索引高度回顾
前言
Github:https://github.com/HealerJean
1、B+ 树的高度计算
1.1、通过记录总数推导树的高度
表的记录数是N, 每一个BTREE节点平均有B个索引KEY,那么B+TREE索引树的高度就是 logNB (等价于 logN / logB )
由于索引树每个节点的大小固定,所以索引 KEY 越小,B 索引数量就越大,那么每个 BTREE 节点上可以保存更多的索引KEY,也就是B值越大,索引树的高度就越小,那么基于索引的查询的性能就越高。所以相同表记录数的情况下,索引KEY越小,索引树的高度就越小。
通过上面的计算可知,要计一张表索引树的高度,只需要知道一个节点有多大空间,从而就能知道每个节点能存储多少个索引 KEY。现代数据库经过不断的探索和优化,并结合磁盘的预读特点,每个索引节点一般都是操作系统页的整数倍,操作系统页可通过命令得到该值得大小,且一般是 4094 ,即 4k 。
InnoDB 的 pageSize 可以通过命令得到,默认值是 16k(我们小米数据库就是16k 默认的)。1k = 1024 个字节 (如果在创建MySQL实例时通过指定 innodb_page_size 选项将 InnoDB页面大小减少到 8KB 或 4KB,索引键的最大长度将按比例降低,这是基于 16KB 页面大小的 3072 字节限制。也就是说,当页面大小为 8KB 时,最大索引键长度为 1536 字节,而当页面大小为4KB时,最大索引键长度为768 字节。)
mysql> show variables like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
索引树上每个节点除了存储 KEY,还需要存储指针。所以每个节点保存的 KEY 的数量为 pagesize/ (keysize + pointsize )
以 bigint为例,存储大小为 8 个字节。INT 存储大小为 4 个字节( 32 位)
假设平均指针大小是4个字节,那么索引树的每个节点可以存储 16 k / ( ( 8 + 4 ) * 8 ) ≈ 171。那么:一个拥有3000w (2^25=33554432)数据,且主键是BIGINT类型的表的主键索引树的高度就是 (log 2^25 ) / log171 ≈ 25/7.4 ≈ 3.38。
假设平均指针大小是8个字节,那么索引树的每个节点可以存储16k /( (8 + 8 ) * 8 ) ≈ 128。那么:一个拥有 3000w ( 2 ^ 25 = 33554432)数据,且主键是 BIGINT 类型的表的主键索引树的高度就是( log2 ^ 25 ) /log128 ≈ 25/7 ≈ 3.57
由上面的计算可知:一个千万量级,且存储引擎是 MyISAM 或者 InnoDB 的表,其索引树的高度在3~5之间。
1.2、通过树的高度推导记录总数
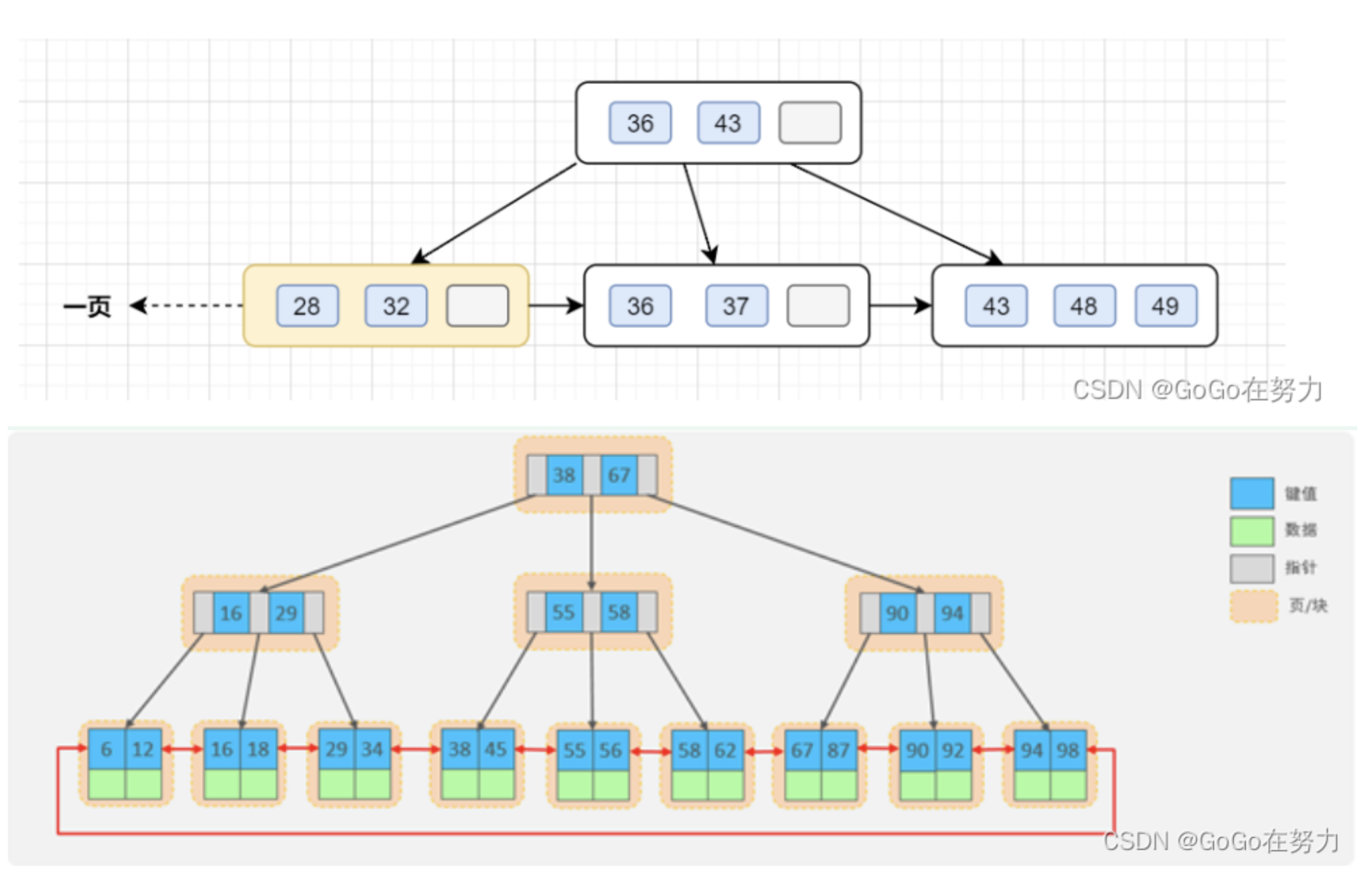
InnoDB存储引擎最小储存单元是页,一页大小就是16k。
B+树叶子存的是数据,内部节点存的是 键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据;
假设 B+ 树的高度为 2 的话,即有一个根结点和若干个叶子结点。这棵 B+ 树的存放总记录数为 = 根结点指针数 * 单个叶子节点记录行数
假设一行记录的数据大小为 1k ,那么单个叶子节点可以存的记录数 = 16k / 1k = 16
非叶子节点内存放多少指针呢?我们假设主键 ID 为 bigint 类型,长度为 8 字节( int 类型的话,一个 int 就是 32 位,4 字节),而指针大小是固定的在InnoDB 源码中设置为6字节
假设 n 指主键个数即 key 的个数, n * 8 + (n + 1) * 6 = 16K=16 * 1024B , 算出 n 约为 1170 ,意味着根节点会有 1170 个 key 与 1171 个指针、因此,一棵高度为 2 的 B+ 树,能存放 1171 * 16 = 18736 条这样的数据记录。
同理一棵高度为 3 的 B+ 树,能存放 1171 * 1171 * 16 = 21939856,也就是说,可以存放两千万左右的记录。B+树高度一般为1-3层,已经满足千万级别的数据存储。