处变更就可能影响到它的所有子类,悄悄地改变子类的行为。在面向对象设计要素中,我们往往使用继承这一术语来表示泛化关系。
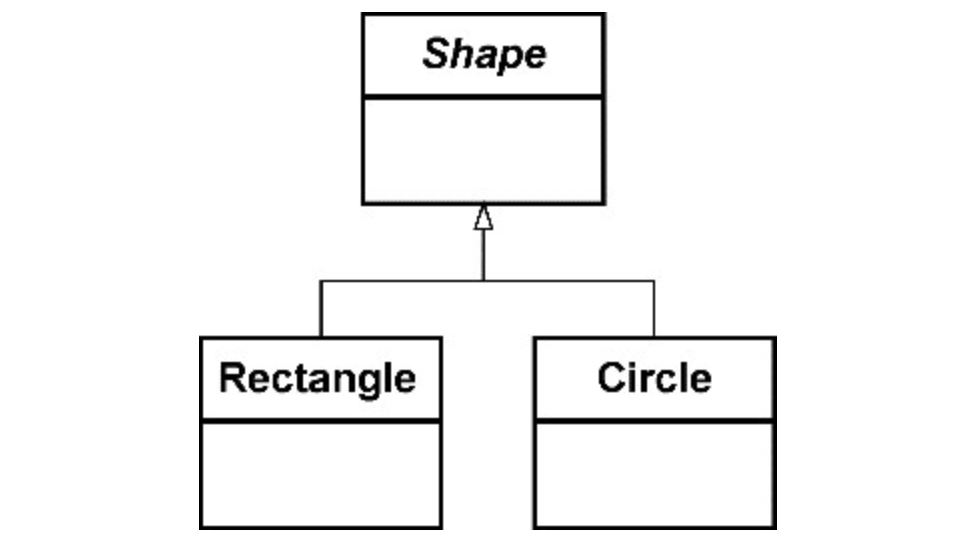
2)关联关系
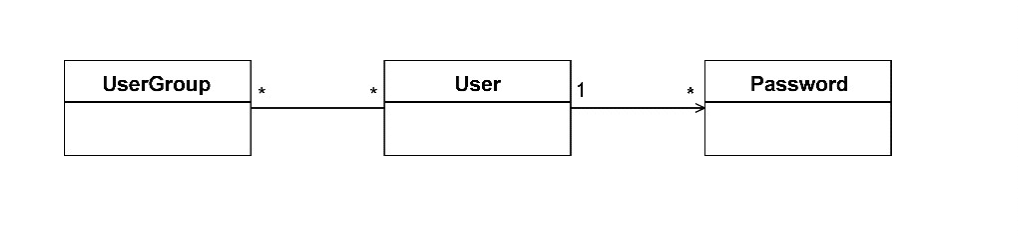
关联关系代表了类之间的一种结构关系,用以指定一个类的对象与另一个类的对象之间存在连接关系。关联关系包括一对一、一对多和多对多关系,在
UML类图中分别用连线和数字标记关联关系和关系的数量。如果两个类之间的关联关系存在方向,则需要使用箭头表示关联的导航方向。如果没有箭头,就表示存在双向关联。例如,用户组
UserGroup与用户User存在双向的关联关系,一个用户组可以包含多个用户,一个用户可以同时属于多个用户组,它们的关系为多对多;用户User与密码Password存在具有导航方向的关联关系,一个用户可以拥有多个密码,密码不能拥有用户,它们的关系为一对多。
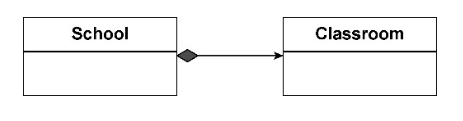
存在一种特殊的关联关系:关联双方分别体现整体与部分的特征,代表整体的对象包含了代表部分的对象。这就是组合关系。依据关系的强弱,组合关系又分为合成( composition) 关系与聚合(aggregation)关系。
a、合成关系(所有权)
合成关系不仅代表了整体与部分的包含关系,还体现了强烈的“所有权” (
ownership) 特征。这种所有权使得二者的生命周期存在一种啮合关系,即组成合成关系的两个对象属于同一个生命周期。当代表整体概念的主对象被销毁时,代表部分概念的从对象也将随之而被销毁。在UML类图中,使用实心的菱形标记合成关系,菱形标记位于代表整体概念的主类一侧。例如,School和Classroom的关系就是合成关系:学校拥有对教室的所有权,学校被销毁了,教室也就不存在了。
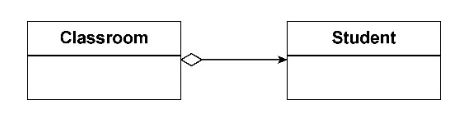
b、聚合关系(无所有权)
聚合关系同样代表了整体和部分的包含关系,却没有所有权特征,不会约束它们的生命周期,故而关联强度要弱于合成关系。在UML类图中,使用空心的菱形标记聚合关系。例如,
Classroom和Student存在聚合关系:教室并未拥有学生的所有权,教室被销毁了,学生依旧存在。
3)依赖关系
依赖关系代表一个类使用了另一个类的信息或服务。依赖关系存在方向,因此在
UML类图中,往往用一个带箭头的虚线线条表示。虚线线条也说明了依赖的双方耦合较弱。依赖关系产生于1、类的方法接收了另一个类的参数;
2、类的方法返回了另一个类的对象;
3、类的方法内部创建了另一个类的实例;
4、类的方法内部使用了另一个类的成员。
2、聚合的定义与特征
聚合:
DDD中的聚合是一个边界,不是对象,它包含了一组相互之间有内在联系的实体和值对象。聚合内部可以包含实体和值对象。聚合根:聚合内包含的实体和值对象形成一棵树,只有实体才能作为这棵树的根。这个根称为聚合根 (
aggregate root),这个实体称为根实体 (root entity)。由于聚合必须选择实体作为根,因此一个最小的聚合就只有一个实体。聚合根是整个聚合的出入口,通过它控制外界对边界内其他对象的访问。在进行领域设计建模时,我们往往以根实体的名称指代整个聚合,如一个聚合的根实体为订单
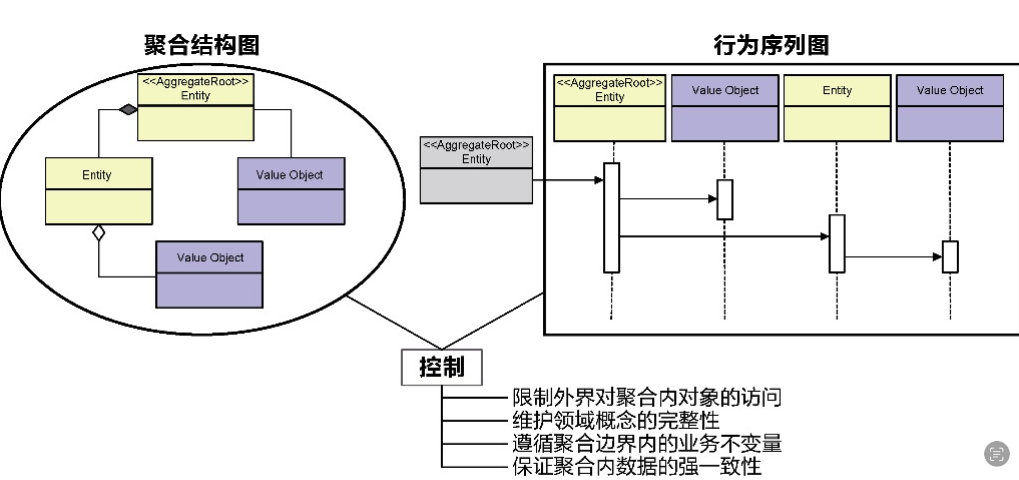
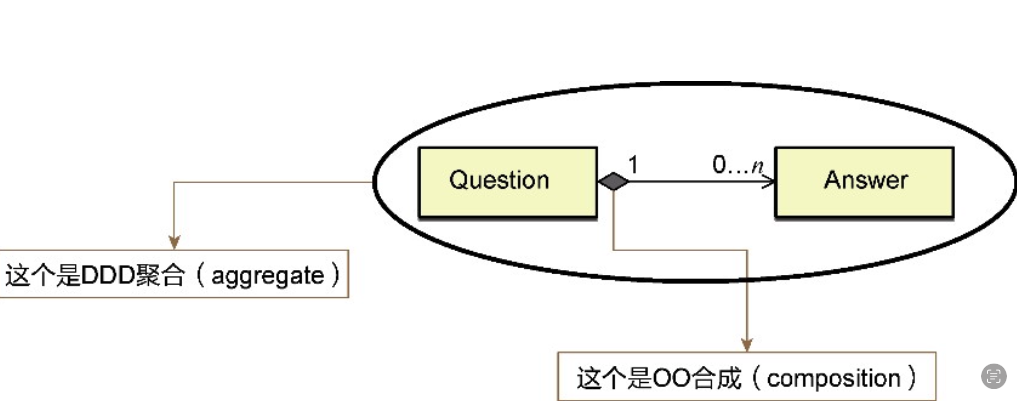
1)OO 聚合 DDD 聚合
OO聚合(面向对象的聚合(objectoriented聚合,OO聚合)OO聚合表示了类与类之间的关联关系(组合关系),体现了整体包含了部分的意义
DDD聚合:DDD聚合表示了一种边界,它的边界内可以只有一个实体对象,也可以包含一些具有关联关系、泛化关系和依赖关系的实体与值对象。
2)聚合的设计原则
引入聚合的目的是通过合理的对象边界 控制对象之间的关系,在边界内保证对象的一致性与完整性,在边界外作为一个整体参与业务行为的协作。
显然,聚合在限界上下文与类的粒度之间形成了中间粒度的封装层次,成为表达领域知识、封装领域逻辑的自治设计单元。它的自治性与限界上下文不同,体现下图示的完整性、独立性、不变量和一致性。
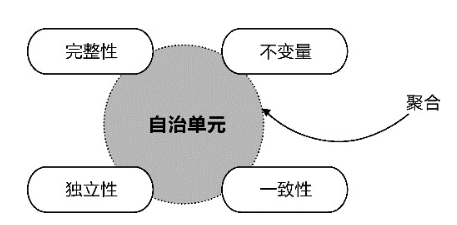
| 特性 | 说明 | 举例 |
|---|---|---|
| 完整性 | 聚合作为一个受到边界控制的领域共同体,对外由聚合根体现为一个统一的概念,对内则管理和维护着高内聚的对象关系。对内与对外具有一致的生命周期。 | 在电商系统中,订单(Order)与订单商品(OrderItem)之间的关系构成了一个聚合。订单作为聚合根,负责管理订单商品的集合。用户不能单独删除订单商品而不影响订单本身,也不能创建一个订单商品而不将其关联到某个订单。这种整体与部分的关系确保了订单聚合的完整性。 |
| 独立性 | 聚合之间的边界是明确的,一个聚合内的变化不应该直接影响到其他聚合。这种独立性有助于降低系统的耦合度,提高系统的可维护性和可扩展性。 | 在订单系统中,订单聚合和库存聚合是两个独立的聚合。订单聚合负责处理订单相关的业务逻辑,如订单的创建、修改和取消等;而库存聚合则负责处理库存相关的业务逻辑,如库存的增减、库存预警等。两个聚合之间通过特定的接口(如事件、消息等)进行通信,但各自的内部状态和业务逻辑保持独立。 |
| 不变量 | 聚合边界内的实体与值对象都是产生数据变化的因子,不变量要在数据发生变化时保证它们之间的关系仍然保持一致 | 在订单系统中,订单的总金额是一个不变量。无论订单中的商品数量、单价或折扣如何变化,订单的总金额都必须根据这些变化重新计算并保持一致。这种不变量要求通过订单聚合内部的业务逻辑来实现,如通过计算订单商品的总价并应用折扣来得出订单的总金额 |
| 一致性 | 聚合需要保证聚合边界内的所有对象满足不变量约束,其中一个最重要的不变量就是一致性约束,因此也可认为一致性是一种特殊的不变量。一致性约束可以理解为事务的一致性,即在事务开始前和事务结束后,数据库的完整性约束没有被破坏 | 在订单系统中,当用户提交订单时,订单聚合需要确保订单中的商品数量不会超过库存聚合中的可用库存量。这种一致性要求通过订单聚合与库存聚合之间的交互来实现,如通过库存检查服务来验证订单的可行性。 |
3)最高原则
领域驱动设计还规定:只有聚合根才是访问聚合边界的唯一入口。这是聚合设计的最高原则。聚合外部的对象不能引用除根实体之外的任何内部对象。
根实体可以把对内部实体的引用传递给它们,但这些对象只能临时使用这些引用,而不能保持引用。根可以把一个值对象的副本传递给另一个对象,而不必关心它发生什么变化,因为它只是一个值,不再与聚合有任何关联
举例:订单聚合外的对象要修改订单项的商品数量,就需要通过获得 Order 聚合根实体,然后通过 Order 操作 OrderItem 对象进行修改。考虑如下代码:”
Order order = orderRepo.orderOf(orderId).get(); //通过资源库获得订单聚合
order.changeItemQuantity(orderItemId, quantity); //调用Order聚合根实体的方法修改内存中的订单项
orderRepo.save(order); //将内存中的修改持久化到数据库
3、聚合生命周期的管理
领域模型对象的主力军是实体与值对象。这些实体与值对象又被聚合统一管理起来,形成一个个具有一致生命周期的“命运共同体”自治单元。
所谓“生命周期”,就是聚合对象从创建开始,在成长过程中经历各种状态的变化,直至最终消亡的过程。在软件系统中,生命周期经历的各种状态取决于存储介质,分为两个层次:内存与硬盘,分别对应对象的实例化与数据的持久化。
从对象的角度看,生命周期代表了一个实例从创建到回收的过程,就像从出生到死亡的生命过程。 而数据记录呢?生命周期的起点是指插入一条新记录,该记录被删除就是生命周期的终点。
领域模型对象的生命周期将对象与数据记录二者结合起来,换言之就是将内存(堆与栈)管理的对象与数据库(持久化)管理的数据记录结合起来,用二者共同表达聚合的整体生命周期”
在领域模型的设计要素中,由聚合根实体的构造函数或者工厂负责聚合的创建,而后对应数据记录的“增删改查”则由资源库进行管理。
如图示,
1、聚合在工厂创建时诞生;
2、为避免内存中的对象丢失,由资源库通过新增操作完成聚合的持久化;
3、若要修改聚合的状态,需通过资源库执行查询,对查询结果进行重建获得聚合;
4、在内存中进行状态变更,然后通过持久化确保聚合对象与数据记录的一致;
5、直到删除了持久化的数据,聚合才真正宣告死亡。
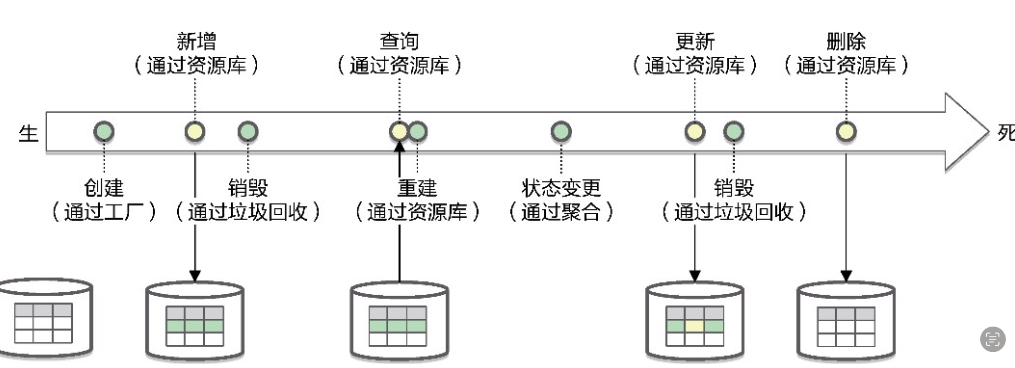
// 创建文章
// 通过Post的工厂方法在内存中创建
Post post = Post.of(title, author, abstract, content);
//持久化到数据库
postRepository.add(post);
// 发布文章
// 根据postId查找数据库的Post,在内存重建Post对象
Post post = postRepository.postOf(postId);
// 内存的操作,内部会改变文章的状态
post.publish();
// 将改变的状态持久化到数据库
postRepository.update(post);
// 删除文章
// 从数据库中删除指定文章
postRepository.remove(postId);”
1)工厂
创建是一种“无中生有”的工作,对应于面向对象编程语言,就是类的实例化。聚合是边界,聚合根则是对外交互的唯一通道,理应承担整个聚合的实例化工作。
若要严格控制聚合的生命周期,可以禁止任何外部对象绕开聚合根直接创建其内部的对象。 在
Java语言中,可以为每个聚合建立一个包 (package),除聚合根之外,聚合内的其他实体和值对象的构造函数皆定义为默认访问修饰符。一个聚合一个包,位于包外的其他类就无法访问这些对象的构造函数。例如Question聚合:
// questioncontext为问题上下文
// question为Question聚合的包名
package com.dddexplained.dddclub.questioncontext.domain.question;
public class Question extends Entity<QuestionId> implements AggregateRoot<Question> {
public Question(String title, String description) {...}
}
// Question聚合内的Answer与聚合根位于同一个包
package com.dddexplained.dddclub.questioncontext.domain.question;
public class Answer {
// 定义为默认访问修饰符,只允许同一个包的类访问
Answer(String... results) {...}
}
许多面向对象语言都支持类通过构造函数创建它自己。说来奇怪,对象自己创建自己,就好像自己扯着自己的头发离开地球表面,完全不合情理,只是开发人员已经习以为常了。**然而,构造函数差劲的表达能力与脆弱的封装能力,在面对复杂的构造逻辑时,显得有些力不从心。遵循“最小知识法则”, **
**1、我们不能让调用者了解太多创建的逻辑,以免加重其负担,并带来创建代码的四处泛滥,何况创建逻辑在未来很有可能发生变化。 **
2、基于以上因素考虑,有必要对创建逻辑进行封装。领域驱动设计引入工厂( factory )承担这一职责
工厂是创建产品对象的一种隐喻。《设计模式:可复用面向对象软件的基础》的创建型模式引入了工厂方法模式、抽象工厂模式和构建者模式,可在封装创建逻辑、保证创建逻辑可扩展的基础上实现产品对象的创建。除此之外,通过定义静态工厂方法创建产品对象的简单工厂模式也因其简单性得到了广泛使用。
领域驱动设计的工厂并不限于使用哪一种设计模式。一个类或者方法只要封装了聚合对象的创建逻辑,都可以被认为是工厂。除了极少数情况需要引入工厂方法模式或抽象工厂模式,主要表现为以下形式:
a、由被依赖聚合担任工厂
领域驱动设计虽然建议引入工厂创建聚合,但并不要求必须引入专门的工厂类,而是可由一个聚合担任另一个聚合的工厂。担任工厂角色的聚合称为 “聚合工厂”,被创建的聚合称为“聚合产品”。
聚合工厂往往由被引用的聚合来承担,如此就可以将自己拥有的信息传给被创建的聚合产品。
例如,Blog 聚合可以作为 Post 聚合的工厂
public class Blog extends Entity<BlogId> implements AggregateRoot<Blog> {
// 工厂方法是一个实例方法,无须再传入BlogId
public Post createPost(String title, String content) {
// 这里的id是Blog的Id
// 通过调用value()方法将id的值传递给Post,建立它与Blog的隐含关联
return new Post(this.id.value(), title, content, this.authorId);
}
}
PostService 领域服务作为调用者,可通过 Blog 聚合创建文章
public class PostService {
private BlogRepository blogRepository;
private PostRepository postRepository;
public void writePost(String blogId, String title, String content) {
Blog blog = blogRepository.blogOf(BlogId.of(blogId));
Post post = blog.createPost(title, content);
postRepository.add(post);
}
}
b、引入专门的聚合工厂
案例1:当创建的聚合属于一个多态的继承体系时,构造函数就无能为力了。
案例2:由于不建议聚合依赖于访问外部资源的端口,引入专门工厂类的另一个好处是可以通过它依赖端口获得创建聚合时必需的值
案例1:航班 Flight 聚合本身形成了一个继承体系。根据进出港标志,可确定该航班针对当前机场究竟为进港航班还是离港航班,从而创建不同的子类。由于子类的构造函数无法封装这一创建逻辑,我们又不能将创建逻辑的判断职责“转嫁”给调用者,就有必要引入专门的FlightFactory 工厂类:
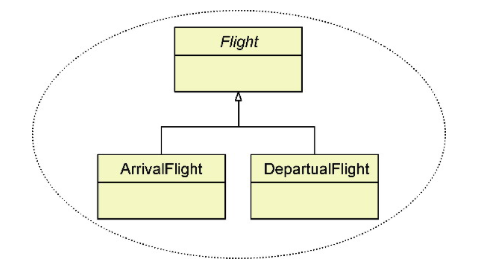
public class FlightFactory {
public static Flight createFlight(String flightId, String ioFlag, String airportCode,
String airlineIATACode...) {
if (ioFlag.equalsIgnoreCase("A")) {
return new ArrivalFlight(flightId, airportCode, airlineIATACode...);
}
return new DepartualFlight(flightId, airportCode, airlineIATACode...);
}
}
举例2:例如,在创建跨境电商平台的商品聚合时,海外商品的价格采用了不同的汇率,在创建商品时,需要将不同的汇率按照当前的汇率牌价统一换算为人民币。汇率换算器 ExchangeRateConverter 需要调用第三方的汇率换算服务,实际上属于商品上下文南向网关的客户端端口。工厂类 ProductFactory 会调用它
⬤ 由于需要通过依赖注入将适配器实现注入工厂类,故而该工厂类定义的工厂方法为实例方法(非静态方法)。
⬤ 为了防止调用者绕开工厂直接实例化聚合,可考虑将聚合根实体的构造函数声明为包范围内限制,并将聚合工厂与聚合产品放在同一个包
public class ProductFactory {
@Autowired
private ExchangeRateConverter converter;
public Product createProduct(String name, String description, Price price...) {
Money valueOfPrice = converter.convert(price.getValue());
return new Product(name, description, new Price(valueOfPrice));
}
}
c、聚合自身担任工厂
聚合产品自身也可以承担工厂角色。这是一种典型的简单工厂模式,例如由
Order类定义静态方法,封装创建自身实例的逻辑⬤ 这一设计方式无须多余的工厂类,创建聚合对象的逻辑也更加严格。由于静态工厂方法属于产品自身,因此可将聚合产品的构造函数定义为私有。调用者除了通过公开的工厂方法获得聚合对象,别无他法可寻。
⬤ 当聚合作为自身实例的工厂时,该工厂方法不必死板地定义为
create××× ()。可以使用诸如of()、instanceOf()等方法名,使得调用代码看起来更加自然⬤ 不只聚合的工厂,对于领域模型中的实体与值对象(包括
ID类),都可以考虑定义这样具有业务含义或提供自然接口的静态工厂方法,使得创建逻辑变得更加合理而贴切
package com.dddexpained.ecommerce.ordercontext.domain.order;
public class Order...
// 定义私有构造函数
private Order(CustomerId customerId, ShippingAddress address, Contact contact, Basket basket) { //... }
public static Order createOrder(CustomerId customerId,
ShippingAddress address,
Contact contact,
Basket basket) {
if (customerId == null || customerId.isEmpty()) {
throw new OrderException("Null or empty customerId.");
}
if (address == null || address.isInvalid()) {
throw new OrderException("Null or invalid address.");
}
if (contact == null || contact.isInvalid()) {
throw new OrderException("Null or invalid contact.");
}
if (basket == null || basket.isInvalid()) {
throw new OrderException("Null or invalid basket.");
}
return new Order(customerId, address, contact, basket);
}
}
d、消息契约模型或装配器担任工厂
设计服务契约时,如果远程服务或应用服务接收到的消息是用于创建的命令请求,则消息契约与领域模型之间的转换操作,实则是聚合的工厂方法。
如果消息契约模型持有的信息不足以创建对应的聚合对象,可以在北向网关层定义专门的装配器,将其作为聚合的工厂。它可以调用南向网关的端口获取创建聚合需要的信息。
例如,买家向目标系统发起提交订单的请求就是创建 Order 聚合的命令请求。该命令请求包含了创建订单需要的客户 ID、配送地址、联系信息、购物清单等信息,这些信息被封装到 PlacingOrderRequest 消息契约模型对象中。响应买家请求的是 OrderController 远程服务,它会将该消息传递给应用服务,再进入领域层发起对聚合的创建。应用服务在调用领域服务时,需要将消息契约模型转换为领域模型,也就是调用消息契约模型的转换方法 toOrder()。它实际上就是创建 Order 聚合的工厂方法:
package com.dddexpained.ecommerce.ordercontext.message;
public class PlacingOrderRequest implements Serializable {
/
/ 创建Order聚合的工厂方法
public Order toOrder() {
...
}
}
public class OrderAppService {
private OrderService orderService;
@Transactional
public void placeOrder(PlacingOrderRequest orderRequest) {
try {
// 通过请求对象创建Order聚合
orderService.placeOrder(orderRequest.toOrder());
} catch (DomainException ex) { ... }
}
}
c、使用构建者组装聚合
聚合作为相对复杂的自治单元,在不同的业务场景可能需要有不同的创建组合。一旦需要多个参数进行组合创建,构造函数或工厂方法的处理方式就会变得很笨拙,需要定义各种接收不同参数的方法响应各种组合方式。构造函数尤为笨拙,毕竟它的方法名是固的。如果构造参数的类型与个数一样,含义却不相同,构造函数更是无能为力。”
风格1:
public class Flight extends Entity<FlightId> implements AggregateRoot<Flight> {
private String flightNo;
private Carrier carrier;
private Airport departureAirport;
private Airport arrivalAirport;
private Gate boardingGate;
private LocalDate flightDate;
public static Builder prepareBuilder(String flightNo) {
return new Builder(flightNo);
}
public static class Builder {
// required fields
private final String flightNo;
// optional fields
private Carrier carrier;
private Airport departureAirport;
private Airport arrivalAirport;
private Gate boardingGate;
private LocalDate flightDate;
private Builder(String flightNo) {
this.flightNo = flightNo;
}
public Builder beCarriedBy(String airlineCode) {
carrier = new Carrier(airlineCode);
return this;
}
public Builder departFrom(String airportCode) {
departureAirport = new Airport(airportCode);
return this;
}
public Builder arriveAt(String airportCode) {
arrivalAirport = new Airport(airportCode);
return this;
}
public Builder boardingOn(String gateNo) {
boardingGate = new Gate(gateNo);
return this;
}
public Builder flyingIn(LocalDate flyingInDate) {
flightDate = flyingInDate;
return this;
}
public Flight build() {
return new Flight(this);
}
}
private Flight(Builder builder) {
flightNo = builder.flightNo;
carrier = builder.carrier;
departureAirport = builder.departureAirport;
arrivalAirport = builder.arrivalAirport;
boardingGate = builder.boardingGate;
flightDate = builder.flightDate;
}
}
客户端可以使用如下的流畅接口创建 Flight 聚合
Flight flight = Flight.prepareBuilder("CA4116")
.beCarriedBy("CA")
.departFrom("PEK")
.arriveAt("CTU")
.boardingOn("C29")
.flyingIn(LocalDate.of(2019, 8, 8))
.build();”
风格2:
相较于第一种风格,它的构建方式更为流畅。从调用者角度看,它没有显式的构建者类,也没有强制要求在构建最后调用
build()方法:
public class Flight extends Entity<FlightId> implements AggregateRoot<Flight> {
private String flightNo;
private Carrier carrier;
private Airport departureAirport;
private Airport arrivalAirport;
private Gate boardingGate;
private LocalDate flightDate;
// 聚合必备的字段要在构造函数的参数中给出
private Flight(String flightNo) {
this.flightNo = flightNo;
}
public static Flight withFlightNo(String flightNo) {
return new Flight(flightNo);
}
public Flight beCarriedBy(String airlineCode) {
this.carrier = new Carrier(airlineCode);
return this;
}
public Flight departFrom(String airportCode) {
this.departureAirport = new Airport(airportCode);
return this;
}
public Flight arriveAt(String airportCode) {
this.arrivalAirport = new Airport(airportCode);
return this;
}
public Flight boardingOn(String gate) {
this.boardingGate = new Gate(gate);
return this;
}
public Flight flyingIn(LocalDate flightDate) {
this.flightDate = flightDate;”
return this;
}
}
Flight flight = Flight.withFlightNo("CA4116")
.beCarriedBy("CA")
.departFrom("PEK")
.arriveAt("CTU")
.boardingOn("C29")
.flyingIn(LocalDate.of(2019, 8, 8));”
2)资源库
资源库 (
repository) 是对数据访问的一种业务抽象。在菱形对称架构中,它是南向网关的端口,可以解耦领域层与外部环境,使领域层变得更为纯粹。资源库可以代表任何可以获取资源的仓库,例如网络或其他硬件环境,而不局限于数据库。领域驱动设计引入资源库,主要目的是管理聚合的生命周期。工厂负责聚合实例的诞生,垃圾回收负责聚合实例的消亡,资源库就负责聚合记录的查询与状态变更,即“增删改查”操作。资源库分离了聚合的领域行为和持久化行为,保证了领域模型对象的业务纯粹性。它和其他端口一起,成为隔离业务复杂度与技术复杂度的关键。
a、一个聚合一个资源库
聚合是领域建模阶段的基本设计单元,因此,管理领域模型对象生命周期的基本单元就是聚合,领域驱动设计规定:一个聚合对应一个资源库。如果要访问聚合内的非根实体,也只能通过资源库获得整个聚合后,将根实体作为入口,在内存中访问封装在聚合边界内的非根实体对象。
问题1:资源库与数据访问对象的区别是什么呢?, 同样都是访问数据,资源库与数据访问对象( data access object,DAO )有何区别呢?
答案:数据访问对象在访问数据时,并无聚合的概念,也就是没有定义聚合的边界约束领域模型对象,使得数据访问对象的操作粒度可以针对领域层的任何模型对象。这就为调用者打开了“方便之门”,使其能够自由自在地操作实体和值对象。没有聚合边界控制的数据访问,会在不经意间破坏领域概念的完整性,突破聚合不变量的约束,也无法保证聚合对象的独立访问与内部数据的一致性。
资源库是完美匹配聚合的设计模式,要管理一个聚合的生命周期,不能绕开资源库。同时,资源库也不能绕开聚合根实体直接操作聚合边界内的其他非根实体。例如,要为订单添加订单项,不能为 OrderItem 定义专门的资源库。
在引入聚合与资源库后,对聚合内部实体的操作,应从对象模型的角度考虑。通过 Order 聚合根的 addItem() 方法实现对订单项的添加,亦可保证订单领域概念的完整性,满足不变量。
总结:资源库与数据访问对象在设计理念、职责范围和应用方式上存在显著差异。资源库更适合于领域驱动设计的场景,而DAO则更适用于传统的数据访问层设计。
b、资源库端口的定义
资源库作为端口,可以视为存取聚合资源的容器。在添加和删除相应类型的对象时,资源库的后台机制负责将对象添加到数据库中,或从数据库中删除对象。提供了对聚合根的整个生命周期的全程访问。
1、通用资源库
public interface Repository<T extends AggregateRoot> {
// 查询
Optional<T> findById(Identity id);
List<T> findAll();
List<T> findAllMatching(Criteria criteria);
boolean contains(T t);
// 新增
void add(T t);
void addAll(Collection<? extends T> entities);
// 更新
void replace(T t);
void replaceAll(Collection<? extends T> entities);
// 删除
void remove(T t);
void removeAll();
void removeAll(Collection<? extends T> entities);
void removeAllMatching(Criteria criteria);
}
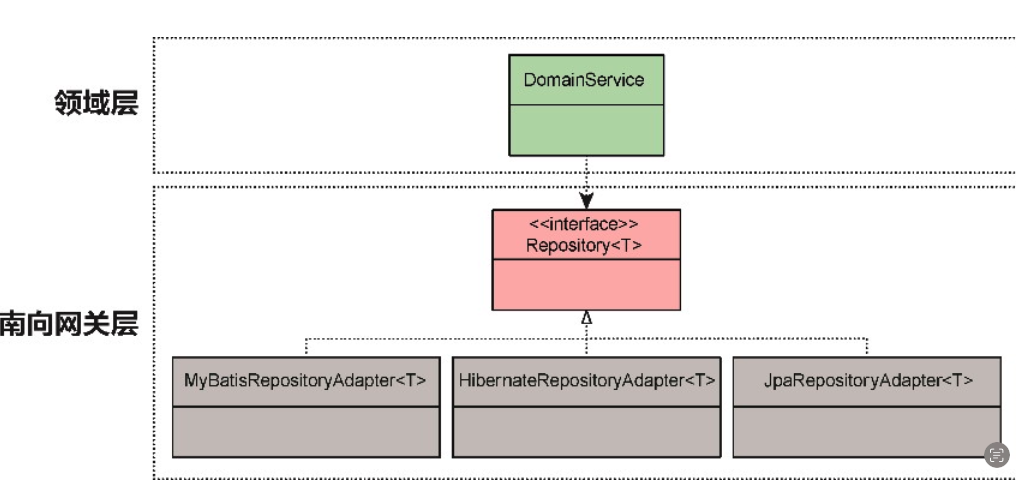
资源库端口定义的接口使用了泛型,泛型约束为 AggregateRoot 类型,它的接口方法涵盖了与聚合生命周期有关的所有“增删改查”操作。理论上,所有聚合的资源库都可以实现该接口,如 Order 聚合的资源库为 Repository<Order> ;。根据 ORM 框架持久化机制的不同,可以为 Repository<T>;接口提供不同的实现,如图
2、通用资源库缺点
⬤ 过于通用的接口无法体现特定的业务需求,并非所有聚合的资源库都愿意拥有大而全的资源库接口方法。例如,Order 聚合不需要删除方法,又或者虽然对外公开为delete() ,内部却按照需求执行了订单状态的变更操作。:
3、私有资源库
虽然通用的资源库接口有种种不足,但它的通用意义与复用价值仍有可取之处。要在复用、封装和代码可读性之间取得平衡,
需将南向网关的端口与适配器视为两个不同的关注点。扮演端口角色的资源库接口面向以聚合为基本自治单元的领域逻辑,扮演适配器角色的资源库实现则面向持久化框架,负责完成整个聚合的生命周期管理。由于通用的资源库接口未体现业务含义,不应视为资源库端口的一部分,需转移到适配器层,被不同的资源库适配器复用。
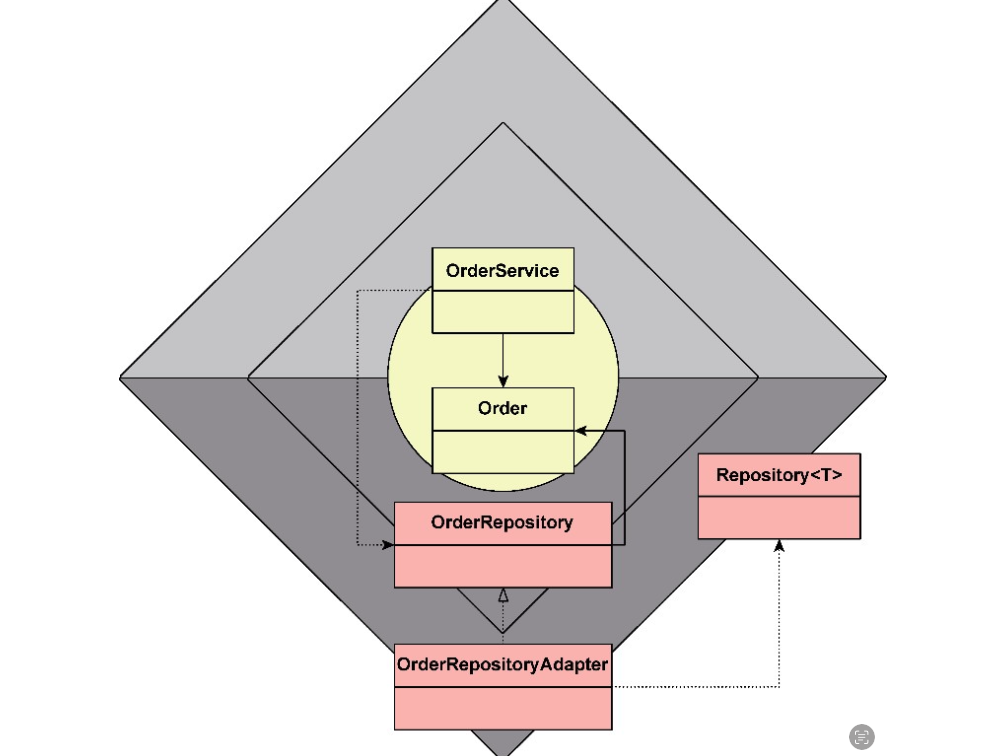
以订单聚合为例。它的资源库端口面向聚合
package com.dddexplained.ecommerce.ordercontext.southbound.port.repository;
public interface OrderRepository {
// 查询方法的命名更加倾向于自然语言,不必体现find的技术含义
Optional<Order> orderOf(OrderId orderId);
// 以下两个方法在内部实现时,需要组装为通用接口的criteria
Collection<Order> allOrdersOfCustomer(CustomerId customerId);
Collection<Order> allInProgressOrdersOfCustomer(CustomerId customerId);
void add(Order order);
void addAll(Iterable<Order> orders);
// 业务上是更新(update),而非替换(replace)
void update(Order order);
void updateAll(Iterable<Order> orders);
// 根据订单的需求,不提供删除方法
}
package com.dddexplained.ecommerce.ordercontext.southbound.adapter.repository;
public class OrderRepositoryAdapter implements OrderRepository {
// 以委派形式复用通用的资源库接口
private Repository<Order, OrderId> repository;
// 注入真正的资源库实现
public OrderRepositoryAdapter(Repository<Order, OrderId> repository) {
this.repository = repository;
}
public Optional<Order> orderOf(OrderId orderId) {
return repository.findById(orderId);
}
public Collection<Order> allOrdersOfCustomer(CustomerId customerId) {
// 封装了组装查询条件的逻辑
Criteria customerIdCriteria = new EquationCriteria("customerId", customerId);
return repository.findAllMatching(customerIdCriteria);
}
public Collection<Order> allInProgressOrdersOfCustomer(CustomerId customerId) {
Criteria customerIdCriteria = new EquationCriteria("customerId", customerId);
Criteria inProgressCriteria = new EquationCriteria("orderStatus",OrderStatus. InProgress);
return repository.findAllMatching(customerIdCriteria.and(inProgressCriteria));
}
public void add(Order order) {
repository.save(order);
}
public void addAll(Collection<Order> orders) {
repository.saveAll(orders);
}
public void update(Order order) {
repository.save(order);
}
public void updateAll(Collection<Order> orders) {
repository.saveAll(orders);
}
}
OrderRepositoryAdapter 适配器注入通用的资源库接口,实际上是将持久化的实现委派给了通用资源库接口的实现类。 可以根据持久化实现机制的要求,将 add() 操作与 replace() 操作合二为一,用 save() 方法代表。接口方法的命名也可以遵循数据库操作的通用叫法,如删除操作仍然命名为 delete(),以下是修改后的资源库通用接口:”
public interface Repository<E extends AggregateRoot, ID extends Identity> {
Optional<E> findById(ID id);
List<E> findAll();
List<E> findAllMatching(Criteria criteria);
boolean exists(ID id);
void save(E entity);
void saveAll(Collection<? extends E> entities);
void delete(E entity);
void deleteAll();
void deleteAll(Collection<? extends E> entities);
void deleteAllMatching(Criteria criteria);
}
四、领域服务
领域服务与实体、值对象一样,表示了领域模型,不过,它并没有代表一个具体的领域概念,而是封装了领域行为,前提是,这一领域行为在实体或值对象中找不到栖身之地。
换言之,当我们针对领域行为建模时,需要优先考虑使用值对象和实体来封装领域行为,只有确定无法寻觅到合适的对象来承担时,才将该行为建模为领域服务的方法。领域服务是领域设计建模的最后选择。
1、领域服务的特征
要求领域服务的名称必须包含动词,体现了领域服务的行为本质。它表达的领域行为应该是无状态的,相当于一个纯函数。只是在
Java语言中,函数并非一等公民”,不得已才定义类或接口作为函数“附身”的类型。”命名约束的实践可能导致太多细粒度的领域服务产生,但在领域层,这样的细粒度设计值得提倡,因为它能促进类的单一职责,保证类的复用和应对变化的能力。由于每个服务的粒度非常细,因此服务就不可能包罗万象。由于服务的定义存在设计成本,因此每当开发人员尝试创建一个新的领域服务时,命命名的约束会让他(她)暂时停下来想一想,分配给这个新服务的领域逻辑是否有更好的去处?
2、领域服务的运用场景
领域服务不只限于对无状态领域行为的建模。在领域设计模型中,它与聚合、资源库等设计要素拥有对等的地位。领域服务的运用场景是有设计诉求的
1)问题1
虽然一些领域行为需要访问聚合封装的信息,它的实现却不稳定,常随着需求的变化发生变化,为了满足领域行为的可扩展性,应该将它分配给哪个对象呢?
样例说明:保险系统常常需要客户填写一系列问卷调查,通过了解客户的具体情况确定符合客户需求的保单策略。调查问卷 Questionaire 是一个聚合根实体,内部由多个处于不同层级的值对象组成了树形结构:
Section ->
SubSection ->
QuestionGroup->
Question->
PrimitiveQuestionField
业务需求要求将一个完整的调查问卷导出为多种形式的文件,这就需要提供转换行为,将一个聚合的值转换为多种不同格式的内容,例如CSV 格式、JSON 格式和 XML 格式。转换行为操作的数据为 Questionaire 聚合所拥有,遵循信息专家模式,该行为代表的职责应由聚合来履行。然而,这一转换行为却存在多种变化,不同的内容格式代表了不同的实现。显然,该行为的变化原因与调查问卷的结构无关,需要将转换行为从 Questionaire 聚合分开,建立一个抽象的接口 QuestionaireTransformer ,为其提供不同的实现,如图”
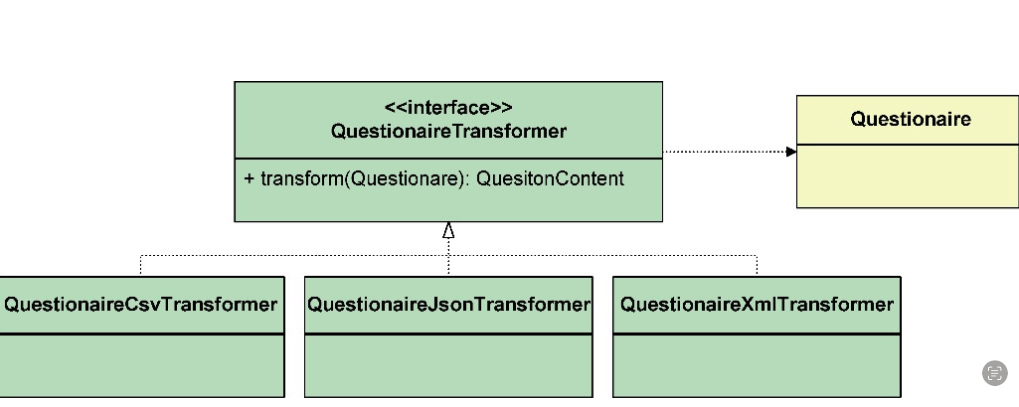
整个 QuestionaireTransformer 继承体系都可以认为是领域服务。从 Questionaire 中分离出 QuestionaireTransformer 也符合单一职责原则,根据变化的原因进行分离
2)问题2
两个聚合之间的协作该由谁负责发起?
多数时候,一个自治的聚合无法完成一个完整的业务服务,聚合之间需要协作。协作通常采用职责委派,即一个聚合的根实体作为参数传递给另一个聚合根实体的方法,完成行为的协作。这是面向对象设计最为自然的协作方式
例如,付款记录聚合 OrderSettlement 与支付约定聚合 PayAggreement 都在支付上下文中,在计算 OrderSettlement 实体的支付金额时,需要 PayAggreement 实体计算获得的支付利率。因此,可在 OrderSettlement 根实体的 payAmountFor() 方法中,传入PayAgreement 对象:
public class OrderSettlement {
public BigDecimal payAmountFor(PayAgreement agreement) {
return orderAmount.multiply(agreement.actualPayRate());
}
}
public class PayAgreement {
public BigDecimal actualPayRate() {
return new BigDecimal(payRate * 0.01);
}
}
⬤ 聚合的生命周期由资源库管理,故而在两个聚合的协作行为之上,需要引入一个设计对象负责聚合的协作。这正是领域服务需要承担的职责,引入的领域服务调用资源库获得聚合,发起它们之间的行为协作。例如,引入 PayAmountCalculator 领域服务,对外提供计算支付金额的领域行为,在方法内部通过资源库端口获得彼此协作的聚合,调用它们的协作方法:”
public class PayAmountCalculator {
private OrderSettlementRepository orderSettlementRepo;
private PayAggreementRepository payAggreementRepo;
public BigDecimal calculatePayAmount(OrderSettlementId orderSettlementId) {
BigDecimal defaultPayAmount = new BigDecimal(0);
Optional<OrderSettlement> optOrderSettlement = orderSettlementRepo
.orderSettlementOf(orderSettlementId));
if (!optOrderSettlement.isPresent()) {
return defaultPayAmount;
}
OrderSettlement orderSettlement = optOrderSettlement.get();
PayAggreementId payAggreementId = PayAggreementId.of(orderSettlement.payAggreementId());
Optional<PayAggreement> optPayAggreement = payAggreementRepo.payAggreementOf(payAggreementId);
if (!optPayAggreement.isPresent()) {
return defaultPayAmount;
}
PayAggreement payAggreement = optPayAggreement.get();
// 注意,聚合之间产生了协作,但协作关系是纯粹的业务职责
return orderSettlement.payAmountFor(payAggreement);
}
}
问题:为何不让聚合直接调用资源库端口获得另一个聚合呢?
答案:资源库的职责是管理聚合的生命周期,如果在聚合内部又使用了资源库端口,意味着资源库在“重建”聚合根对象时,还需要将该聚合根对象依赖的资源库适配器对象提供给它。这就好像蛋生鸡、鸡生蛋,可能陷入对象循环创建的怪圈。
3)问题3
如果聚合不知道端口的存在,那么业务行为与南向网关端口的协作,该由谁来负责呢?
如果领域行为突破了聚合的粒度,就需要与外部资源间的协作。在菱形对称架构中,这就意味着需要调用南向网关的端口。这一职责交由领域服务来承担。
样例:一个典型的例子是对订单的验证。如果仅仅需要验证订单的信息是否完整,订单聚合自己就能做到,验证行为就可以分配给 Order 聚合。倘若除了验证订单信息,还要验证所购商品的库存量是否满足购买需求,就需要访问库存上下文的远程服务。对 Order 聚合所在的订单上下文而言,库存上下文属于外部环境,需要通过南向网关的客户端端口访问。这时,验证订单整体有效性的领域行为就该交给 OrderValidator 领域服务:”
public class OrderValidator {
private InventoryClient inventoryClient;
public void validate(Order order) {
order.validate();
InventoryReview inventoryReview = inventoryClient.check(order);
if (!inventoryReview.isAvailable()) {
throw new NotEnoughInventoryException();
}
}
}
菱形对称架构也将资源库视为南向网关的一种端口,因此,领域服务对第三个问题的应对,同时也解决了第二个问题。由此可以确定聚合设计的一条原则:不要在聚合内部引入对南向网关端口的依赖。
既然领域服务可以直接依赖南向网关端口,在协调和控制多个聚合对象时,就可以让服务方法变得更简单,甚至让调用者体会不到聚合的存在。
例如,银行的转账服务发生在两个相同类型的聚合对象之间,即转出账户和转入账户,它们都是 Account 类型的聚合根实体对象。由于 TransferingService 可以通过 AccountRepository 获得 Account 聚合对象,转账服务方法只需传递转出账户与转入账户的 ID 以及转账金额即可:
public class TransferingService {
private AccountRepository accountRepo;
private TransactionRepository transactionRepo;
public void transfer(AccountId sourceAccountId, AccountId targetAccountId, Moneyamount) {
SourceAccount sourceAccount = accountRepo.accountOf(sourceAccountId);
TargetAccount targetAccount = accountRepo.accountOf(targetAccountId);
// 账户余额是否大于amount值,由Account聚合负责
Transaction transaction = sourceAccount.transferTo(targetAccount, amount);
accountRepo.save(sourceAccount);
accountRepo.save(targetAccount);
transactionRepo.save(transaction);
}
}
public class Account extends Entity<AccountId> implements
AggregateRoot<Account>, SourceAccount, TargetAccount {
private final const TRANSFERING_THRESHOLD = new BigDecimal(10000);
private Money balance;
public Account(AccountId accountId, Money balance) {
this.id = accountId;
this.balance = balance;
}
@Override
public Transaction transferTo(TargetAccount target, Money transferAmount) {
if (transferAmount.greaterThan(balance)) {
throw new InsufficientFundsException("Insufficientfunds.");
}
if (amount.greaterThan(TRANSFERING_THRESHOLD)) {
throw new AccountException("Amount can not ..."));
}
decrease(transferAmount);
target.transferMoneyFrom(transferAmount);
return Transaction.createTransferingTransaction(accountId, target.getAccountId(),amount);
}
@Override
public void transferFrom(Money transferAmount) {
increase(transferAmount);
}
private void increase(Money amount) {
balance.add(amount);
}
private void decrease(Money amount) {
balance.subtract(amount);
}
}
3、领域服务、聚合、端口协作
领域服务、端口和聚合非常默契地履行各自的职责:
⬤ 聚合操作 属于它以及它边界内的数据,履行自治的领域行为;
⬤ 端口通过适配器封装与外部环境交互的行为,又通过抽象隔离对具体技术实现的依赖;
⬤ 领域服务对外提供完整的业务功能,对内负责聚合和端口之间的协调。它们的协作机制如图所示。
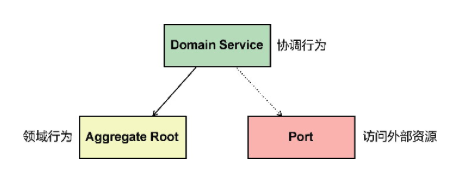
在所有领域模型设计要素中,领域服务的定义最为自由。正因如此,才需要限制它的自由度,明确聚合与领域服务各自的职责差异,确定领域设计建模的优先级。应优先分配领域逻辑给聚合,只有聚合无法做到的,才会考虑分配给领域服务。
哪些领域逻辑是聚合无法做到的呢?根据前面的分析,可以归纳为:
1、与状态无关的领域行为;
2、变化方向与聚合不一致的领域行为;
3、聚合之间协作的领域行为”
4、聚合和端口之间协作的领域行为。
五、领域事件
1、领域事件的定义
定义:领域事件是领域模型中极其重要的部分,用来表示领域中发生的事件。它主要关注领域行为引起的领域概念状态的变化,而不是单纯的领域概念或行为本身。领域事件表达了实体的状态变更和迁移,属于领域设计模型中的领域概念
领域事件的命名必须清晰地传递领域概念。这意味着需要在统一语言指导下,从业务的角度命名。作为已经发生的事实,事件的命名应采用动词的过去时态,如订单完成的事件命名为
OrderCompleted。这一命名方式也是领域事件推荐的命名风格,我们无须再为其增加Event后缀。作为不变事实的领域事件可以参考值对象的定义要求,定义为不变类。与值对象不同的是,事件的发布者与消费者在使用事件时,都通过事件的
ID进行管理,因此它又具有实体的特征,需要定义代表身份唯一标识的ID属性。领域事件的ID没有任何业务含义,可定义为通用类型的身份标识。领域事件总是随着某个条件的满足而被触发,为了更好地记录和跟踪该事件,还需要保留该事件发生时的时间戳。领域事件不同于领域模型设计要素的其他模型对象。为了体现这一差异,也为了抽象领域内的所有领域事件,可以统一定义一个抽象类
DomainEvent。
public abstract class DomainEvent {
protected final String eventId;
protected final String occurredOn;
public DomainEvent() {
eventId = UUID.randomUUID().toString();
occurredOn = new Timestamp(new Date().getTime()).toString();
}
}
领域事件只需要封装发布者希望传递的信息。当然,在定义事件属性时也需要考虑订阅者的需求,如转账成功事件 TransferSucceeded 本身足以说明转账的成功完成状态,但为了使订阅者在收到该事件后能够生成转账交易记录,需要在创建该事件时将转出方与转入方的账户 ID 、转账金额封装进去:
public class TransferSucceeded extends DomainEvent {
private final AccountId srcAccountId;
private final AccountId targetAccountId;
private final Money amount;
public TransferSucceeded(AccountId srcAccountId, AccountId targetAccountId, Money amount) {
super();
this.srcAccountId = srcAccountId;
this.targetAccountId = targetAccountId;
this.amount = amount;
}
}
2、对象建模范式的领域事件
倘若依然采用对象建模范式定义领域事件,那么作为一种领域模型设计要素,它实际上只是实体、值对象和领域服务的一个重要补充。引入它的首要目的是更好地跟踪实体状态的变更,并在状态发生变更时,通过事件消息的通知完成领域模型对象之间的协作。在收到状态变更的事件时,参与协作的对象需要依据当前实体的状态变更决定该做出怎样的响应。这实则是对象协作的需求,只不过协作的方式发生了改变。
事件对状态变更的通知符合观察者模式的设计思路。该模式定义了主体(
subject)对象与观察者(observer)对象。一个主体对象可以注册多个观察者对象,观察者对象则定义了一个回调函数。一旦主体对象的状态发生变化,调用回调函数就将变化的状态通知给所有的观察者。主体和观察者都进行了抽象,以降低二者之间的耦合。观察者模式的设计类图如图所示。”
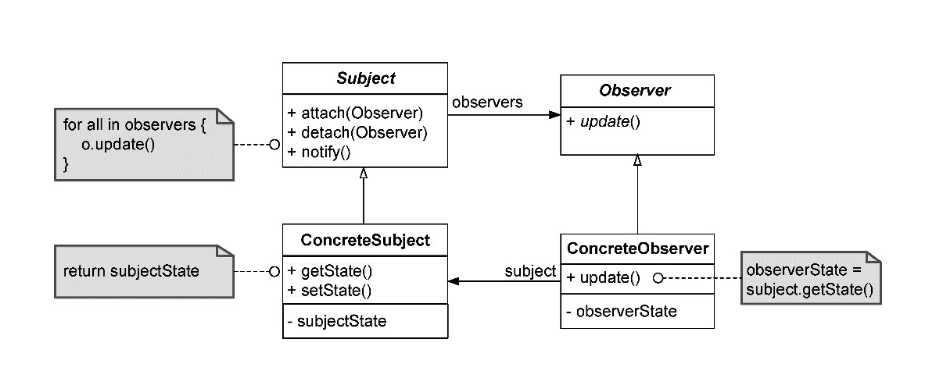
以客户转账的业务服务为例。在没有使用领域事件之前,TransferingService 转账服务的内部在转账成功后调用TransactionRepository 生成一条转账交易记录。改由领域事件后,TransferingService 转账服务在转账成功后,就可发布TransferSucceeded 领域事件。事件发布完毕,转账流程也就宣告结束。处理该领域事件的对象为订阅者,不同业务场景对于TransferSucceeded 事件的处理逻辑并不相同。交易服务 TransactionService 会生成转账记录,通知服务 NotificationService 会发送通知短信。在发布事件后,为了通知订阅者,需要发布者注册这些订阅者。由于可能存在多个订阅者,因此需要为订阅者定义抽象的接口
public interface TransferingEventSubscriber {
void handle(TransferSucceeded transferedSucceededEvent);
void handle(TransferFailedd transferedFailedEvent);
}
转账服务修改为:
public class TransferingService {
private AccountRepository accountRepo;
private TransactionRepository transactionRepo; //不需要操作交易聚合,删去
private List subscribers;
public TransferingService() {
subscribers = new ArrayList<>();
}
// 相当于注册观察者
public void register(TransferingEventSubscriber subscriber) {
if (subscriber != null) {
this.subscribers.add(subscriber);
}
}
public void transfer(AccountId sourceAccountId, AccountId targetAccountId, Money amount) {
try {
SourceAccount sourceAccount = accountRepo.accountOf(sourceAccountId);
TargetAccount targetAccount = accountRepo.accountOf(targetAccountId);”
// 账户余额是否大于amount值,由Account聚合负责
sourceAccount.transferTo(targetAccount, amount);
accountRepo.save(sourceAccount);
accountRepo.save(targetAccount);
TransferSucceeded succeededEvent = new TransferSucceed(sourceAccountId, targetAccountId, amount);
publish(succeededEvent);
} catch (DomainException ex) {
TransferFailed failedEvent = new TransferFailed(sourceAccountId,
targetAccountId,
amount,
ex.getMessage());
publish(failedEvent);
}
}
private void publish(TransferSucceeded succeededEvent) {
for (TransferingEventSubscriber subscriber : subscribers) {
subscriber.handle(succeededEvent);
}
}
private void publish(TransferFailed failedEvent) {
for (TransferingEventSubscriber subscriber : subscribers) {
subscriber.handle(failedEvent);
}
}
}
TransactionService 领域服务负责生成转账交易记录,是事件的订阅者
public class TransactionService implements TransferingEventSubsriber {
private TransactionRepository transactionRepo;
@Override
public void handle(TransferSucceeded succeededEvent) {
Transaction transaction = Transaction.createTransferingTransaction(succeeded
Event.getSourceAccountId(),
succeededEvent.getTargetAccountId(),
succeededEvent.getAmount());
transactionRepo.save(transaction);
}
}
3、总结
领域事件属于领域层的领域模型对象。如果事件参与了限界上下文之间的协作,应考虑定义应用事件,作为包裹在领域层之外的消息契约。
无论是同一个限界上下文内聚合之间传递领域事件,还是跨限界上下文传递应用事件,甚至跨进程边界(当限界上下文作为微服务边界时)传递应用事件,都符合发布-订阅模式的语义,事件的传递都由事件总线负责。事件总线是一种抽象,既可以实现为本地的事件消息通信(如
Guava提供的Event Bus库),也可以由消息队列或消息中间件担任(如Kafka、RabbitMQ、RocketMQ等)。不同框架的选择可能在一定程度影响领域模型对领域事件的操作。若严格遵循菱形对称架构,就可定义一个抽象的
EventBus接口作为南向网关的端口,由它来隔离这些具体的技术实现因素对领域模型的影响。。
六、角色构造型
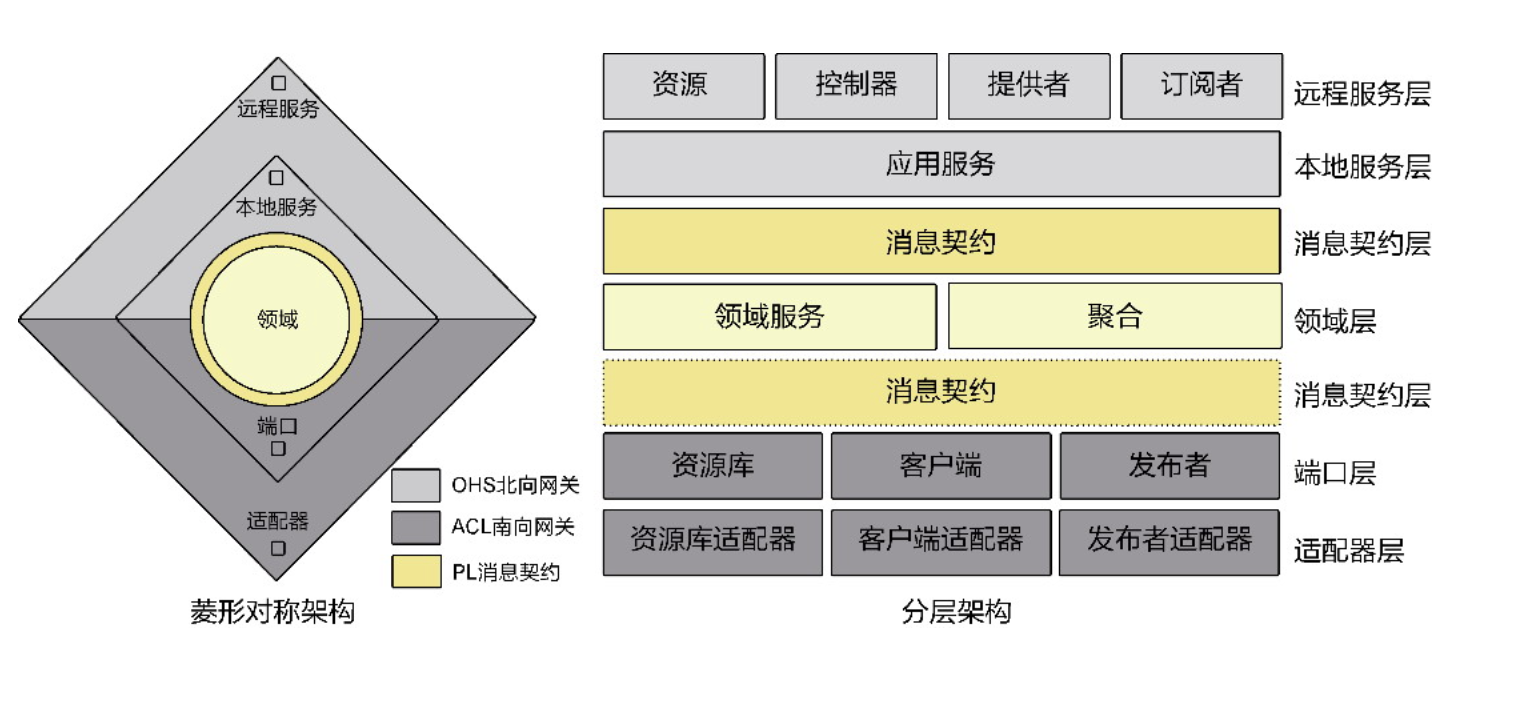
1、领域驱动设计的角色构造型
远程服务:若为当前限界上下文的远程服务,则负责响应角色的服务请求;若为上游限界上下文的远程服务,则响应客户端适配器的调用请求。
应用服务:与远程服务对应,提供具有服务价值的服务接口,完成消息契约对象与领域模型对象的转换,调用或编排领域服务。
领域服务:提供聚合无法完成的业务功能,协调多个聚合以及聚合与端口之间的协作。
聚合:作为信息的持有者,履行自给自足的领域行为,内部实体与值对象之间的协作被聚合边界隐藏起来。
工厂:封装复杂或可能变化的创建聚合的逻辑。
端口:作为访问外部资源的抽象。常见端口包括对访问数据库的抽象,定义为资源库端口;对调用第三方服务包括上游限界上下文的抽象,定义为客户端端口;对发布事件到事件总线的抽象,定义为发布者端口。
适配器:端口的实现,提供访问外部资源的具体技术实现,并通过依赖注入设置到领域服务或应用服务中。
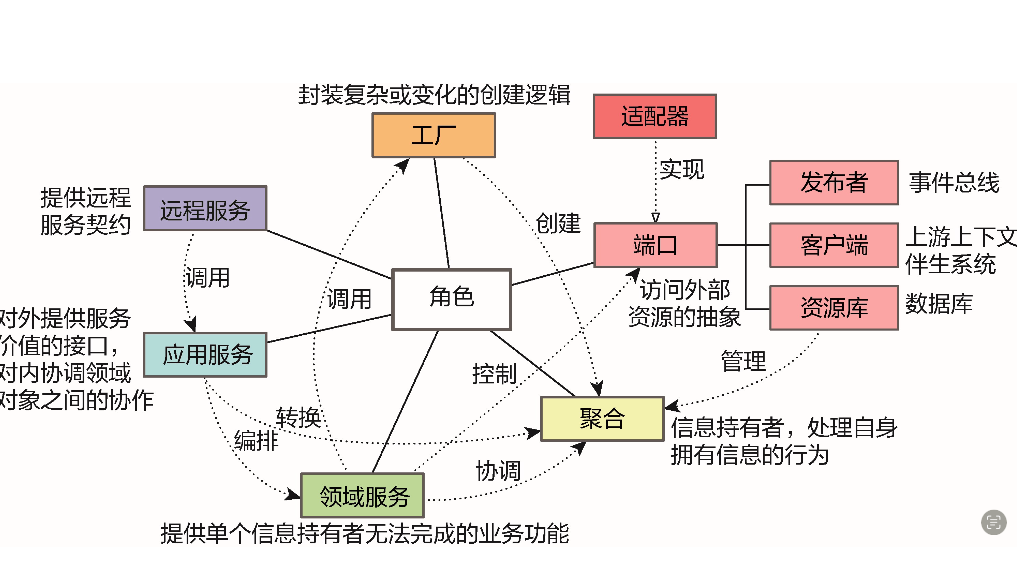
2、角色构造型的协作模式
⬤ 远程服务与应用服务: 体现了最小知识法则,保证远程服务的单一职责
⬤ 应用服务与领域服务: 由领域服务封装领域逻辑,以避免其泄露到应用层。
⬤ 应用服务与端口: 应用服务可以与端口协作,用于访问外部资源。
⬤ 应用服务与工厂: 只限于消息契约对象或装配器担任聚合工厂的场景。
⬤ 应用服务与聚合: 应用服务在调用领域服务时,需要获得聚合,为了避免领域知识的泄露,不建议应用服务直接调用聚合实体和值对象的领域行为,对外,也必须将聚合转换为消息契约对象。
⬤ 领域服务与工厂、端口和聚合: 确保了领域逻辑的职责分配,避免领域服务成为事务脚本。
⬤ 聚合: 聚合只能与聚合协作,不知道其他角色构造型,保证了聚合的稳定性和纯粹性。
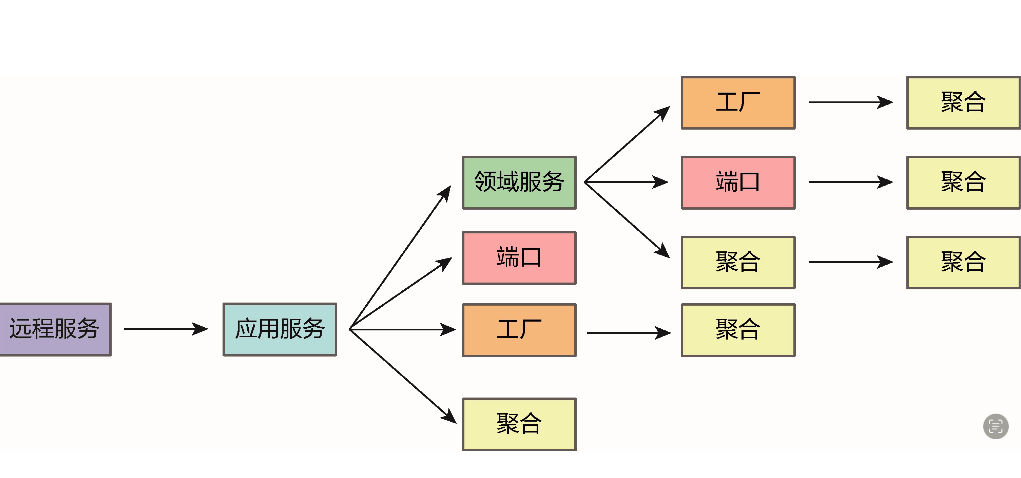
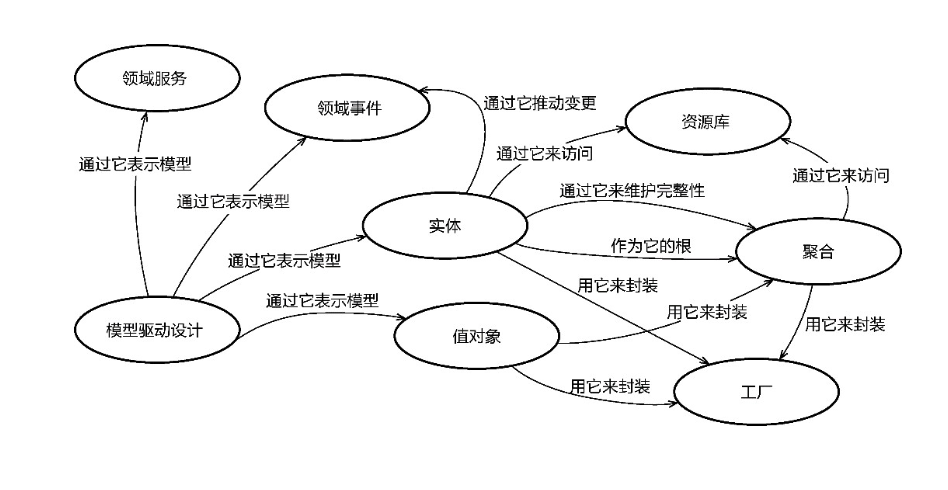
一、总结
设计元模型规定:只能由实体、值对象、领域服务和领域事件表示模型,如此即可避免将领域逻辑泄露到领域层外的其他地方
例如菱形对称架构的外部网关层。聚合用于封装实体和值对象,并维持自己边界内所有对象的完整性。
要访问聚合,只能通过聚合根的资源库,这就隐式地划定了边界和入口,有效控制了聚合内所有类型的领域对象。若聚合的创建逻辑较为复杂或存在可变性,可引入工厂来创建聚合内的领域对象。若牵涉到实体的状态变更,领域元模型建议通过领域事件来推动。 战术设计元模型的各种模式与模型元素优雅地解决了理想对象模型存在的问题。”
问题1:领域模型对象如何实现数据的持久化?
答案:资源库模式隔离了领域逻辑与数据库实现,并将领域模型对象当作生命周期管理的资源,将持久化领域对象的介质抽象为资源库。
问题2:领域模型对象的加载以及对象间的关系该如何处理?
答案:领域驱动设计引入聚合划分领域模型对象的边界,并在边界内管理所有领域模型对象之间的关系,使其在对象的协作与完整性之间取得平衡。
问题3:领域模型对象在身份上是否存在明确的差别?
答案:领域驱动设计使用实体与值对象区分领域模型对象的身份,避免了不必要的身份跟踪与额外的并发控制要求。
问题4:领域模型对象彼此之间如何能弱依赖地完成状态的变更通知?
答案:领域驱动设计引入了领域事件,通过发布与订阅领域事件解除聚合与聚合之间的依赖,体现状态变迁的特性。

